

The challenge for every organization is gathering actionable observability information from all your systems, in a timely manner, without creating a substantial operational burden for the teams managing the collection tooling. While each observability solution has its unique benefits and challenges, the one common burden expressed by teams is the management of the metadata of the metrics, traces, and logs.
When setting up the collection methods, teams are often asked to make decisions upfront on how the observability data will be captured and ultimately reported on within your platform of choice. Examples include the name of the business system or service, metadata collected on hosts managing those applications, or information that ultimately helps connect these systems to the correct ownership/support team. These naming choices are usually configured by the team setting up the collection mechanisms and can be riddled with misconfigurations, out-of-date information, or typos. These overlooked configuration errors will lead to alerting delays or, in the case of a solution such as Datadog, tagging mismatches that ultimately break the integrations of the traces, metrics, and logs. These delays only hinder the troubleshooting process and will introduce more downtime as teams must first focus on getting the observability data to report correctly before addressing the issue.
The Need for an Observability Pipeline
Cribl is an Obeserablity Pipeline that helps quickly gather and aggregate observability data into your platform of choice. Cribl Stream helps manage the metadata configuration in a centralized location. Within the central configuration of Cribl Stream, observability teams can capture and view observability data flowing through the system, test and validate any changes to that data independent of previously configured transformations, and then choose when to push these updated changes into production using Cribl’s built-in deployment and version control process.
