

We hosted a webinar a few weeks back on using Cribl Stream to make your security operations more scalable, efficient, and cost-effective. The turnout was fantastic and, while we answered most of the audience’s questions live, we couldn’t get to all of them. So I’ll go through the questions we couldn’t get to and offer some answers. Along the way, I’ll also share the results of two polling questions we asked during the webinar.
Is the recording available?
Yes! You can find it here.
Can Cribl Stream route data to Microsoft Sentinel?
Yes, you can cribl your data into Microsoft Sentinel. Once you have Sentinel enabled in your Azure environment, you can use Cribl’s Azure Monitor Logs Destination. Here’s a link to another blog post describing the rest of the integration.
Stream does point-in-time enrichment, but what about after an indicator of compromise (IoC) becomes live after the enrichment?
If an IoC goes live after the data has passed through Stream, you can update your database and replay the data back through Stream to get the latest IoCs into your data.
How are logs packaged when you forward them to S3 for replay?
Our Replay feature is best in class. As far as data formats, we package data in open formats: either JSON or raw. JSON-formatted data represents all of the modifications made and metadata added before your data goes to its destinations. Raw data is just that – the unparsed data from the _raw field. Each event is one line.
You have several options when it comes to the file size, how long to write data, the number of open files, encryption, and so on. Unfortunately, there are far too many to list here, but our docs are fantastic.
Can I safely say you can replace our Kafka and Logstash clusters?
TLDR – Yes, Stream can replace all of your Kafka Streams and Logstash clusters.
I’ll start by answering the Kafka part of the question. As a message broker, Kafka is simply another source and destination for Stream. Stream can read from it, manipulate data, and either put the data back into another Kafka topic or deliver data to some destination, like Splunk or Elastic. Things get much more interesting if we’re talking about Kafka Streams.
Many of our customers have replaced Kafka Streams implementations with Cribl Stream, mostly due to complexity and performance challenges at the scale our users need.
Another issue is hardware. Stream’s shared-nothing architecture requires a quarter of the hardware of Kafka. This is a huge advantage and helps keep costs down.
Simplicity is another factor. Kafka Streams solutions require weeks of work by an expert, and that’s per data type. Stream is frequently set up and configured in days without professional services and is far easier to use. Check out the sandbox to see for yourself.
Now, on to Logstash. We’ve seen multiple instances of companies replacing Logstash with Stream for all of the reasons cited above.
Let’s Look At The Data
We like to do polls during webinars to ask our attendees some questions. The first question was “What is your biggest security data challenge?”
We offered four options:
Dealing with the volumes and variety of data types
Ensuring data is protected and governed
Infrastructure budgets can’t keep up with the need to store data
Can’t easily enrich data to drive analysis/research
My guess was the infrastructure budget option would win. Sadly, I was wrong on this one.
Figure 1: What is your biggest security data challenge?
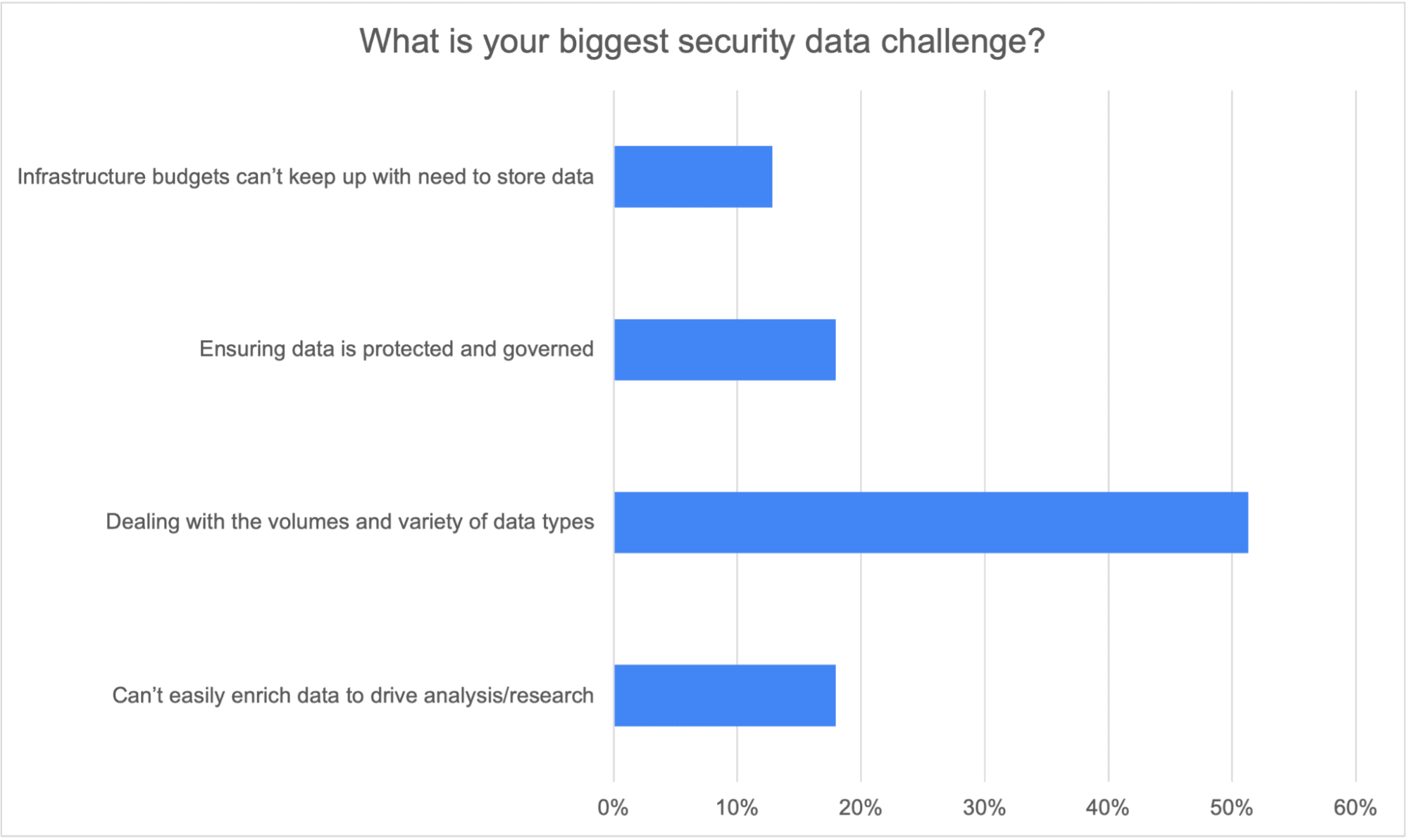
When I talked about how surprised I was by the result, somebody in the chat stated, “Nerds don’t care about budgets.” I guess that settles it.
