
As the tech lead behind Data Collection, the leading feature of LogStream 2.2, I can say we faced many challenges developing a scalable, accurate solution to batch collection of data at rest. Among those issues was a resource load balancing issue that cropped up late in our development of the feature. We’ll discuss this issue more in depth within this post.
TL;DR
Using a least number of in-flight tasks job scheduling algorithm allows LogStream to fairly and equally load balance work across all of the running jobs.
Jobs Primer
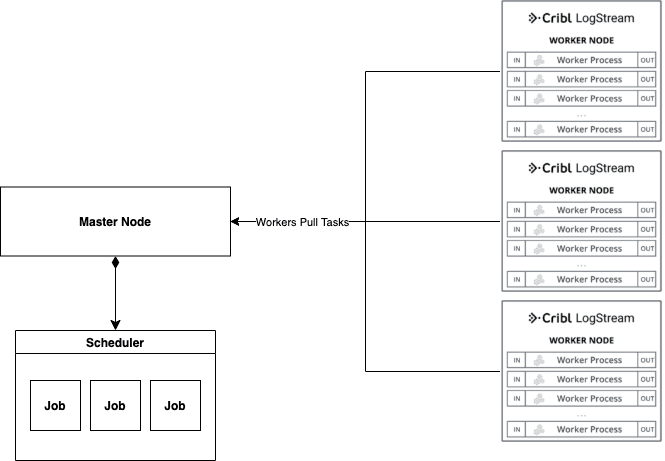
The LogStream Data Collection feature is powered by our Jobs Framework. Before we dive into the load balancing problem we encountered, let’s discuss some of the components and terminology of this framework.
Data Collector – check out this blog post or our docs
Task – one unit of work
Data Collector Discovery Task – discovers all the files/objects requiring collection
Data Collector Collect Task – collects the data from a given object and sends it into LogStream’s routes/pipelines
Job – a collection of tasks that embodies an instantiated run of a Data Collector
Scheduler – the component that determines which jobs’ task to run next
A quick view of the system:
Problem
During development of a new feature, it’s typically best to get a working prototype merged, so all the different pieces of the system can be integrated together. This unblocks others to extend and test the system before release date. In order to facilitate this, I decided to implement a simple round robin load balancing algorithm for determining which Job’s tasks were to get resources to perform their work.
Near the end of the development process, when we were testing how the Jobs framework scaled with multiple running jobs across many worker nodes, we discovered that the number of in-flight tasks for each job were highly variable. This meant that some jobs were having more resources spent on them while others were getting next to no resources allocated to them
Digging into the issue, we discovered the root cause of this behavior was the jobs that had more in-flight tasks also had much greater execution times for tasks. Given each task represents the collection and reading of a file/object, either from filesystem or S3, they are bound to have highly variable execution times by nature.To prove the above assertion, I pulled out the pen and paper to draw out a scheduling diagram of a hypothetical situation including 3 different jobs and 6 workers pulling tasks from the jobs. The jobs’ tasks can be broken down by task durations:

Below is a scheduler diagram that shows how round robin scheduling will behave with the above job definitions over an arbitrary length of time (20ms). A black box indicates the start of a task and the grey boxes depict the duration for which the task runs. Given that there are only 6 workers, there will only be 6 concurrently running tasks at any given time (i.e. there will only ever be 6 shaded boxes on any given column in the below diagram)
