

When I worked as an information security practitioner, I spent most of my time responding to and investigating alerts. These alerts were from various tools such as next-generation malware detection and prevention systems, web proxies, firewalls, and email filtering appliances. Occasionally, as part of triage, I’d need additional context surrounding the users’ or machines’ activity to determine the validity of the alert. This necessitated indexing large volumes of data from all of the security and other tools deployed in the environment, just in case that data source became relevant.
The overused phrase “finding a needle in the haystack” is an apt analogy to the data feeds I used every day. Large quantities of hay were indexed when only the needles were interesting and relevant and should have been indexed. The inability to selectively index what was relevant resulted in gross overspend on licensed ingest capacity and infrastructure to keep all of the logs searchable at the click of a button.
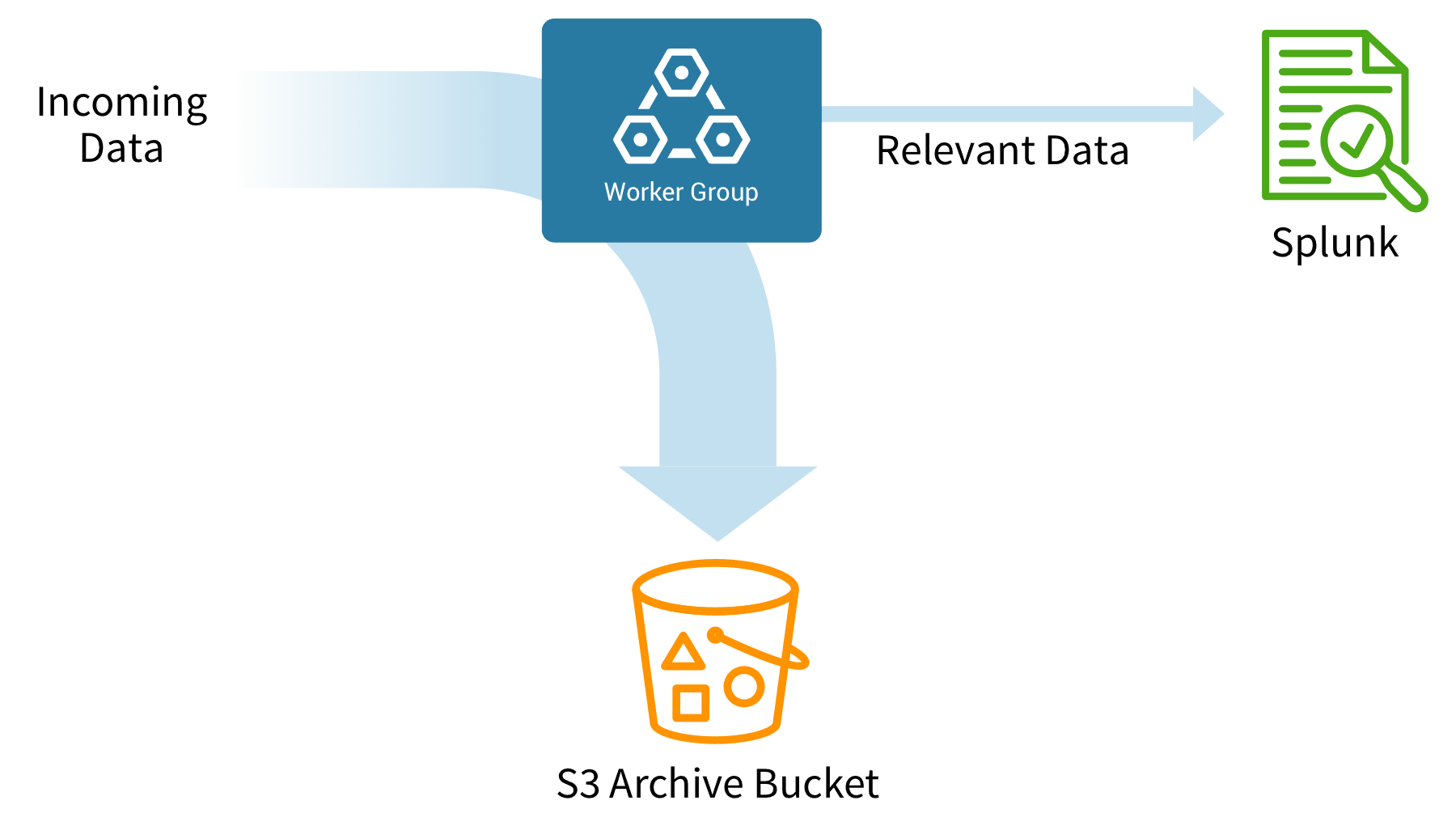
Cribl Stream solves the haystack problem by allowing selective routing of events and metrics. Analytics tools can receive relevant logs and alerts, while context can be shunted to “warm” object storage. Always ready and available to be sent to the indexer but stored inexpensively, this context can be quickly forwarded and indexed by an analytics engine or SIEM for correlation. When analysts need relevant data, they can replay it using a collector job and send it to the analytics engine or SIEM. The trade-off here for the reduced license and infrastructure costs is the time required for analysts to run the collector jobs needed to index their required data.
