

“We lost choice and control when we migrated to Splunk Cloud, but got it back when we adopted Cribl Stream”
The above quote is from a new Cribl customer talking about why they adopted Cribl Stream to manage observability and security data.
TL;DR
Once your data is sent to a vendor cloud, you lose control over it
Adding a tool that is not in your existing vendor ecosystem can be complex
Cribl Stream gives you choice and control over your data and tool choices
Every engineer and architect knows what it is like to take on a project and have to compromise. Much of technical architecture and engineering is about working within your constraints to produce the best solution possible. You have to consider budgets, schedules, workload, and requirements. It gets painful and annoying when your vendors are also your constraints. No one likes it when your vendor limits your options and forces you to make choices you would not make otherwise.
Bottom line: Choice and Control with Observability and Security data matters.
DOWNLOAD NOW – Solution Brief: How Cribl Stream Optimizes Your Splunk Cloud Migration
How You Lose Choice and Control
This is a familiar story. Your security team wants to add a new capability to its security stack. You already run Splunk Enterprise Security, but your threat team wants an advanced UEBA capability. They do POVs and pick a leading platform to be its UEBA tool of choice. The security team comes to the enterprise data team to make the request to integrate the UEBA platform with your mature Splunk/Splunk ES environment. Now the fun begins because guess what? The selected tool is not part of Splunk’s supported ecosystem.
Your options to set up the UEBA platform in a Splunk environment:
Install vendor agents on every endpoint
Configure the UEBA platform to query Splunk
Forward syslog from Splunk to the UEBA platform
Let’s discuss the pros and cons of each option.
Install Agents on Every Endpoint
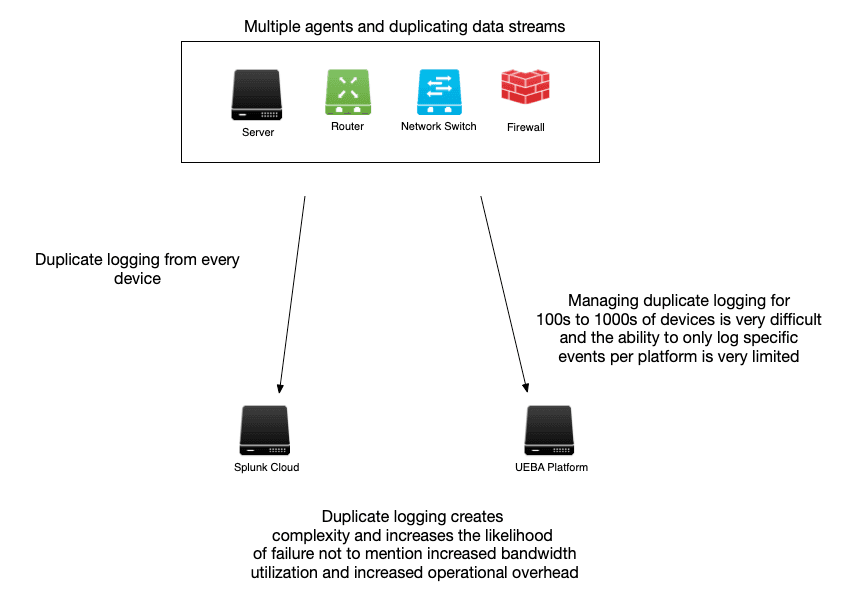
Installing 50K thousand agents is a non-starter. Your Open Systems and Windows admin team will give hard pushback on you for suggesting that they install and maintain yet another agent that sends the same data as your Splunk universal forwarder. The added effort, complexity, and data duplication are not needed by any team.
Configure UEBA platform to Query Splunk
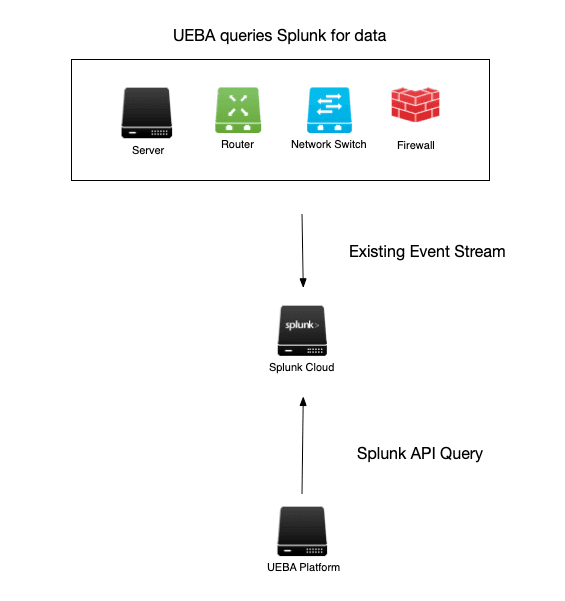
Querying Splunk for data is a workable idea, but then you introduce added load and dependency. No Splunk admin wants to add this kind of added search load to your indexers. You already have tons of user-generated searches, and now the idea of sending out the same data you have already indexed is too much. In addition, using Splunk as the data source creates a dependency for the UEBA platform to work. Basic maintenance work like rolling your indexers impacts your ability to operate your UEBA platform as well. The risk goes up for your new UEBA platform to consistently work.
