

Everybody is starting to look more at object storage to deliver on data lake initiatives, and S3, specifically Amazon S3, is the gold standard for that. In addition, we’ve heard from many of you that setting up S3 as a destination is a must when starting with Cribl Stream. So in this article we’ll walk you through the setup.
Customers tell us they use Cribl Stream and S3 to solve several problems:
Meet Compliance Mandates:Strategically sending only the necessary data for triggering alerts and detections, while directing the remainder to cost-effective storage, significantly conserves budgetary resources.
Enhance Tool Performance:Minimize data glut, transmitting only the essential data for reporting and alerting, while maintaining a ‘just in case’ backup copy at all times.
Have Peace of Mind:Should you require a more comprehensive dataset for investigations or reporting, it is readily available in S3, poised to ‘replay’ only the necessary data into your analytics tools, providing precise reporting or additional context as needed.
Now, if this is your first time playing with Cribl, I suggest taking a few minutes (about 30) to go through the Affordable Log Storage Sandbox to familiarize yourself with what we’re going to be tackling today.
Initial Setup
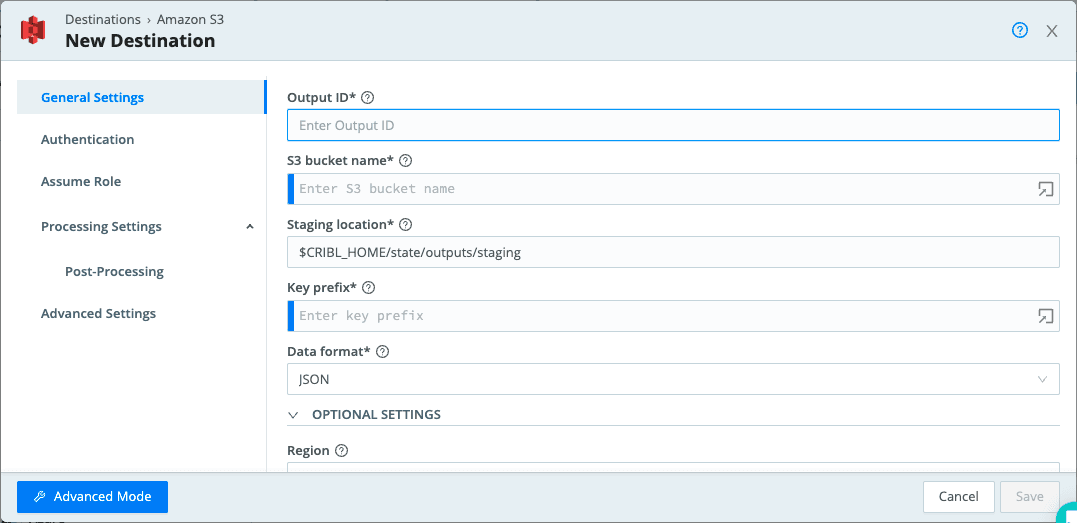
In the initial AWS S3 setup, you’ll want to configure the following fields:
Output ID should be something descriptive for your operations
S3 Bucket Name which is the name of the destination S3 bucket. This corresponds to a directory under /data. In this case, it must be a JavaScript expression (Some best practices for JavaScript Expressions here.)
Region is the region where the S3 bucket will be located
Key Prefix is the prefix to append to files before uploading. In this case, it must be a JavaScript expression. Do not confuse this for an AWS S3 bucket prefix, which represents the full directory where the files are written
If you need more information, feel free to visit our docs page dedicated to Amazon S3 Compatible Stores.
Before we go too far, there are a few things to keep in mind, because when we send data to S3, we don’t just read the data, process it and then send it directly to a bucket. We actually do something else with it that we call staging. The Worker Nodes stage files until certain limits are reached: Time open, idle time, size, or number of files. Once any of the configured limits are reached, the Worker optionally gzips the files and transfers them to the object store. The compression will make your storage bill much smaller by 8-15X over the course of time. In addition, the S3 Destination’s settings allow you to define how the uploaded files are partitioned. Cribl Stream creates subdirectories – Host, time, sourcetype, source – which are available to ease the Replay motion in the future. These are all things to keep in mind as you set up your S3 destination in Cribl Stream.
