

In Cribl Stream 3.0, we introduced Packs! Packs are self-contained bundles of configurations that allow users to solve full use cases with minimal setup/configuration on their part. One of the first questions I tend to get regarding Packs is “how do they fit into the existing Cribl Stream system?” As the Tech Lead for the Packs project, and also a self-professed hater of packing, I feel uniquely positioned to further discuss the design decisions we made when creating the easy-to-use Packs system!
TL;DR
Packs are fully isolated from each other and from the existing set of Routes and Pipelines in your Cribl Stream deployment. The easiest way to think of a Pack is as a fancy pipeline. You can choose to send data to it via the Routes page in the same exact way you would select a Pipeline. Anywhere you can use a Pipeline, you can use a Pack instead.
What Problems Does Packs Solve?
One of the biggest problems that our existing customers faced when it came to managing Cribl Stream was shuffling around content in their various Worker Groups and Deployments. Another challenge was onboarding new customers from zero content.
Starting from zero configuration is a problem with any piece of highly customizable software, really. It’s an even bigger problem when the piece of software must be configured to handle an enterprise’s very specific data infrastructure that is already in place. The advent of Packs allows us to provide customers with value essentially out of the box, by building out common data processing use cases.
Once you get past the easy, common use cases, however, you must start building out your own content to share amongst your various Worker Groups. What exactly is that content being created and shared? Your use case-specific data processing. And what comprises your data processing? Routes, Pipelines, and Knowledge Objects (e.g. Lookups, Global Variables, Schemas, etc.).
Solution
So how did we build Packs to solve the above problems for you? We started from our number one goal: Allow sharing self-contained content. This guided the design of Packs from the start. We immediately drew a box around a subset of our data processing capabilities and ripped it out, to provide a modular, self-contained experience. That box captured Routes, Pipelines, Knowledge Objects, and Functions, or what very much looks like a mini-Stream (Diagrams or it didn’t happen? Don’t worry, I got you…later in this blog).
This subset of functionality provided the smallest set of configurations to actually allow shipping a full use case in a Pack. It allowed us to build out the Packs functionality in a timely manner and actually get it into your hands. This subset also allowed us to craft very specific interactions between Packs and the existing Cribl Stream data processing engine. The result? A much smaller surface area for Packs to potentially cause any regressions within your existing deployment.
“Why did we leave out Sources and Destinations?,” you may ask. Well, we had to make a tradeoff between shipping the Packs system in a timely manner or with all the features we could ever dream up. Since Sources and Destinations are already decoupled from the data processing tier of Stream, it made for a very easy cutting point. It also adds greater control and understanding of where data is entering Stream. Data will enter the product only from the global level instead of from various Packs. There’s also not a one-to-one relationship between a Source or Destination, versus the set of Routes and Pipelines processing them. This means there may be disparate, unrelated data sources coming in through the same Source, or going out through the same Destination.
So there’s been a lot of text in this blog post. I like pictures. Let’s go to the pictures:
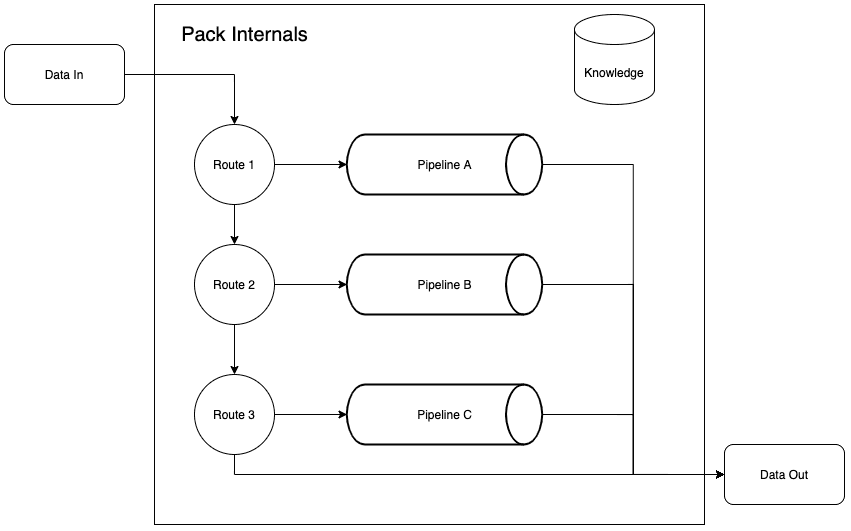
Here’s a cross-section of a Pack. Looks almost exactly like a mini-Stream, right? That’s because it contains almost everything that makes up Stream, except for Sources (which also exclude Event Breakers), Destinations, and Collectors.
Now, how does that Pack fit into the rest of the Stream system? Here’s another ugly engineering diagram to enlighten you:
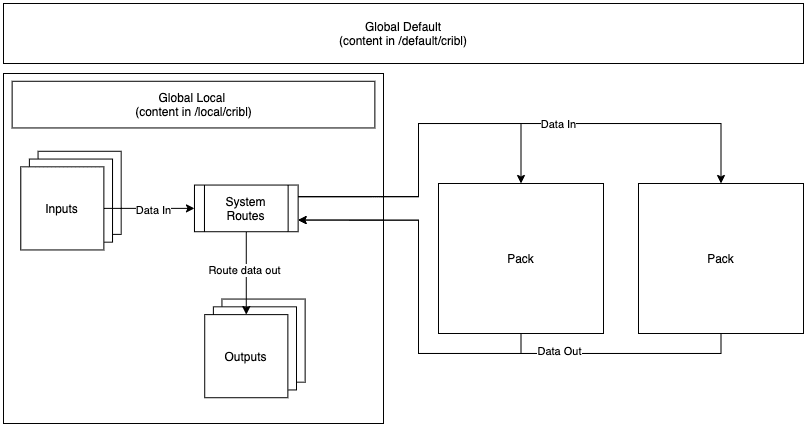
So Packs are isolated from your broader Stream system, as well as from each other. However, we wanted it to be easy to get started with building out Packs (solving starting from zero again). So we allowed Packs to inherit the default settings from the global Cribl Stream. This means Packs have access to all of the default Functions and Knowledge objects that are available in the global Stream deployment.
Providing access to the global default configurations made sense, as it would ease the development of Packs, allow for much smaller (disk-wise) Packs, and solve starting from zero. In the future, we’ll have to support versioning of Packs against Stream versions, but that’s a worthwhile tradeoff to make the customer experience simpler and to be respectful of hardware constraints.
Wrapping Up
The Packs project ended up being a much more complex undertaking than expected, given all the pieces that existed in Stream before Packs. There’s a real challenge in repurposing the existing componentry within a system to find the simplest, most elegant solution to dealing with tech debt, while maintaining compatibility with your existing deployments. I look forward to discussing, in a future post, how we used one of the more esoteric features of Node.js and V8 to enable building out the Pack isolation model.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







