
The need for operational & performance visibility grows at least linearly with your infrastucutre sprawl; The more data your VMs, containers, APIs, apps, services, users, etc. emit, the greater the impact on the performance and the user experience of the analysis system. In theory this problem is easy to solve; simply scale the analysis system at the same rate as the infrastructure. But practice is a bitch and will throw multiple wrenches at that idea – wrenches of the economic, political, compliance, storage and staffing type. Half of the customers that we’ve spoken with, when faced with high volume/low value data, do either of the following, or a combination of both:
1. Limit/Omit: Don’t index it at all (or dump it in cheap storage for later analysis).2. Summarize: Spin up additional infrastructure and bring in aggregates.
Is there a way to use existing infrastructure to derive some amount of knowledge from this data without completely breaking it?
Yes, one way to address it is by using Sampling. The concept of sampling is pretty straightforward: instead of using the entire set of events to make a decision, use a representative subset to get as statistically close to the exact answer as necessary. This is not unlike, for example, when a pharmaceutical/healthcare company says “cure X works 85% of the time…”. They did not test the cure on the entire population and then observed that 85% of it reacted positively! Even though theory says they certainly could :). What they did instead is test the cure on a sample that is representative enough to support their claims.
Similarly, in high volume/low value data scenarios, one can ingest a sample that is as dense or as sparse as needed to answer the right questions with certain statistical guarantees. When looking at operational trends having an appropriately sampled subset of data is definitely better than having no data at all.
Sampling with Cribl
Cribl ships out of the box with a Sampling function. At the time of this writing, it implements Systematic Sampling which can be applied on the entire data stream or a subset defined by filters or field values. In Systematic Sampling, “the sampling starts by selecting an element from the list at random and then every k-th element …is selected, where k, the sampling interval“.
The Function has two filter levels. One – which every other function in Cribl has – determines what events should be passed to it. And another, which determines what level of Sampling to apply to further matching conditions, such as field values or arbitrary expressions. Examples:
Sample all
sourcetype=access_combinedevents 3:1Sample all