Scaling Considerations
Things can get unruly pretty quick when dealing with APIs, open files, and queuing, so keep these values in mind as you tackle the next steps of the configuration.
AWS S3 API Rate Limits:
3,500 writes/second maximum per bucket prefix
5,500 reads/second maximum per bucket prefix
Prefix is the entire directory where the object is written
If exceeded, a ‘rate exceeded’ Cloudtrail message is generated, and requests are throttled
Cribl Stream
‘Stages’ data on each worker node and bulk writes to S3
Files stay open by the worker processes until the file is sent to S3
Linux OS
Max number of open files per process, per user, and on the host
Disk space, IOPS and available inodes
Partition Expression
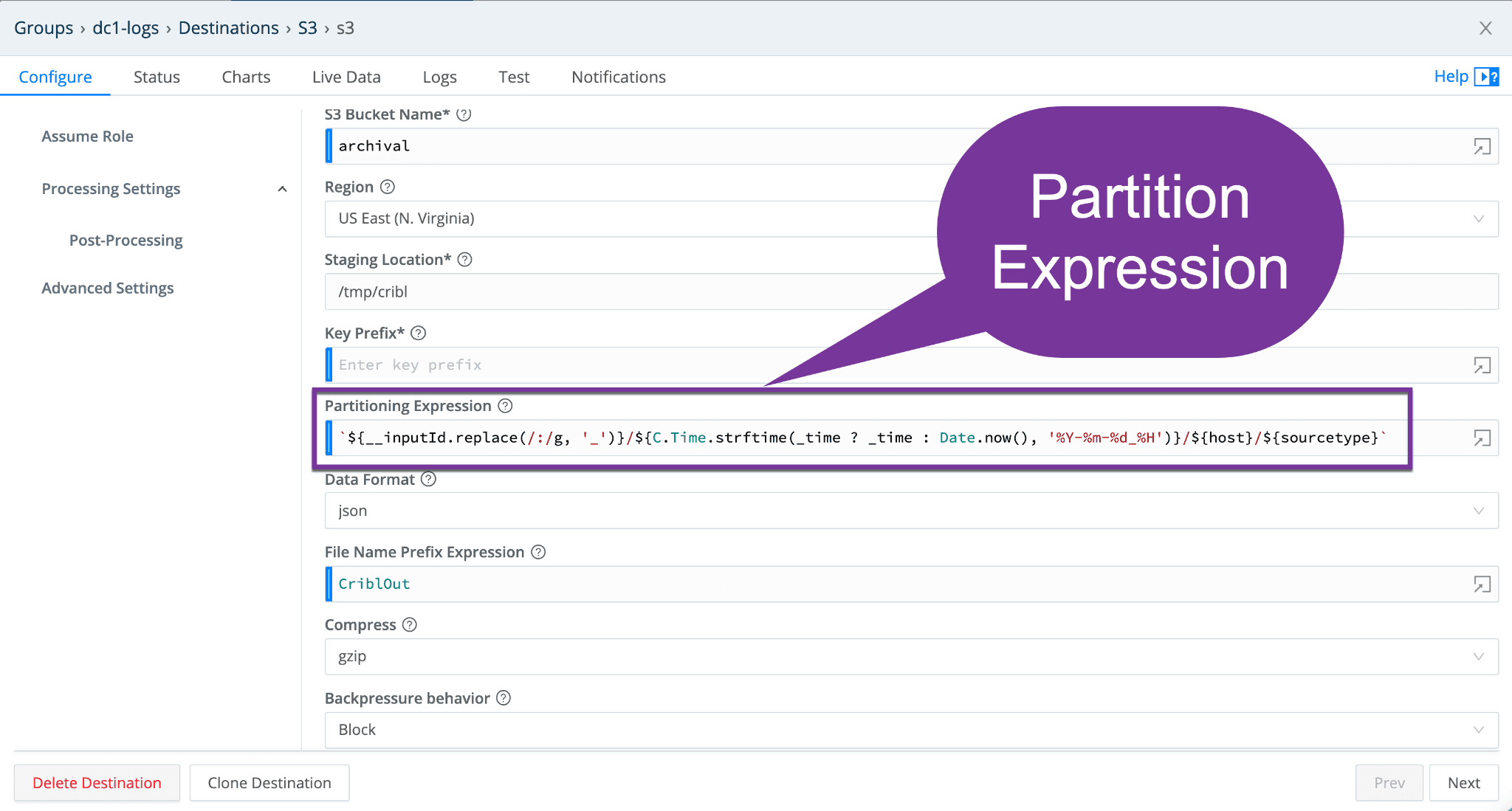
Partition Expressions essentially define how files are partitioned and organized as metadata from the events is added to the S3 bucket directory structure.