Before joining Cribl, I was a professional services engineer and had opportunities to work with customers on Security Orchestration and Automated Response (SOAR) platforms. A SOAR platform is a security analyst on steroids designed to resolve alerts quicker. In Splunk Phantom terminology, alerts are referred to as containers, and tags can be assigned to the container to classify the type of alert. Playbooks are built to be run based on the tags assigned to a specific container. Decisions can be made automatically or sent to an analyst for further review or to make a decision. The goal is to automate as many repetitive tasks as possible, using APIs and coding the decision trees.
One benefit of SOAR solutions is that they can be customized to work with just about any solution, provided the solution has an API. Stream is built on an API-first approach, meaning everything done through the user interface is actually done through API calls. Any SOAR solution can leverage Stream to run collector jobs without the need for human interaction. Why not send the majority of data to object storage and only replay it when it’s absolutely necessary?
With that idea in mind, I built a solution for the Splunk Phantom SOAR platform with Stream integration. While the integration is written for Splunk Phantom (because that’s what I encountered in a majority of my professional services engagements), it can be adapted for any SOAR platform. The Phantom app with Stream integration is available for free download on my Github and released under the MIT License.
How does it work?
Inside Stream, routes redirect high-volume data sources like DNS, web-proxy, and firewall logs to inexpensive object storage. This data is stored “warm” in object storage, ready for immediate indexing any time if required to investigate a security incident. These sources of data are great for context during investigations but rarely used to trigger alerts.
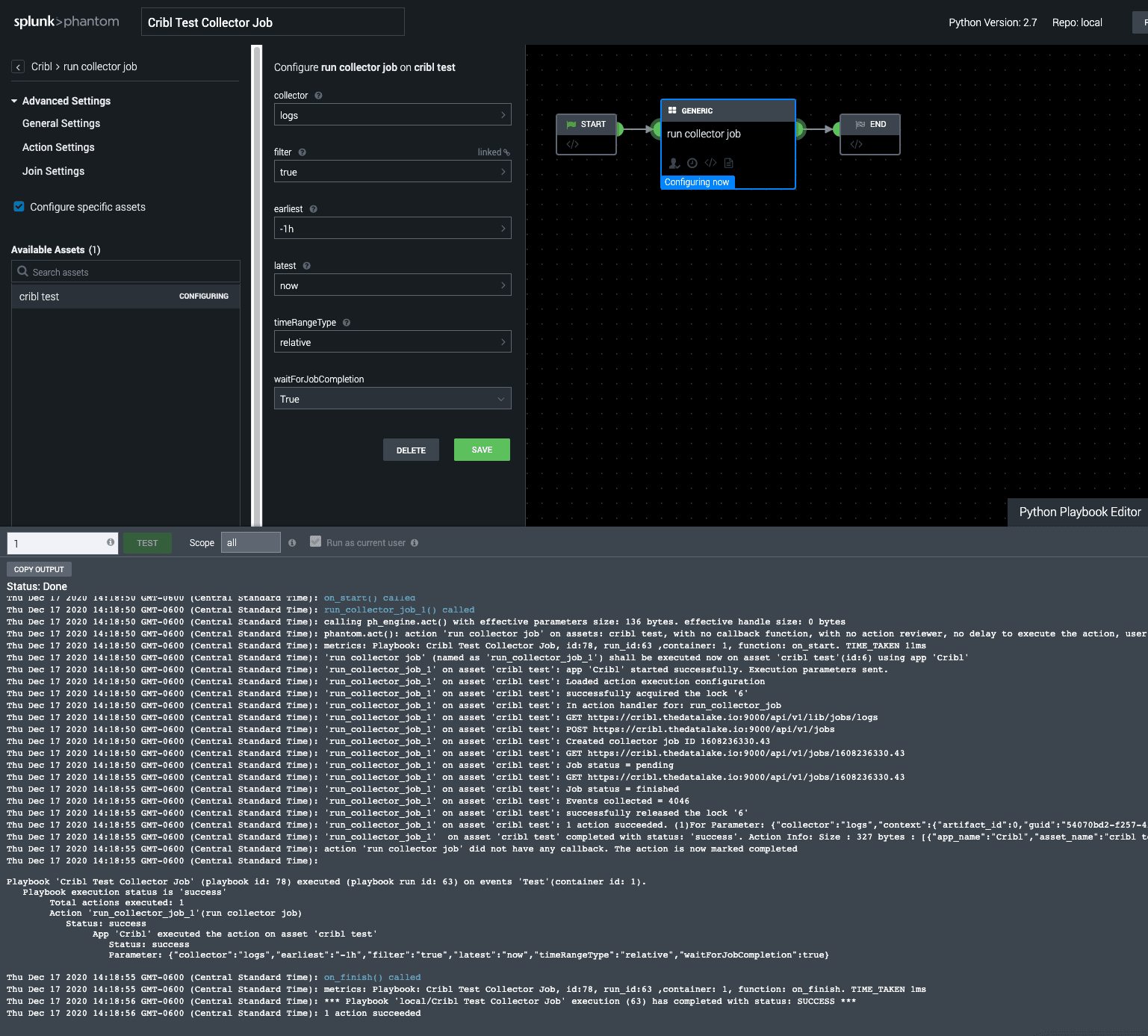
When the SIEM sends an alert to Phantom with data, Phantom runs playbooks based on the tag assigned to the container. Inside a playbook, actions can be defined to run one or more Stream replay jobs. The replay action can be configured with the appropriate filter, time range, and a flag to wait for the collector to finish before continuing with the remaining playbook actions.