The second question was about observability lakes. We’re seeing more of our customers build out dedicated exploration environments on top of low-cost object storage. These aren’t the general purpose “build it, and they’ll come” data lakes for data scientists and business intelligence analysts. Instead, o11y lakes target ITOps, SecOps, and SRE roles and are vital in driving the discovery aspect of observability. We asked where the audience was in building their o11y lakes, and the results were in line with what we expected.
Figure 2: Where are you in building your o11y lake?
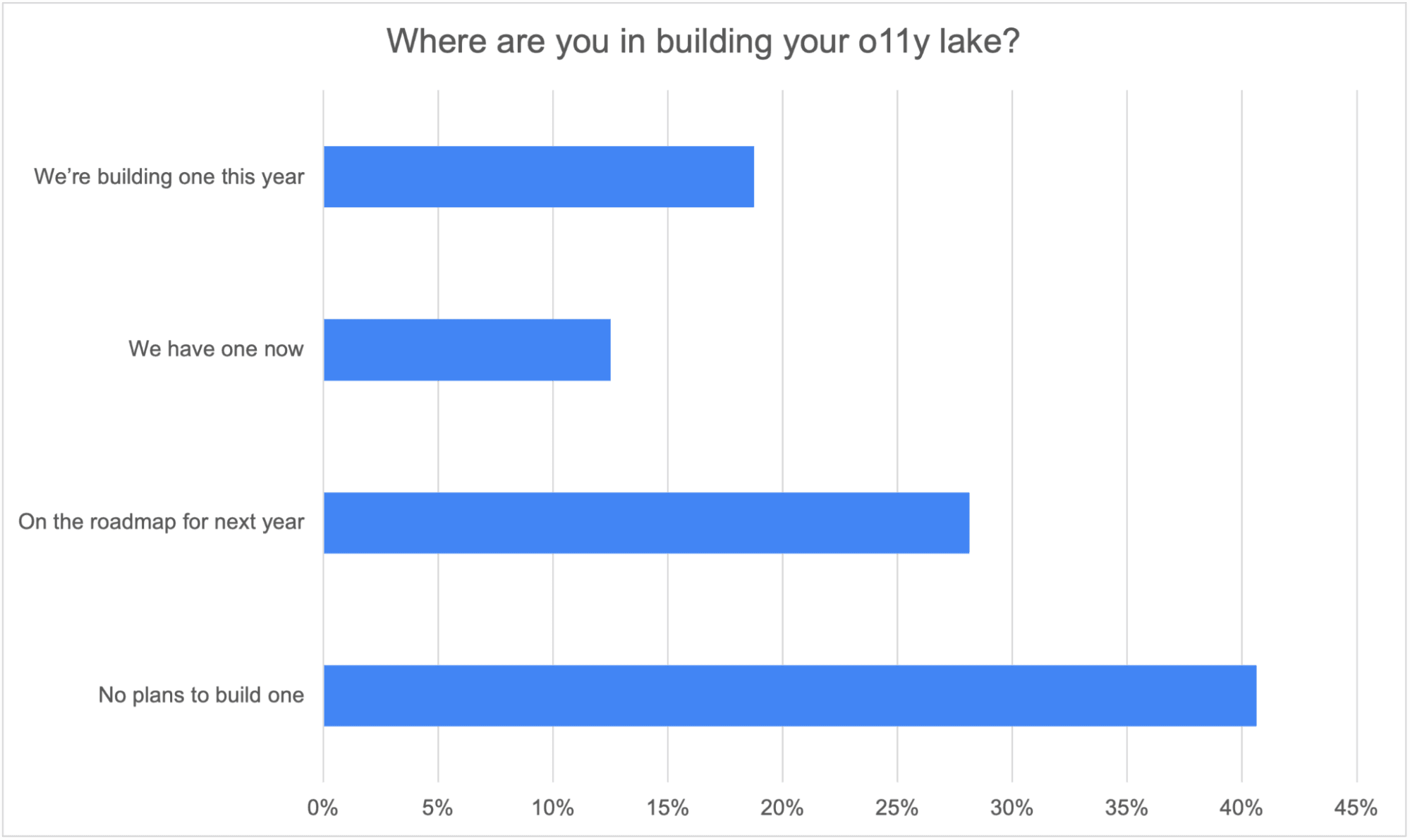
Only 13% of attendees already have a lake, but 19% are building one this year, and another 28% have it as a roadmap for next year. So I think we’ll see much more adoption for this concept than these numbers illustrate.
If you’re interested in checking out Cribl Stream, you can learn more by exploring our sandboxes, checking out Stream Cloud, or joining the community. We have over three thousand community members that can help answer questions and get you started.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.