If this is left blank, Cribl Stream will fall back to the event’s __partition field value (if present); or otherwise to the root directory of the Output Location and Staging Location.
This becomes very important when you’re Replaying data from the store. The partitions will make your Replay searches faster, when you need to fetch data in the future. We can map segments of the path back to variables (including time) that you can use to zero in on the exact logs you need to replay, without requiring checking _raw. Ultimately, it allows data to be filtered on easily and efficiently – and we recommend creating partition expressions on commonly searched fields.
You do, however, want to be careful with this partitioned expression. You don’t want to have what’s called cardinality be too high. The cardinality has to be reasonable otherwise you’ll have way too many open files and potentially some other queueing issues as a result.
File Name Prefix Expression
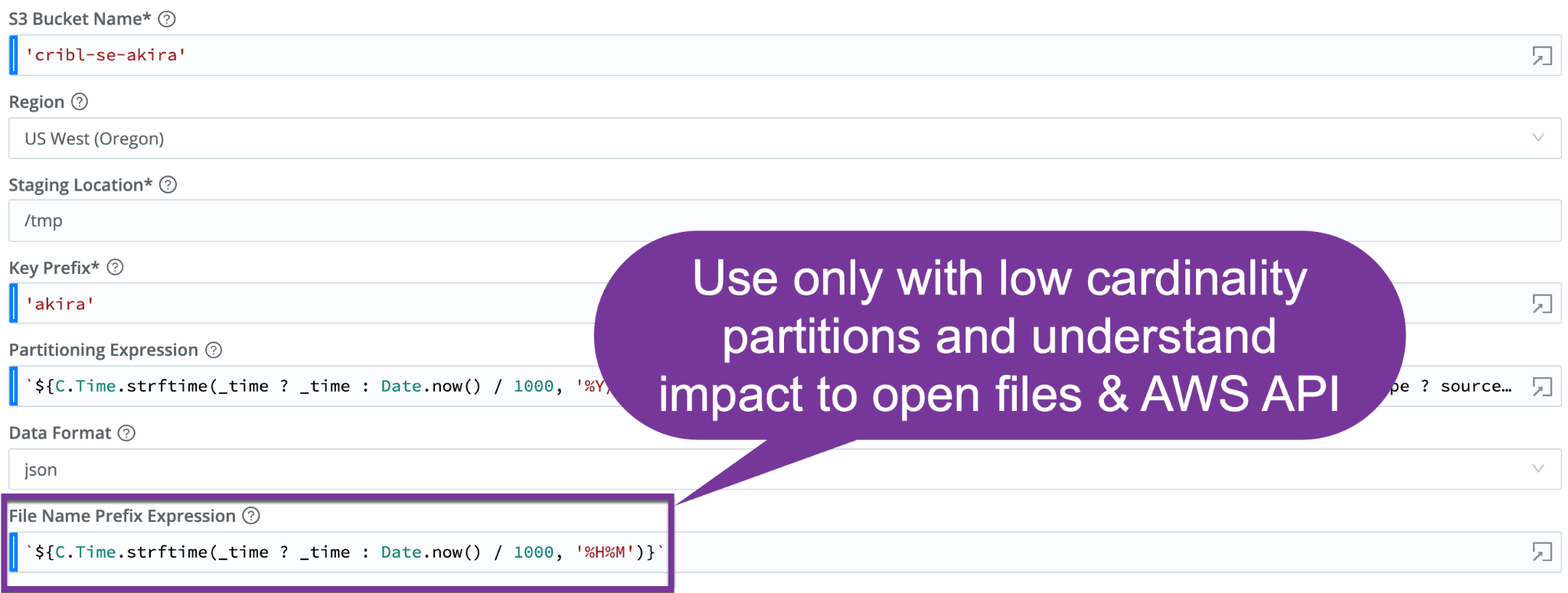
The next tricky field you want to consider is the file name prefix expression, located just below the partition expression in the UI. The File name prefix expression allows you to create a partition, basically different names for files, not just the directories where they reside. They’re based on metadata from the events. The output filename prefix defaults to CriblOut.