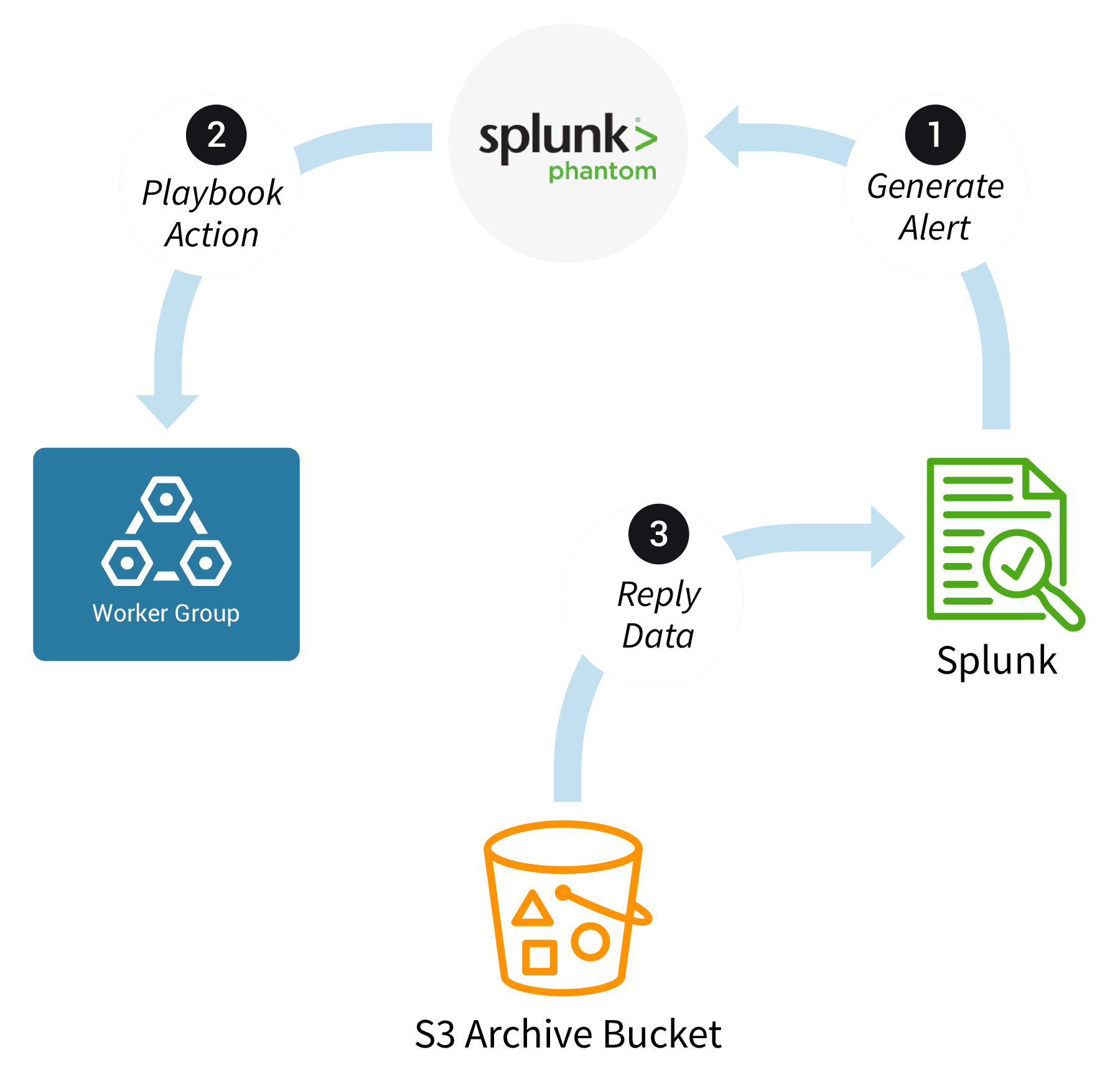
The playbook action requests only the relevant data required for the investigation, allowing surgical precision when indexing additional data. This solves both problems highlighted earlier: 1) It reduces indexed data volumes and 2) It automates the replay of the data into the SIEM, as needed for an investigation, without having to wait for a human to perform this step. The context for an investigation is waiting as soon as an analyst begins their work.
Happy automated threat hunting with Stream!
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.