Forward Syslog From Splunk to the UEBA Platform
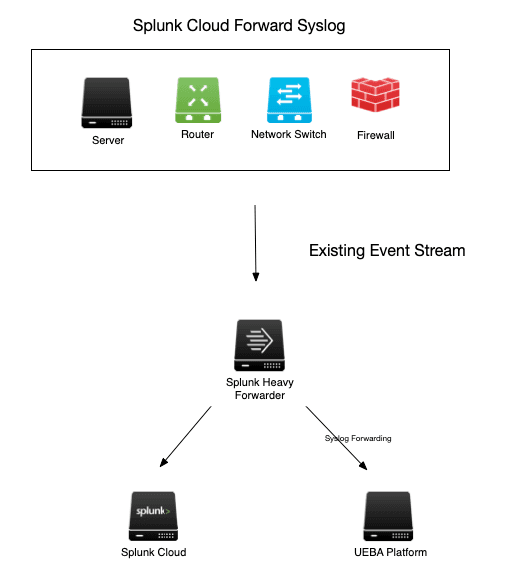
You can also forward syslog from your Splunk heavy forwarders or Indexers, but that creates issues with your UEBA platform since Splunk’s ability to forward data as syslog is messy and really struggles with multiline data like Windows events. Your admins cannot control how data is formatted in the forwarded syslog. You have to customize the UEBA’s parsers to accept nonstandard data, which will delay implementation and possibly impact detection quality in your new platform. In addition, it is painful to selectively forward data from your heavy forwarder, so most teams just forward everything, which creates its own set of problems. A partial solution that consumes engineering time and will reduce the value of your new UEBA tool.
How You Get Choice and Control Back with Cribl
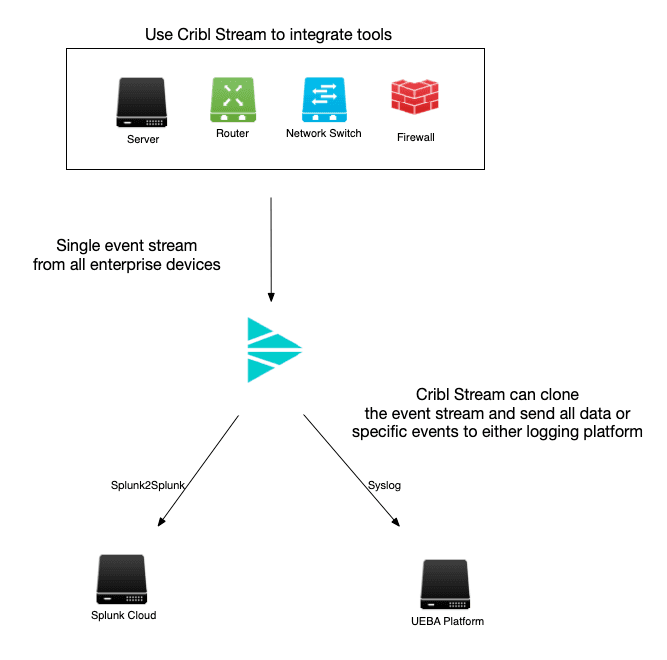
Use Cribl Stream to return choice and control to your team. See the above diagram whereby putting Cribl Stream between your data sources and your destination. You can control everything about your data and how it is delivered. You have choice and control over your data and your tools. Decouple your data ingestion layer from your data analytics tools and reduce complexity and tool dependencies.
You never need to install a new agent to ship data. Use the agent you already have to move data to all of your analytics and security platforms.
There is no need to create additional dependencies on complex systems by ingesting data into one analytics platform like Splunk Cloud and forwarding it to a third tool.
Send the right event to any number of tools in the preferred format for that tool. Better yet, do this work quickly and safely with an excellent user experience.
Bottom Line
Only Cribl Stream offers you full choice and control over your data. Simplify your architecture, get more work done with less effort, and spend your engineering time on high business value work.
Ready to unlock radical choice and control? Try Cribl’s free, hosted Stream Sandbox! I’d love to hear your feedback; after you run through the sandbox, connect with me on LinkedIn, or join our community Slack and let’s talk about your experience!