You do want to be careful here as this can be both good and bad in the sense that it can negatively impact both read and write API count and can dramatically increase the number of open files. Creating too many of these files can accumulate the number of files in one directory and you can exceed your API loads. It can be super useful in Replay filters but we recommend avoiding unless you’ve done due diligence and have low cardinality partition expressions.
With a cardinality that’s too high, you run the risk of having too many open files. Ask yourself – can your system handle 100,000 or 200,000 open files? Probably not. So it’s important to keep that in mind.
On the other hand, if your cardinality is too low, then you have less filtering ability during replays as well as a larger chance of hitting your API limits with S3, especially when you’re reading.
So, what is the magic number of partition expression cardinality that you should consider? The key takeaway here is 2000 as the maximum values you can have for any cardinality. Now this number is subject to change, you can have it higher. But 2000 is good to use as a baseline, a good number to target. Within the Cribl UI, in a destination’s Advanced Settings, there is a max open file setting which defaults to 100, with a max setting of 2000.
Here’s a good example of partition expression:
`${C.Time.strftime(_time ? _time : Date.now(), '%Y/%m/%d/%H')}/${state}/${interface}/${server_ip}`
state: 2 possible values
interface: 50 possible values
server_ip: 20 possible values
Potential Cardinality: 2 x 100 x 10 = 2,000
With Partition expression and file name prefix expression now set, let’s move to Max File Open Settings. We talked about 2000 as the maximum cardinality for an S3 destination. Remember that the configuration of cardinality is on a per worker process. So, if we have a cardinality of 2000, any one worker process might have 2000 files open at any one moment in time. If you have a 32 CPU system, that means you have 30 worker processes that is 30 times 2000, open files each, that’s 60,000 potentially open files on the system. You would need to make sure that system is updated to accommodate that many open files.
Limit Settings:
Max File Size (MB): Maximum uncompressed output file size
Max File Open Time (sec): Maximum amount of time to write a file
Max File Idle Time (sec): Maximum amount of time to keep inactive files open
Max Open Files: Maximum number of files to keep open concurrently
This is where you can run these various commands found under the advanced settings to update these various files, keep track of and validate and check the limits settings to ensure you’re good to go. Cribl Stream will close files when either of the Max file size (MB) OR the Max file open time (sec) conditions are met. Don’t forget to verify your settings:
# sysctl -w fs.file-max=65536 (as root)
# vi /etc/sysctl.conf (as root)
fs.file-max = 65536
# vi /etc/security/limits.conf (as Cribl user)
* soft nproc 65536* hard nproc 65536* soft nofile 65536* hard nofile 65536
Verify settings:
# sysctl -p
# cat /proc/sys/fs/file-max
# sysctl fs.file-max
Tuning Time
Now that we’re here, let’s take a look at tuning this S3 destination. A good practice is to specifically increase the max open files to avoid getting ‘too many open files’ errors. While the max open files cannot be greater than 2000, it’s not always a good idea to keep it at the max unless you have your operating system all set up, you have enough disk space, and you really did your work with cardinality. When you’re trying to figure out your cardinality, match the timestamp that you’re searching in your analytic tool against what you plan on having here as the maximum number of unique values we have over a given time will affect total cardinality.