sourcetype=access_combinedevents withstatus=2005:1Sample all
sourcetype=access_combinedevents withstatus=2005:1 but only if they’re from a host that starts withweb*Sample all
sourcetype=aws:cloudwatchlogs:vpcflow events withaction=ACCEPT8:1
Multiple filters allow for smart and highly selective sampling. That is, we can ingest full fidelity high-value events from a high volume/low value data stream, but sample the rest.
Each time an event is emitted by the function, an index-time field is added to it: sampled:: which can be used in statistical functions as necessary. For example, if sourcetype=access_combined events with status=200 are sampled at 5:1, to estimate the original number of 200s, you multiply the current number by 5.
Configuring Sampling
For all the examples below let’s assume you have LogStream running and we have at least one pipeline that handles our traffic of interest. Let’s further assume that that pipeline is called main.
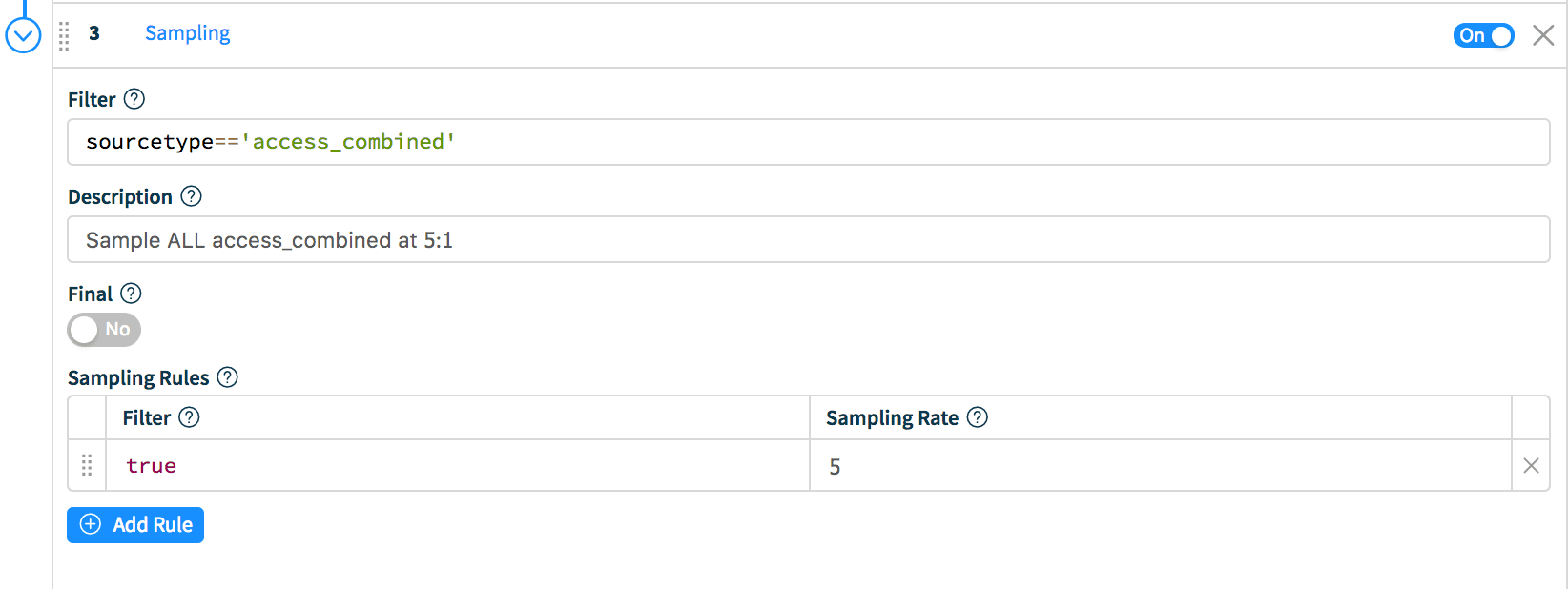
Scenario 1: Sample all access_combined events at 5:1.While in the main pipeline, click Add Function and select Sampling. In Filter enter: sourcetype=='access_combined' and in the Sampling Rules section, enter true on the left (Filter) and 5 as the Sampling Rate.
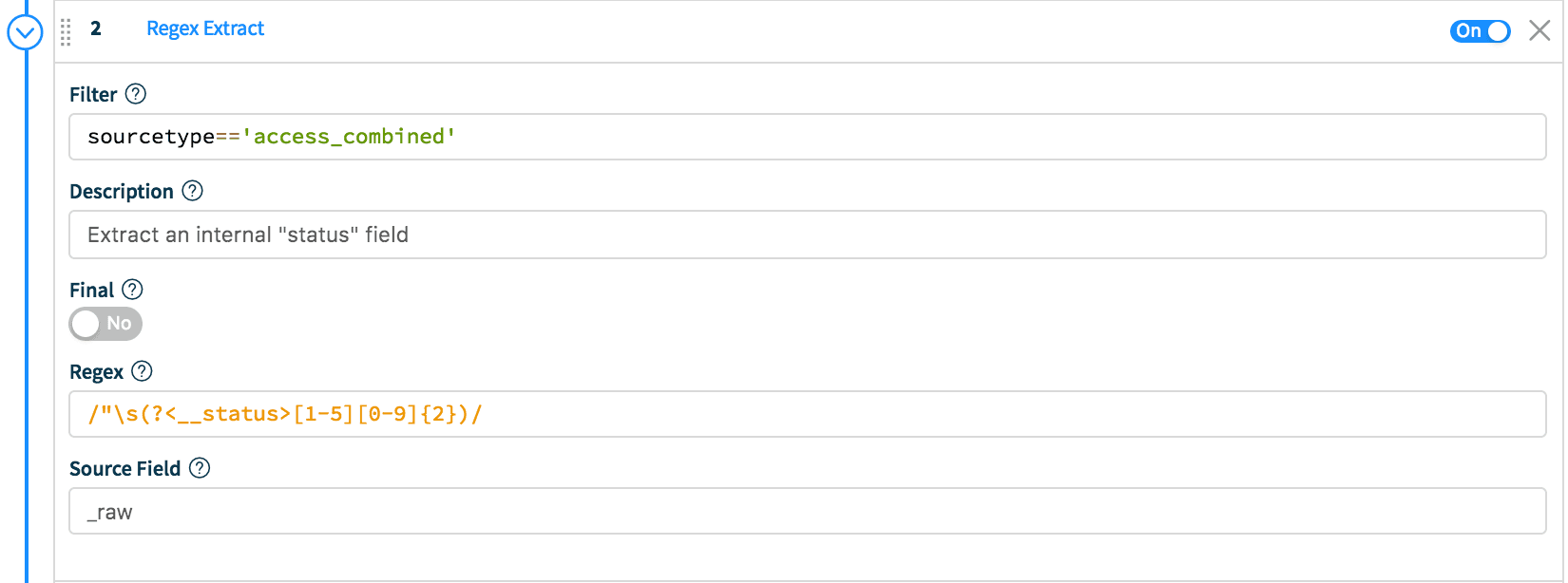
