

Why use persistent storage for persistent queueing? Well, the short answer is in the name. Generally, if you’re using persistent queues to manage backpressure, you are doing so to avoid either blocking, or event drops, when your destination experiences trouble. You want your data to persist across any problems you might have in the worker group, so you generally don’t want to use ephemeral storage for the queueing.
The Cribl Stream helm charts, as of our April 2021 release, provides key capabilities: While we had started by defining, effectively, a reference architecture for Stream on Stream (K8s), the latest versions enable our customers to get creative with their deployments. We introduced all sorts of “extra” configuration options that allow people to inject configuration into their deployment. Combining a few of those in a logstream-workergroup implementation allows you to do persistent queueing on top of K8s persistent volumes. We caution in the README that great care is taken when doing this, especially with the K8s persistence layer, and I think it’s worth expanding upon that a bit and exploring the use case and how to avoid potential pitfalls.
First, the caution comes from our own experiences using AWS EKS with the CSI drivers for EBS and EFS storage providers. Kubernetes (K8s) excels at hosting stateless or ephemeral workloads, but the persistence story for K8s has been evolving. Early on, we definitely had challenges with the CSI drivers, but many of those were due to incomplete understanding. It’s easy to follow the directions on a website to deploy something in K8s, but it’s another thing to completely understand how that workload operates within your K8s environment. After having run our demo environments in EKS for the last 5 months, I’ve got a much deeper understanding of how the charts run, and moreover, the “gotchas” of the different persistent storage drivers.
For example, using the EBS CSI driver on a logstream-leader release requires understanding the network topology of your EKS cluster and the EBS service. It took a number of “hey, the demo environment is down” moments to realize that the cluster was set up to span all availability zones (AZs) in the region; EBS volumes can be mounted only on systems in the same AZ where the volume was created. So when we had a node go down that had a logstream-leader on it, if there wasn’t another node available in the same AZ, the pod would not get rescheduled. There’s a fairly simple fix–- create nodegroups that are AZ-specific, meaning that if a node in one AZ dies, you can expect to get a replacement node in that AZ. Another challenge is that it seems to take a little while for EBS to realize that the “dead” node is no longer using the volume, so there is a time period during which the replacement pod cannot be scheduled – it’s short, but important to be aware of.
This is not to complain about EKS, or the CSI drivers, or any of that. The point is that the deeper the understanding I had of the environment, the more I’d be able to work around limitations, and the more stable my environment becomes.
Now, turning to the worker group chart and the idea of using persistent storage as the backing store for persistent queues, this theme continues. It’s extremely important that operators understand the idiosyncrasies in their cluster, and especially its persistence layer. For example, in the EKS world, my most-likely options for persistence are EBS and EFS. EBS is effectively block storage, and can be mounted only by a single pod at any time. This makes it a good option for something like the configuration volume on a Stream leader deployment – there’s only ever one of them in the environment. EFS, on the other hand is an NFS-based service. It can therefore be mounted on multiple pods simultaneously, and if set up correctly, on any AZ in which your cluster has a node. This makes it a good *shared* solution for any workload that is, say, autoscaling.
If you’re asking “why do I need a shared storage solution?” Primarily for autoscaling. If you’re using the extraVolumeMounts option, you have to specify *all* the volumes you need, and they all need to be mounted on all of the worker pods. That’s just not feasible to do with a non-shared solution.
Implementation Thoughts
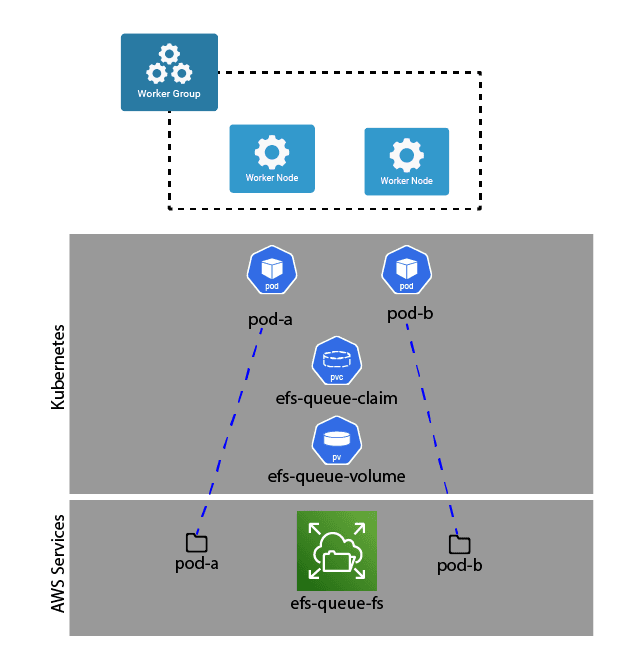
In the case of the diagram, there is a single shared volume (EFS in this case) that is to be mounted by all of the worker nodes. If you want to know how to set up that EFS volume, AWS has a great how-to here. Each Stream persistent queue needs to be in its own directory, so we can use a combination of the envFrom option (exposing values via the downward API) and the extraVolumeMounts SubPathExpr attribute in the values file, like this excerpt:
envValueFrom:
- name: PODNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
extraVolumeMounts:
- name: efs-queue-volume
mountPath: /opt/cribl/queues
existingClaim: efs-queue-volume
subPathExpr: $(PODNAME)
readOnly: falseThe envValueFrom definition creates the environment variable envValueFrom, containing the name of the running pod (metadata.name). The extraVolumeMounts section tells the pod how to mount the EFS volume. Without the subPathExpr attribute, this would mount the efs-queue-volume directly as /opt/cribl/queues. However, the subPathExpr references the PODNAME environment variable, which tells the pod to mount that subdirectory on the specified mountPath. So in this case, if our pod name is cribl-worker-ef435222, it would mount the cribl-worker-ef435222 subdirectory (creating it if it doesn’t already exist) on /opt/cribl/queues.
This allows setting the queue path to something relative to /opt/cribl/queues, and having it be consistent across all of the workers, but still maintaining a separate directory for each worker.
Recovery Challenge
The downside to this setup is that in the event of a pod dying, you’re left with a directory for the dead pod, which may or may not contain queued data. You will have to have some sort of process to spin up a new pod that statically mounts the old pod’s directory, delivering the data stored in it. This could be as simple as deploying an additional copy of the worker group Helm chart with autoscaling turned off, and instead of using the subPathExpr, specifying the old pod name as a subPath attribute. Something like this excerpt:
extraVolumeMounts:
- name: efs-queue-volume
mountPath: /opt/cribl/queues
existingClaim: efs-queue-volume
subPathExpr: cribl-worker-ef435222
readOnly: false
autoscaling:
enabled: falseProceed With Caution
As you can see, this use case is definitely achievable with the Helm charts. The caution we encourage here is really focused on having a good working knowledge of your K8s cluster’s persistence layer; this should be tested heavily in non-production before you consider deploying it in production. If you’re interested in this approach, or in the Helm charts in general, please see our Helm charts repository
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.