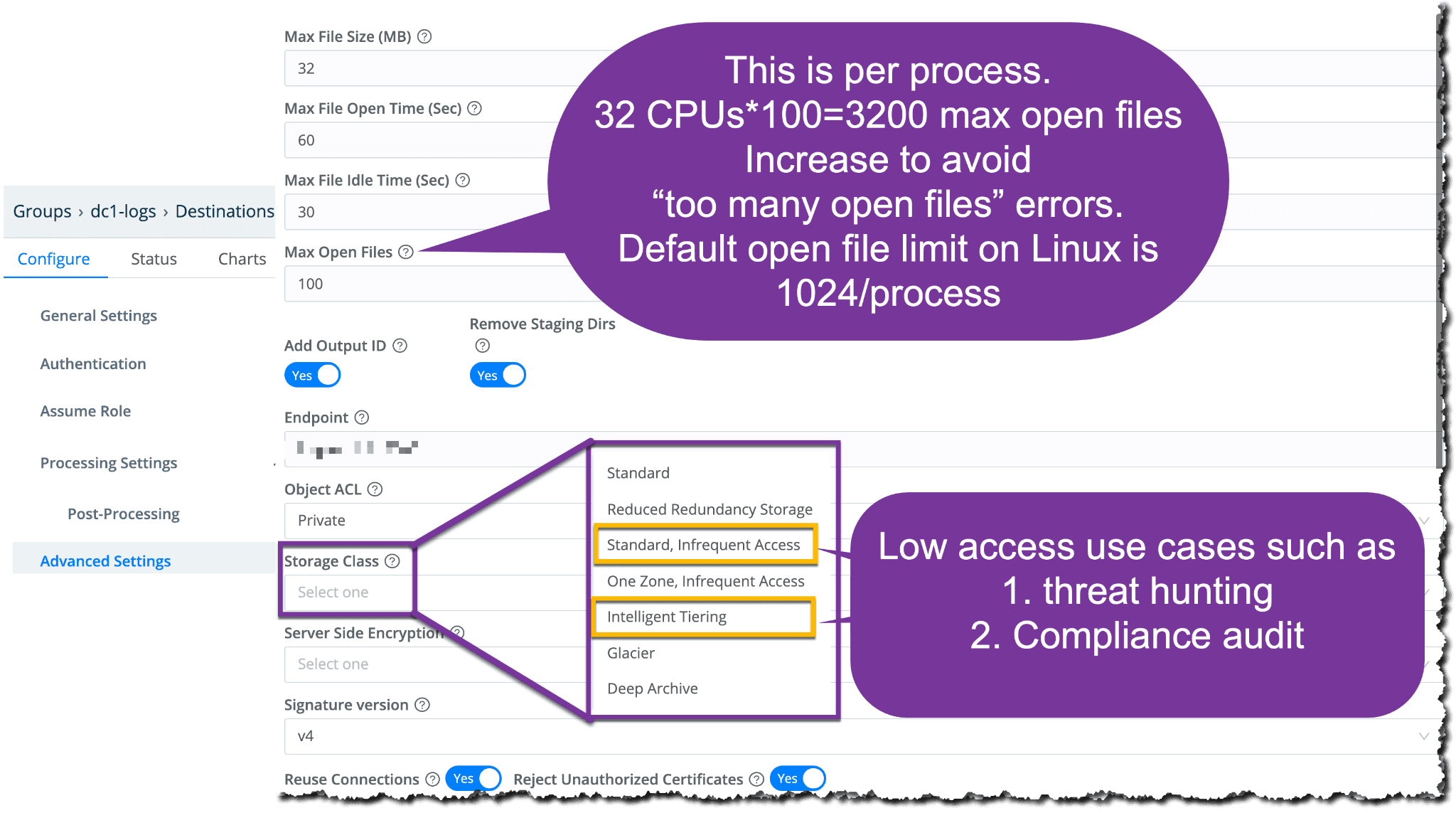
Another setting to call out is the storage class – setting the storage class to something like Standard, Infrequent Access or Intelligent Tiering is good practice for low access use cases such as threat hunting or compliance audits. In this case, intelligent tearing will automatically take older data that is not searched, or that has not been fetched at all before, and put it into a lower tier. For more information on Amazon S3 pricing tiers, visit Amazon’s pricing page.