These updated configuration changes to the observability metadata occur within Cribl Stream, not the systems managing/hosting the applications. Providing this decoupling of observability configuration changes with the systems managing the application allows teams to push changes knowing they are not introducing changes to the systems managing production applications. Cribl Stream, via the built-in version control processes, also allows for a quick and easy rollback of a change if it is ever needed.
Example of Cribl Stream in Action:
Now let’s look at an example of how Cribl Stream is helping observability teams gain better data flexibility while maintaining their existing processes and collection methods. In this blog, we’ll show how Cribl Stream can quickly correct misconfigured tag data in the DataDog agent. This tag data, left uncorrected, would break the ability of a team to correlate both log and metric data within the Datadog platform.
First, a team must configure the Datadog agents to communicate with the Cribl Stream pipeline vs. the Datadog platform endpoint. This will introduce Cribl Stream within the middle of this data flow and provide the ability to update the agent’s tag data seen later in this blog post. Details on configuring the Cribl Stream Datadog Source and the Datadog agent configuration updates can be found with Cribl Stream Documentation here.
Once data flows from the Datadog agent, a team can quickly inspect the data within Cribl Stream via the “Live Data” tab. This assures teams that the agents are configured correctly to send information to Cribl Stream but also provides the ability to “Capture” this data as sample data for later transformation configurations.
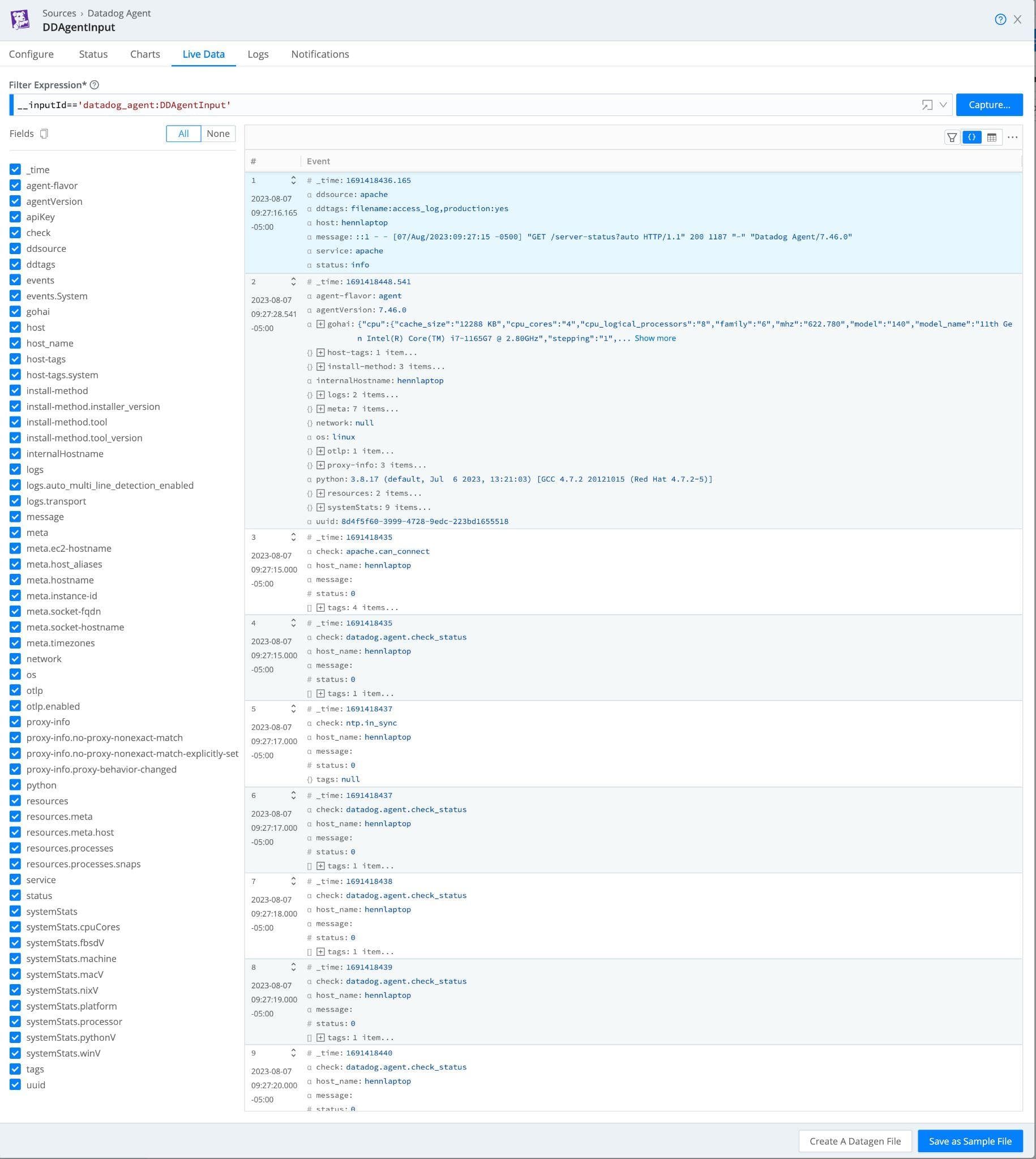
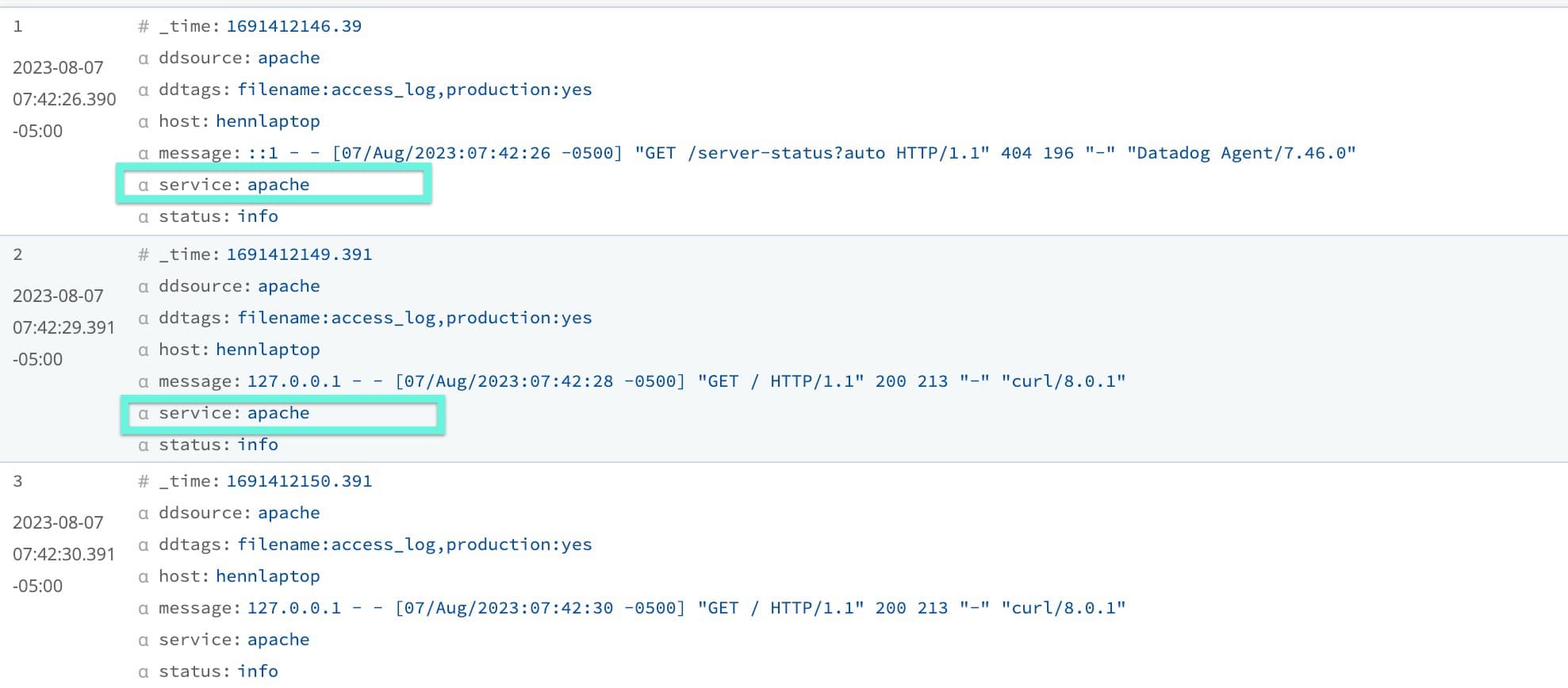
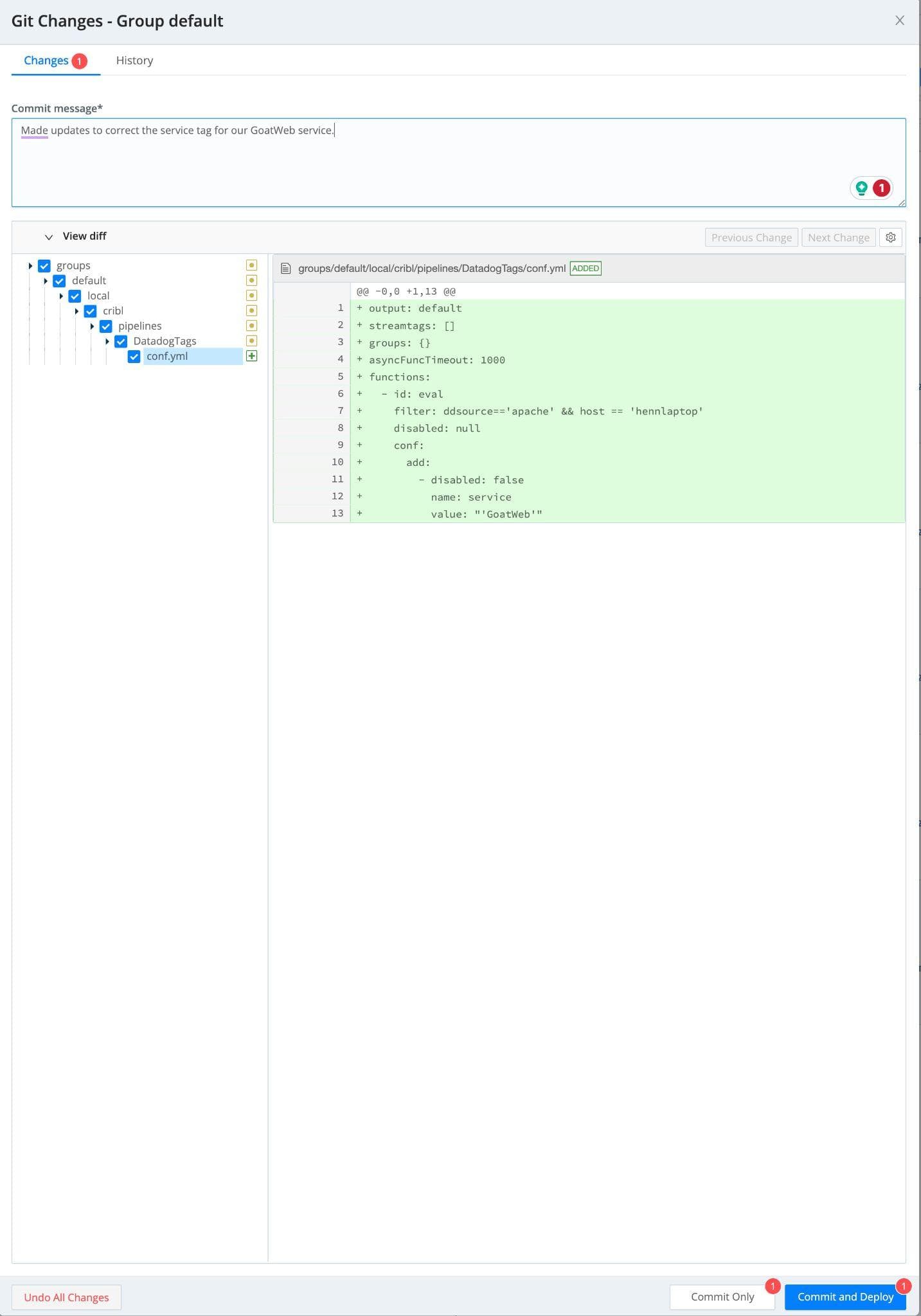
Once a sample file has been created from the captured Datadog metric and log data, a team can validate and update any metadata/tags the Datadog platform requires. In this example, the agent was hastily configured to collect all the Apache logs on the system, and