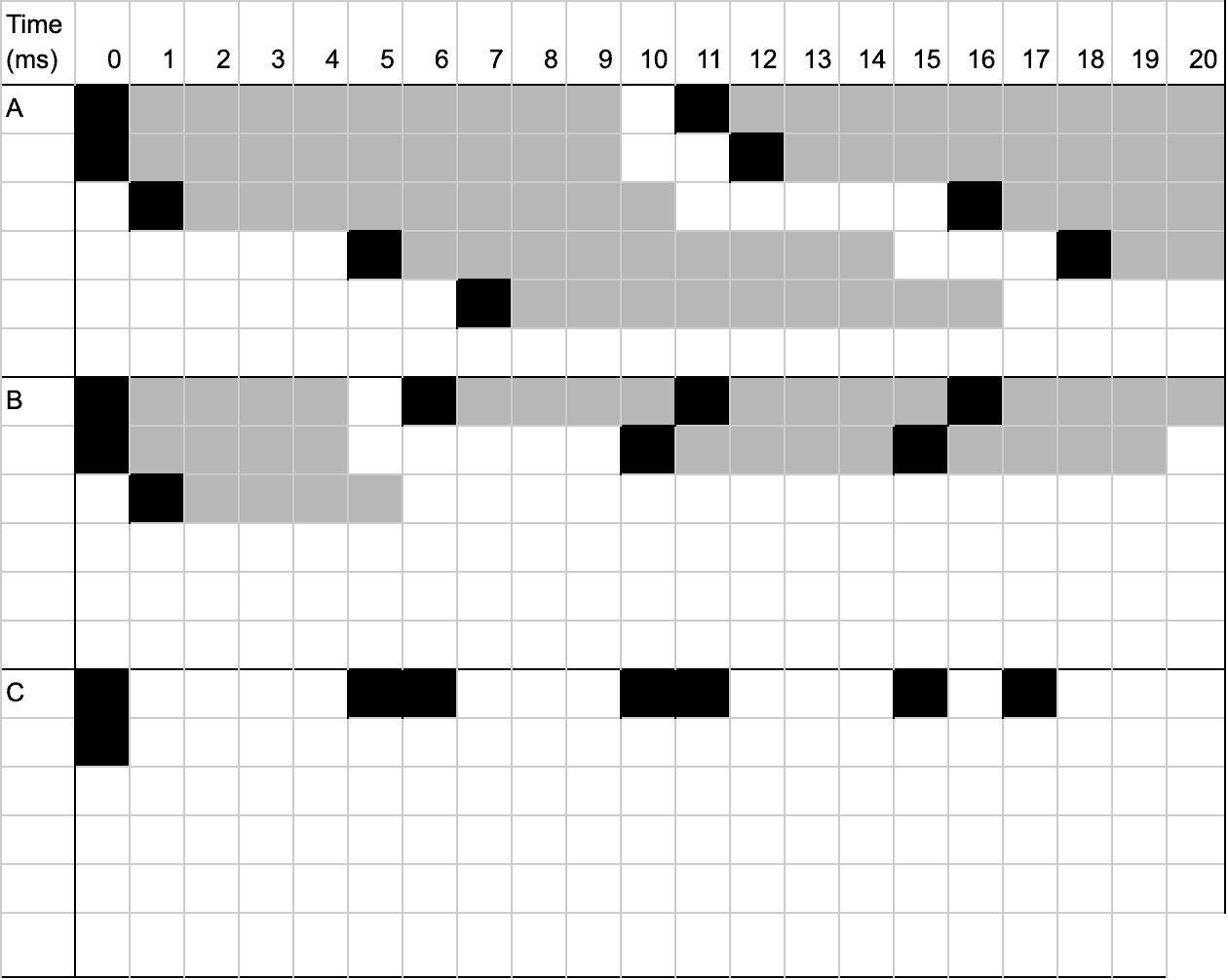
From the above, we can gather the following empirical data:
A Tasks: 3-4 tasks at any given time
B Tasks: 1-2 tasks at any given time
C Tasks: 0-1 tasks at any given time
We also see that none of the jobs ever reach completion due to the way the round robin algorithm distributed resources to jobs.
With this data, let’s attempt to come up with a formula for determining the average number of in-flight tasks for a job at any given time.
If we sum up the total amount of task durations, we get 10ms+5ms+1ms = 16ms. Given this, we find the following shares of time consumed by each jobs’ tasks:
A Time Ratio: 5/8
B Time Ratio: 5/16
C Time Ratio: 1/16
From this we can determine the average number of tasks each job will have in-flight at any given time by multiplying the time ratio by the number of workers that can pull tasks:
A Average In-Flight Tasks: (5/8)*6 = 3.75 tasks
B Average In-Flight Tasks: (5/16)*6 = 1.875 tasks
C Average In-Flight Tasks: (1/16)*6 = 0.375 tasks
From the above calculations, we found the overall formula for determining a job’s average in-flight task count would be: avg_in_flight = (job_task_duration / total_task_durations) * num_workers.
Solution
Using a round robin algorithm, while fair in the sense that we will never starve any one job, was unfair in that it would over-allocate resources to a job made up of tasks that will have longer execution times. Round robin will only be fair in a homogenous environment where the machines performing the work are similar, the jobs have a similar number of tasks, and the tasks all have similar execution times. In order to load balance the number of tasks being run per job, we decided to implement a least in-flight task scheduler, which is very similar to a networking least connection scheduler algorithm.
The idea behind the least in-flight task scheduler is we allocate the next available resource to the job with the least number of current in-flight tasks. Doing this allows us to keep an equitable number of in-flight tasks across all the running jobs, so they all progress at the same rate regardless of how long their tasks actually run.
The algorithm also takes into account scaling up and down depending on the number of running jobs. When a new job is spawned and has no resources available to it, the algorithm will handle balancing out resources to the new job. Once some resources are freed up from the previously running jobs, they will automatically allocate to the new job with no resources until the number of in-flight tasks balance out across all jobs in the system. Same goes when one of the jobs completes. The resources it was using will be distributed equally to the remaining job in the system.