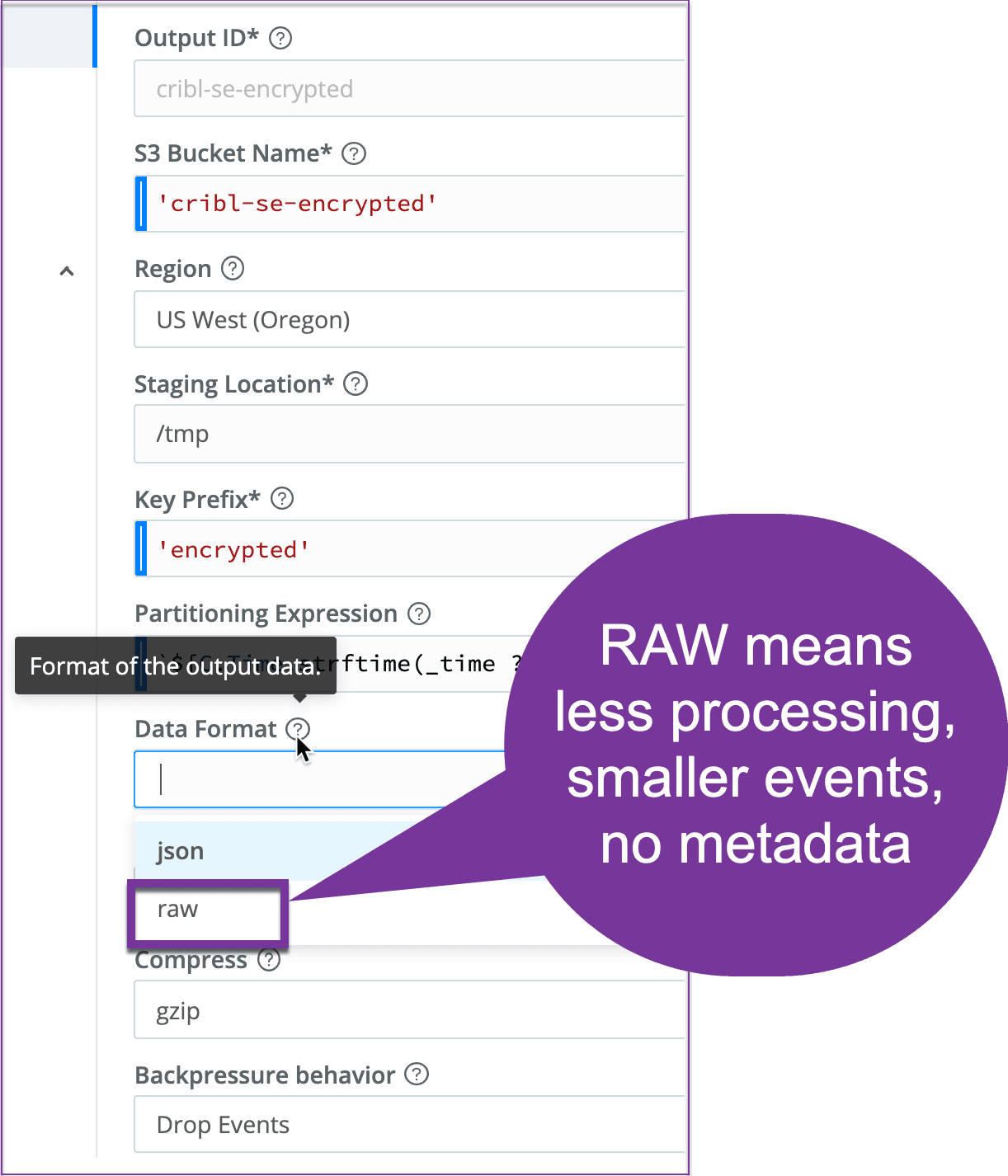
The last thing to note on the tuning side is the data format that you write to S3. By default, it’s JSON. This means you’re going to have the raw events as one field. And then you’re going to have a bunch of Cribl fields and other fields as metadata that are going to be shipped into these events as a JSON payload.