unfortunately, the service tag was not configured. Not having the proper application name defined within the service tag will break all the integrations with data already collected for the GoatWeb application.
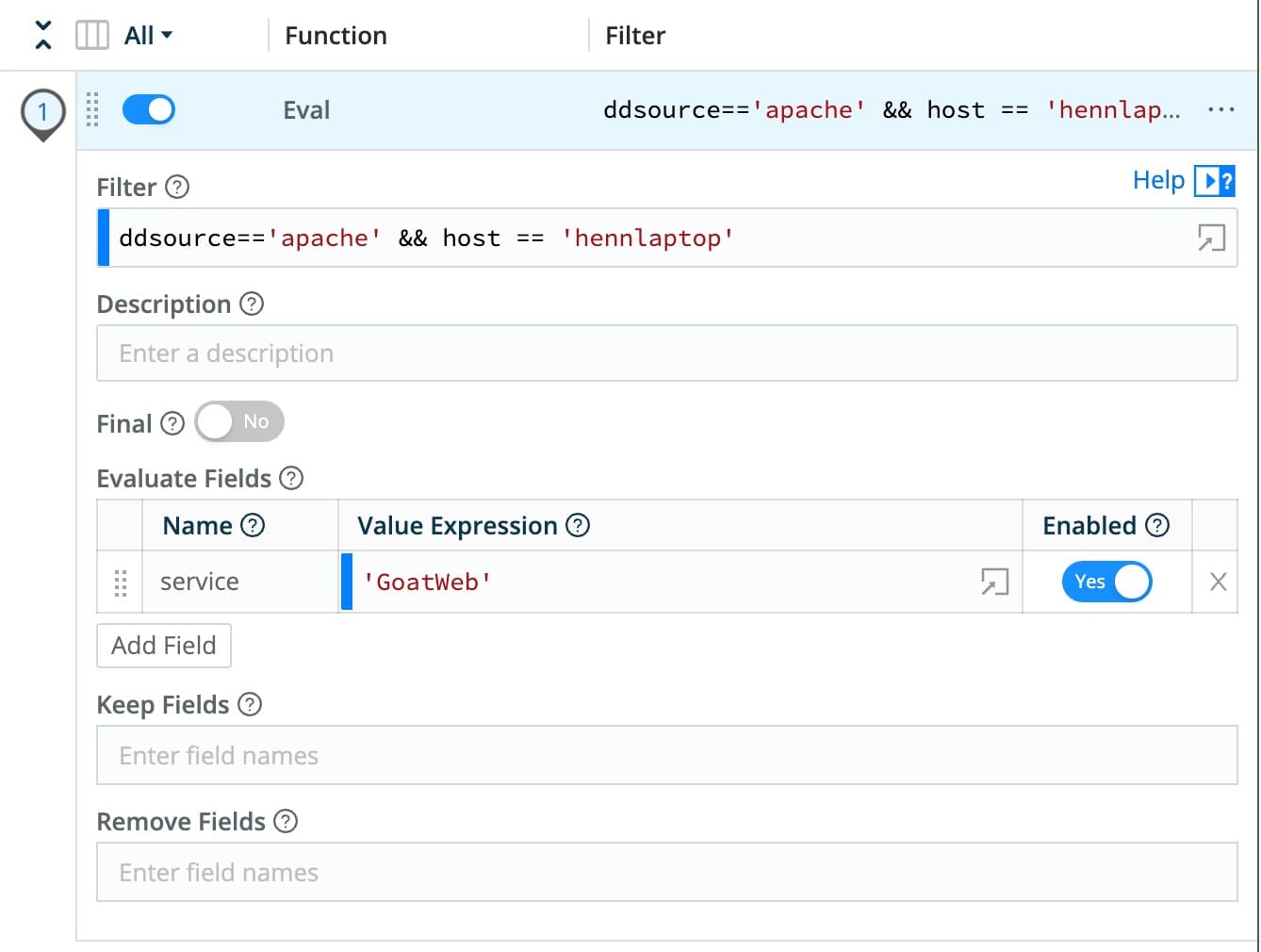
Adding a quick function within the Cribl Stream pipeline, the Datadog service tag can be quickly updated to reflect the correct application name. Below is an example of the Eval function to make that change. The function is configured to change the service tag to “GoatWeb” only if the log source is Apache and the message comes from the host hennlaptop.
Validating this change with the sample data already captured in Cribl Stream, the person making this update will be able to see that any future Apache log messages coming from hennlaptop will have the GoatWeb application name correctly set in the service tag. At this point, the update to the service tag is only being applied to the sample data. Data following through Cribl still has the service tag with a value of Apache.