Scenario 2: Let’s make it a bit more complex. In all access_combined events sample events with status 3xx at 2:1, those with status 200 at 2:1 and those with status 200 from local hosts at 8:1.First, let’s extract an internal Cribl field. While in the main pipeline, click Add Function and select Regex Extract. In Filter enter: sourcetype=='access_combined' and in the Regex section, enter /"\s(?<__status>[1-5][0-9]{2})/. Set Source to _raw, which means apply the extraction to the raw event content. This function will extract a field and make it available to other downstream function.
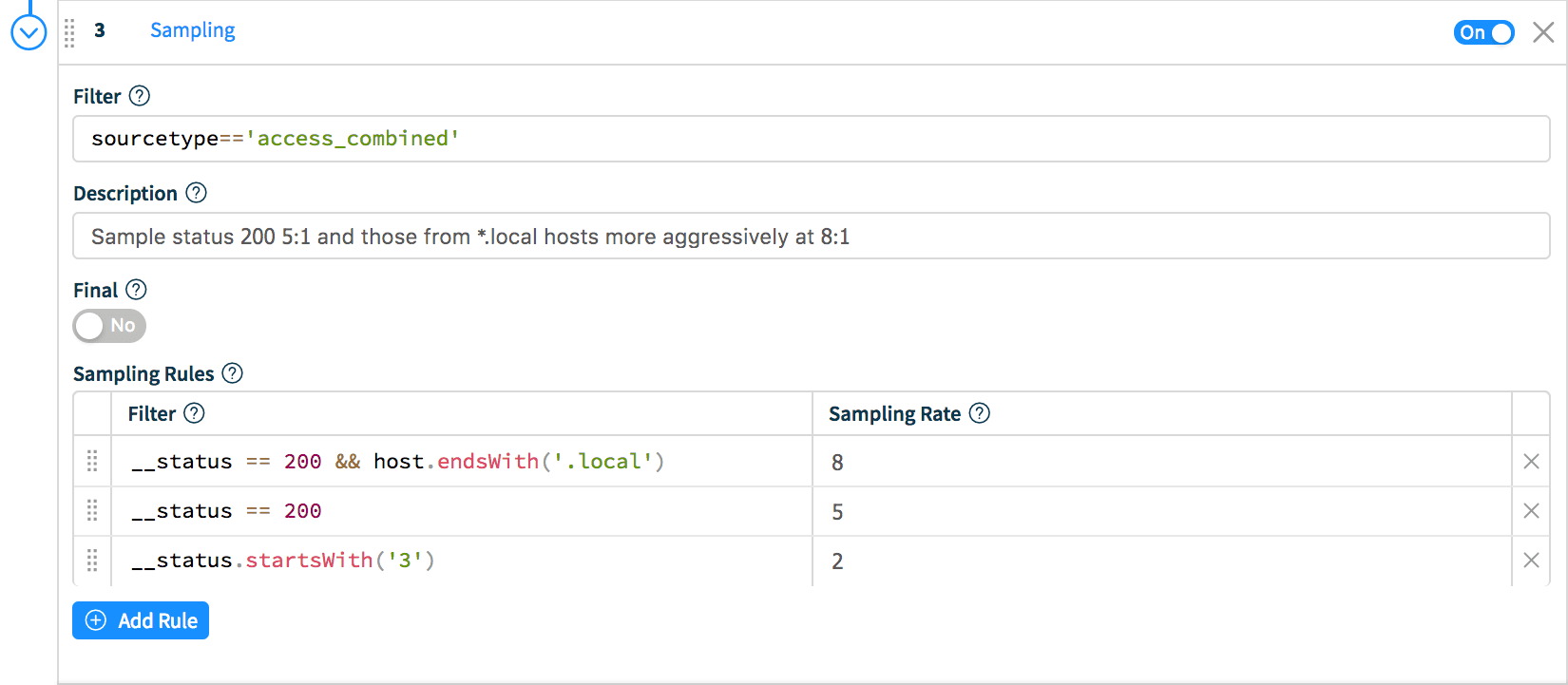
Now, let’s click Add Function and select Sampling. In Filter enter: sourcetype=='access_combined' and in the Sampling Rules section, enter the following:
Filter: __status == 200 && host.endsWith('.local') Rate: 8Filter: __status == 200 Rate: 5Filter: __status.startsWith('3') Rate: 2
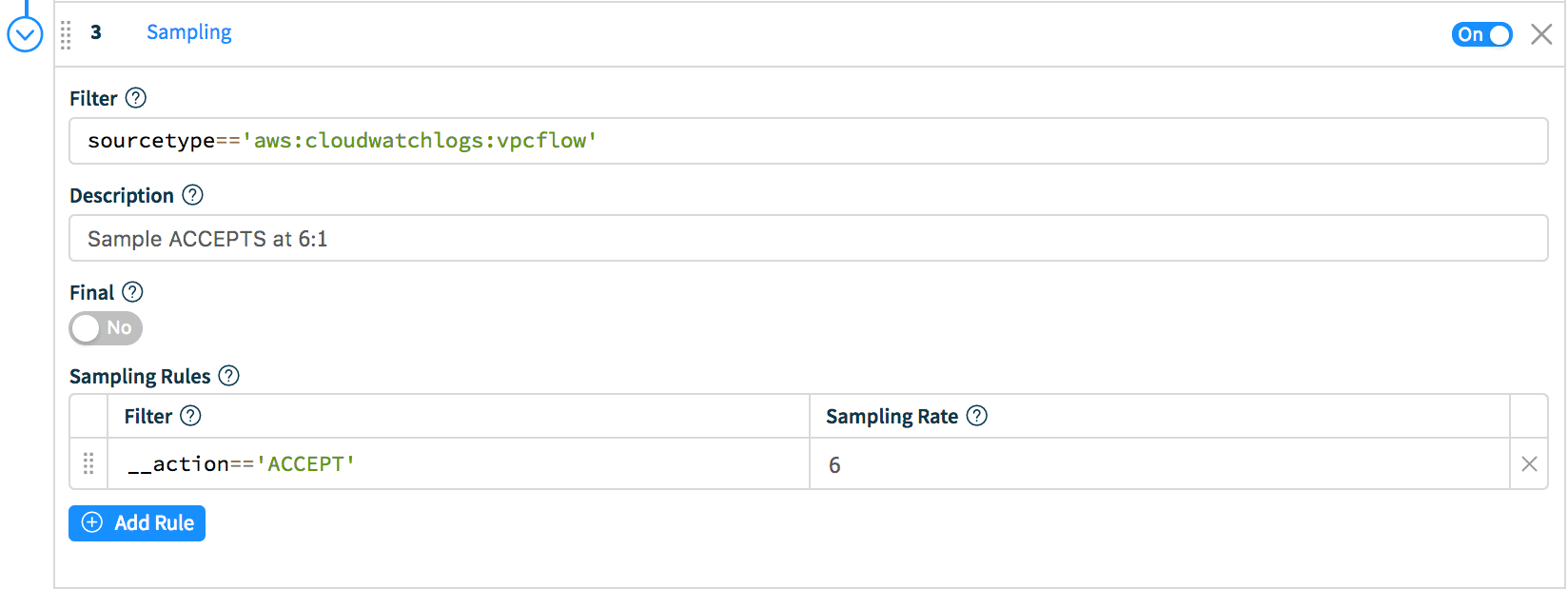
Scenario 3: Sample events with action ACCEPT in aws:cloudwatchlogs:vpcflow at 6:1.Similar to the Scenario 2, first extract a field called __action, then, while still in the main pipeline click Add Function and select Sampling. In Filter enter: sourcetype=='aws:cloudwatchlogs:vpcflow' and in the Sampling Rules section, enter __action=='ACCEPT' on the left (Filter) and 6 as the Sampling Rate.