Just for fun, let’s break out the scheduling diagram for the least in-flight tasks scheduler:
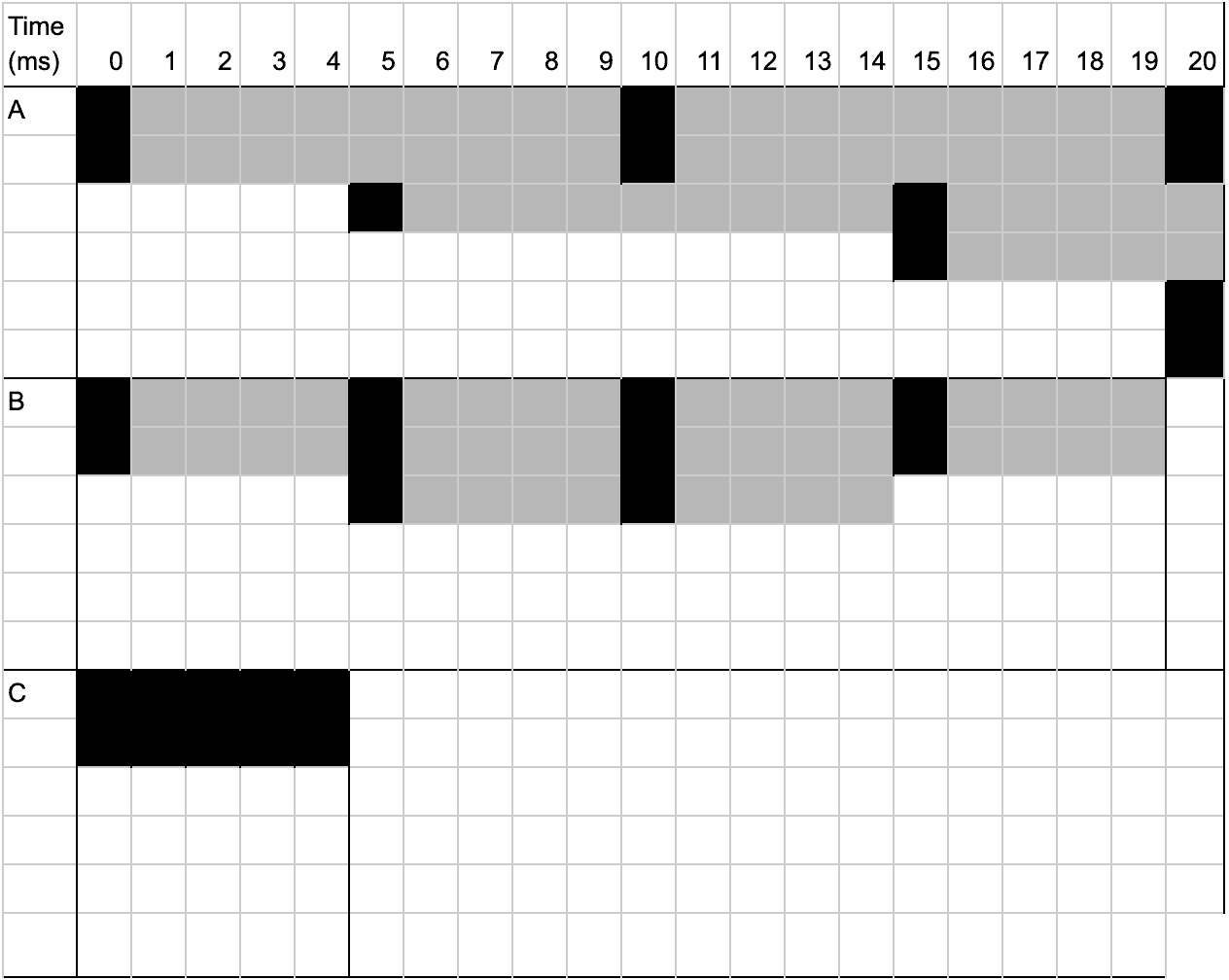
Using the least in-flight tasks scheduling algorithm, both Job B and Job C were able to complete, which is something we did not see occur with the round robin scheduling algorithm.
As described above, we can see that we now fairly load balance the tasks being run across each job instead of gravitating resources towards the job with longer running tasks resulting in a formula of avg_tasks_in_flight = num_workers / num_jobs regardless of task duration.
Wrapping Up
While schedulers are often viewed as an operating systems concept, they can be applied to various application-level problems, especially for handling disparate workloads at scale. It’s always good to dust off the old textbooks and refresh your memory on the concepts you slept through during lectures. You never know when they’ll be applicable to your current work!







