
I’m a product person. There are many, many key decisions in the life of a product that make it what it is, but few decisions are more critical or more impactful to the product and its go to market motion than pricing. Product Managers spend endless hours debating the merits and flaws of pricing models. In fact, a great way to initiate a denial of service attack against your PM team is to constantly start up new debates about pricing models.
I’ve been waiting with great anticipation for Splunk to unveil the new pricing model it’s been hinting at on its earnings calls and elsewhere. Of all the pricing models in the world, there is none I have spent more time studying than daily ingestion volume. I spent five years as a product management leader at Splunk, and while I was there we debated this topic endlessly. We picked Daily Ingestion for Cribl LogStream because I believe consumption models are fair to both parties and they’re incredibly cloud friendly. I’ve argued for and against many different models: ingestion, per search, per core, per node, per user, and more. It’s no shock to anyone that concerns about cost are paramount to Splunk customers, and there has been no shortage of criticism far and wide about the daily ingestion volume pricing metric. So, it’s pretty damned big news that yesterday, Splunk unveiled a per-core pricing model at their event “Bring Data to Everything.”
First of all, as a Splunk partner we could not be more excited to see Splunk continue to be willing to make potentially huge changes to its business model. More pricing options are good for the customers. For some customers, this new model could dramatically impact the solution cost. It’s great to see Splunk, now a massive company, listening to the market and its customers. Splunk couldn’t have gotten to where it is today without a killer product providing a ton of value to its customers. However, pricing models and especially changes to them are primarily about the enterprise sales process and giving the salesforce more tools to overcome objections. Offering additional models should not be confused with lowering prices. Changing models, for most customers, will offer at best marginal benefits.
Why Pricing Metrics Matter
In any product, how you charge drives all kinds of incentives and disincentives. Consider a few alternatives for Splunk’s pricing model. Charging by users is predictable and tied directly to growth for the company, but tends to lead to high per unit costs and strong incentives to cheat by sharing logins. Charging by employee count has recently gained traction in newer startup offerings, which allows for unlimited ingest, but it requires the customer to license the entire company in the first year deal and leads to high land costs. Per query or per search licensing also allows for unlimited ingest, but directly disincentivizes actually using the data and getting value from it. Per core too allows for unlimited ingest, but actively incentivizes starving the systems of resources to control cost and could also disincentivize vendors from making big performance improvements.
None of these models is right or wrong. Each model will change fundamentally how the product is sold and consumed by its customers. It’s quite a good sign to see a vendor like Splunk offering multiple models, because it gives customers the ability to optimize for themselves depending on their unique circumstances. However, the new model didn’t come along with much material about how this model will benefit or won’t based on a customer’s circumstances. I’ll attempt to analyze different scenarios to see if your workload might benefit from per core licensing. Since the new metric is tied directly to the number of cores a customer needs to run Splunk, we need to first examine what drives the total size in cores of a customer’s install.
Demystifying Pricing: Choosing the Right Model for You
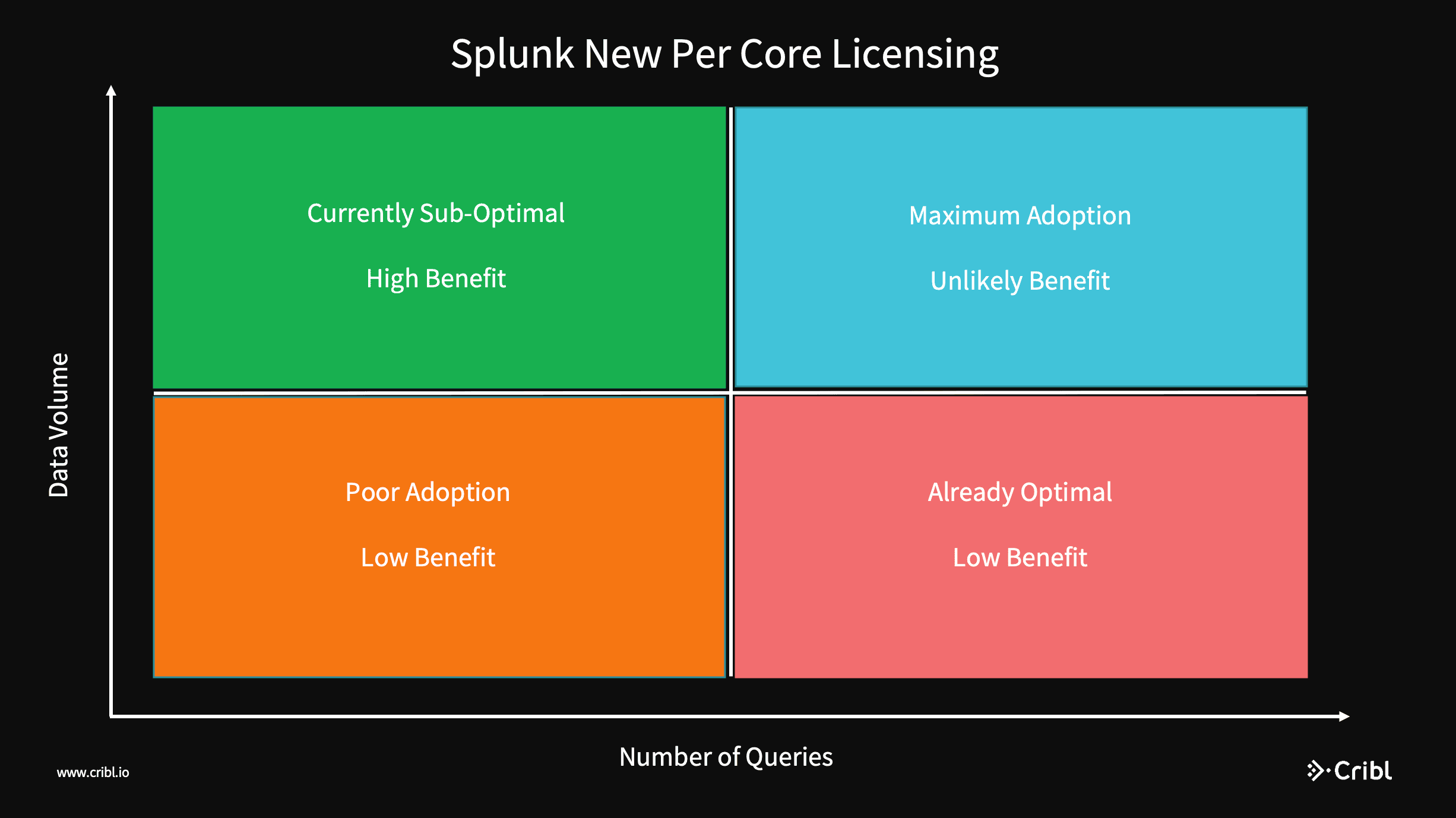
There are two primary dimensions which will drive the total number of nodes, and thusly number of cores, needed in a Splunk Enterprise installation: daily ingestion volume and expected query volume. To determine which model might be better for a given workload, we need to examine that install based on those two dimensions. This analysis assumes that Splunk is going to set its per core unit based on a nominal installation of Splunk, something like the Splunk Reference Architecture, where 1 to 2 cores per machine are handling ingestion and the remaining are processing search/query workloads.