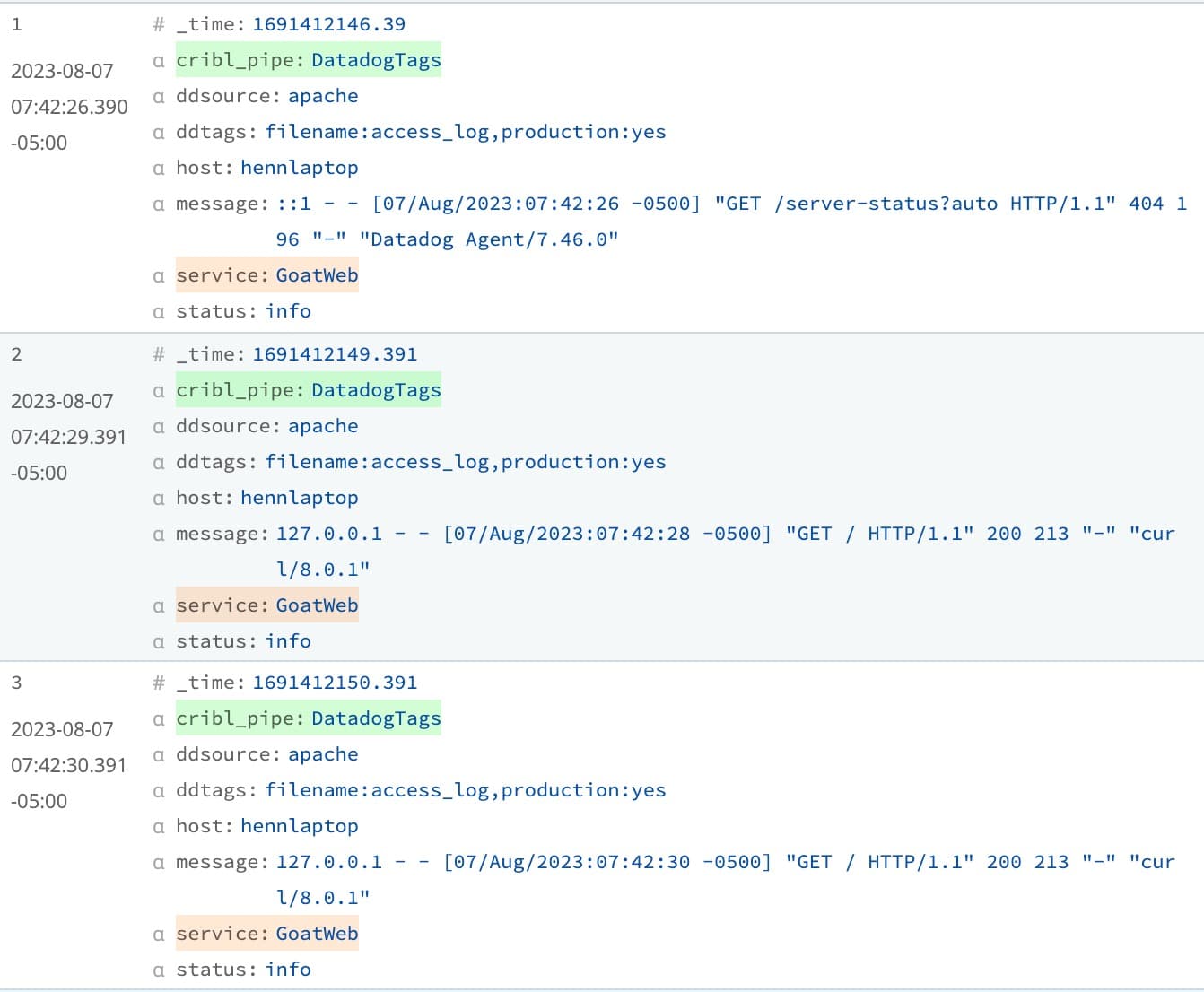
The change must be committed and deployed within Cribl Stream to apply the service tag change to any data flowing to Datadog. This functionality allows teams working with observability data to test and validate changes to the data flow and know that the correct data will show up in Datadog.
This eliminates the process of making a configuration change and having to wait for the change to show up in Datadog before verifying whether it has been correctly applied. Having your observability data flow through Cribl before sending it to Datadog also allows teams to deploy a standard configuration of the Datadog agent throughout their environment and update the tag metadata centrally within Cribl. Configuring Cribl as the observability pipeline simplifies change management processes, provides a central repository for configuration, and includes the ability to roll back changes centrally within Cribl.
To Sum It All Up
Cribl Steam is a Data Pipeline that can be deployed within your environment to simplify the collection configuration of observability data. Once in place, the Cribl Stream platform provides better introspection into the observability data collection and configuration in one central data pipeline. With all this in place, teams can focus on the observability data outcomes versus applying valuable time and effort to ensure the data is always in the correct format.
Ready to try it out? Check our Sandboxes that are cloud-hosted with their own event generators.