Now on the other side, _raw, just takes the original Syslog event or the original event that came from a Cloud trail, for example, and sends that on to the S3 bucket as is.
Don’t forget to set compression as this is usually something that will dramatically lower your storage costs – typically with compression you get anywhere from 70 to 90%.
Another setting worth calling out is ‘remove staging dirs’. This setting should always be enabled. Cribl will regularly check if any directories are empty and remove them. If this is not set, you can easily have millions of empty directories and run out of disk inodes.
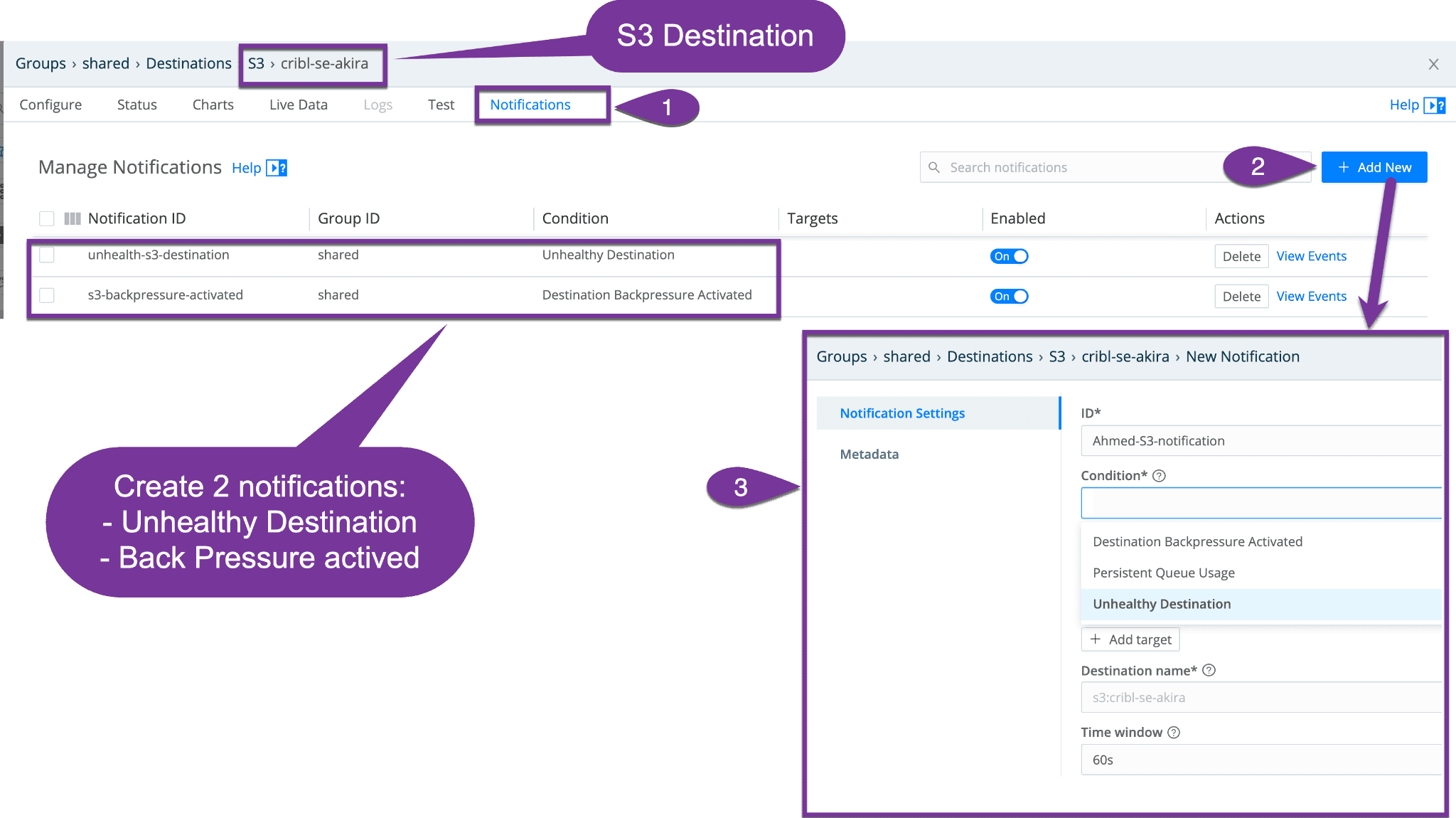
And the last piece to configure is the notifications. This allows for notifications to be sent if a destination is bad or when back pressure is activated. It’s always good to know the health of your pipelines.