I’ll divide the problem space up into 4 quadrants for easier discussion.

Let’s examine these four scenarios:
Low Volume, Low Queries (Orange): If you’re here, adoption is poor, and you probably think Splunk is a really expensive way to grep logs
Low Volume, High Queries (Red): The new model will penalize you heavily, you’re already as good as it gets
High Volume, High Queries (Blue): Splunk is highly utilized! Congrats! With both metrics maximized, unlikely one or another will change pricing materially
High Volume, Low Queries (Green): This is where the model can make a huge difference.
Daily Ingestion volume is already pretty well understood, and anyone considering making a change likely is looking to understand their query workload to understand where they might fit on this chart. There are a number of factors that drive query volume. Large scheduled workloads, especially for the premium apps like Enterprise Security and IT Service Intelligence, drive high query workloads. High numbers of saved searches for alerting or large numbers of real time searches drive high query workloads. Large numbers of active users drive high query workloads.
The use cases most likely to see lower query workloads are where Splunk is used as an online archive or primarily as an investigation tool without much scheduled workload. Additionally, if your users don’t particularly care about performance, you can likely ingest a lot more data but have a much poorer performing system with this license model. If your use case can be optimized for ingestion processing with low search volumes or longer query times, you could be a huge beneficiary of this model.
Cost is a Function of Volume
No matter which pricing metric you choose, total cost of a machine data tool is still a function of data volume. Infrastructure for the solution is a direct function of volume. Processing workloads for ingestion increase with volume. Query times lengthen with more data and require more cores to process more data. However, value is not a function of data volume.
There are numerous techniques for maximizing the value of your log analytics tool by removing noise and maximizing information density. Aggregation and converting logs to metrics can vastly reduce query times and data storage requirements. Deduplicating streams of data can remove a ton of noise in the log stream. Dynamic Sampling can allow you to get accurate aggregations and still drill into raw data on a fraction of the overall data volume.
In our experience, big savings can often be achieved using the most simple technique of all: removing unnecessary information. Half of all log data is simply junk. Uninteresting events can be dropped entirely. One of our customers uses ingestion enrichment to drop DNS logs to the top 1000 domains, cutting 1TB of daily ingestion to 50GB of highly security relevant data. Uninteresting fields in log events can be easily removed. One of our customers cut 7TB/Day of endpoint logs to 3TB just by dropping fields they weren’t using. In many cases, just using our out of the box content for removing the explanatory paragraph in Windows Event Logs, removing fields set to null in Cisco eStreamer logs, or dropping unused fields from Palo Alto firewall logs can free up huge capacity for more valuable use cases.
Cribl LogStream does all of this out of the box today and can be placed transparently in your ingestion pipeline to work with the data before it’s indexed in Splunk. If what you are looking to do is maximize your investment in your existing tooling like Splunk, we can deliver value to your organization very quickly.
Wrapping Up
We’re super excited to see Splunk offering its customers new options. If you’re in the right circumstances, you might see a big difference in price with a different model. But, 100% of people considering switching pricing models to control costs can more predictably and effectively maximize the value of their solution by optimizing their data stream to remove noise. If you’d like help achieving that, Cribl LogStream can really help Splunk customers maximize their investment in Splunk, while also giving administrators new capabilities to unify their ingestion pipeline and send data wherever might be best for it to be analyzed. We’d love to chat with you.
The fastest way to get started with Cribl LogStream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using LogStream within a few minutes.