Finding Candidates for Sampling
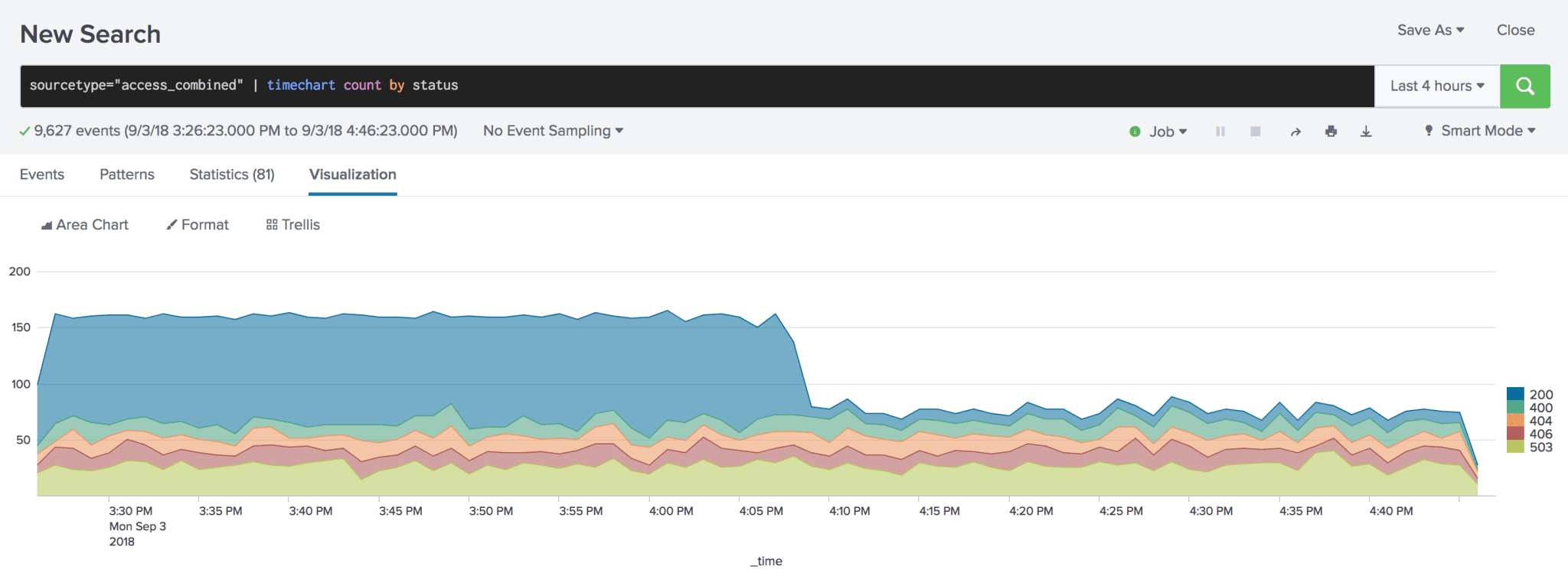
We suggest you run a few quick searches to determine the best candidates for sampling. First, identify a source/sourcetype of interest and, optionally, count by another field: For example:sourcetype=access_combined | stats count by statussourcetype=aws:cloudwatchlogs:vpcflow | stats count by action
Ideal sources are those where count by results span one or more orders of magnitude. Potential candidates for sampling:
Conclusion
“Sample data beats no data 5:1” — Winston Churchill 🙂
Sampling helps you draw statistically meaningful conclusions from a subset of high volume/low value data without linearly scaling your storage and compute. Smart and conditional sampling allows for ingestion of all high-value events so that troubleshooting is done with high fidelity data.
If you are excited and interested about what we’re doing, please join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to hear your stories!