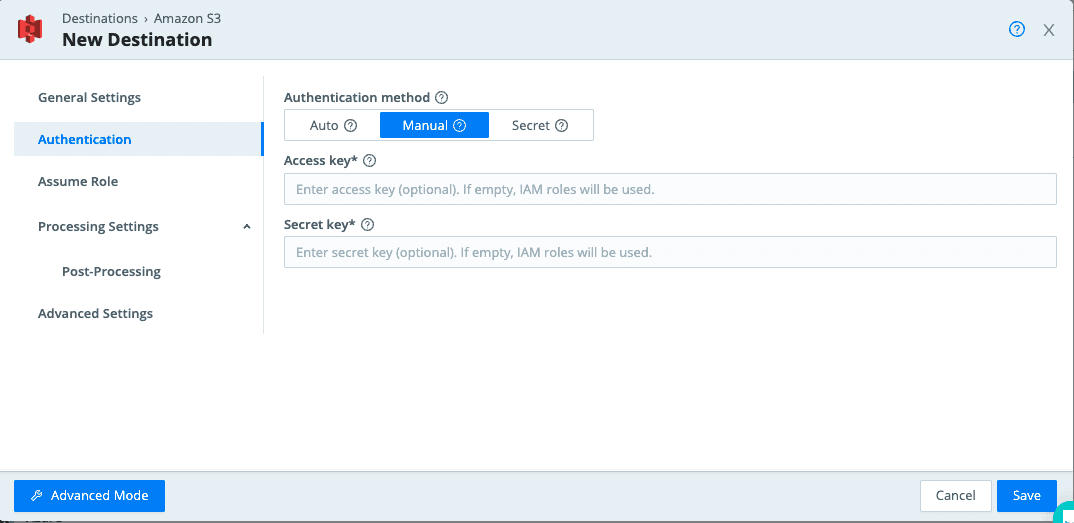
And to close things off, let’s chat authentication. This can be set using the buttons to select one of these options:
Auto which is the default option that uses the AWS instance’s metadata service to automatically obtain short-lived credentials from the IAM role attached to an EC2 instance. The attached role grants Cribl Stream Workers access to authorized AWS resources.
Manual: If you’re not running on AWS, you can select this option to enter a static set of user-associated credentials (like your access key and secret key) either directly or by reference. This is useful for Workers not in an AWS VPC,
Secret: if not running on AWS, you can select this option to supply a stored secret that references an AWS access key and secret key.
Voilà! If you’re here, that should mean S3 is set up and configured correctly and is ready to accept data! In addition, most of what we covered in this post is actually part of the Cribl Certified Observability Engineer (CCOE) Stream Admin certification offered by Cribl. For more in-depth, practically-oriented courses and content to help you become a Stream expert, don’t forget to check out Cribl University. For more tips and tricks on how to set up and tune S3, follow the links below:
Better Practices for Using AWS S3 with Cribl Stream Office Hour
Cribl Community (Cribl Curious, Slack, and more!)





