

What’s replay? — no, not the clothing company. It’s not the catchy hit single by Iyaz either. Replay means jumping into critical logs, metrics, and traces, as far back in time as you want, and saying “let’s see that again” — replaying just the parts you need to see to investigate a security incident or unearth data for an audit. If that sounds impossible, let’s find out why… and then see how it is not only possible, but easy with Stream.
Why Should Replay Be Impossible?
Suppose your critical logs, metrics, and traces are going into the same system for both analysis and long-term data retention. It’s okay — you’ve been told to do that for years, and no one ever gave you a way to do it differently. But, unfortunately, the systems used in this way don’t offer replay capabilities because search is not their strong suit. So in that status-quo world, the idea of replay sounds impossible.
But now there is another way. It works like this:
Your analytics systems continue to do their thing as usual.
Meanwhile, Stream stores all those critical logs, metrics, and traces cheaply, in a vendor-agnostic format, in object storage.
Whenever required by investigations, audits, or security events, Stream re-ingests the relevant data right back into your analytics system(s).
You replay the data you need to analyze with full fidelity.
That is Stream’s Replay feature — in effect, it gives you the ability to rewind time. It also improves the performance of your analytics systems by letting them do more of what they do best.
How Powerful Is Stream Replay?
Need to look for events that are no longer available in your system of analysis? No problem.
Need to replay data to a new index to investigate a security incident? No problem.
Need a month of data to load into some new tools you are researching? No problem.
Let’s show you how it’s done!
The Big Idea
Suppose you always had a full-fidelity copy of your logs, metrics, and traces available in S3. Ask yourself this: Would you still bring every single event into your analytics systems? Would you truly need to keep terabytes of noisy, verbose, hard-to-search logs in your expensive analysis tools every single day?
At Cribl, we recommend that our customers separate their system of retention from their system of analysis. Stream helps them do just that — quickly and easily.
Separating retention from the analysis is a big idea that makes replay possible. As soon as you put this concept into practice, you can ask yourself some pretty interesting questions:
Now that you are optimizing the data you ingest, how much more licensing room do you have, and how much more critical data will that let you ingest?
Would it make sense to sample or aggregate certain datasets before sending them to their destination(s)?
Knowing that you can always bring the original data back from S3 object storage, would it be logical to suppress or even drop certain data entirely?
With Stream, you can quickly explore these questions and put the answers into effect. Your analytics system will thank you.
Storing Data in an S3 Destination
Now, what about these S3 destinations? S3-compatible object storage includes AWS S3, Azure blob, Google Cloud Storage, MinIO, file system locations, and more.
When setting up destinations, we highly recommend reviewing the partitioning expression for how files are partitioned and organized. This will increase your ability to filter during Replay scenarios and decrease the wait time for pulling many/all buckets from your S3 sources. This can potentially save you $$$ in egress costs as well. Data can be stored in json or _raw formats and compression options for gzip can save you approximately 10:1 compression ratio on your data being written to S3.
Example Partitioning Expression: Very few fields to use later for filtering during Replay.

Example Partitioning Expression: Customized for VPCFlow logs, AWS account/regions, time of year, month, and day.

Replaying Data From an S3 Destination
Now that you have stored your data in an S3 destination, we’ll set up a new Collector to pull it back into Stream. We’ll even filter down to just the data you need for the collection. Then we’ll create a Route to handle the dataset and send it to whatever destination(s) you need.
Stream Collectors can be used on an ad hoc basis. Or, you can schedule ingestions or automate them via API calls from tools already deployed in your environment.
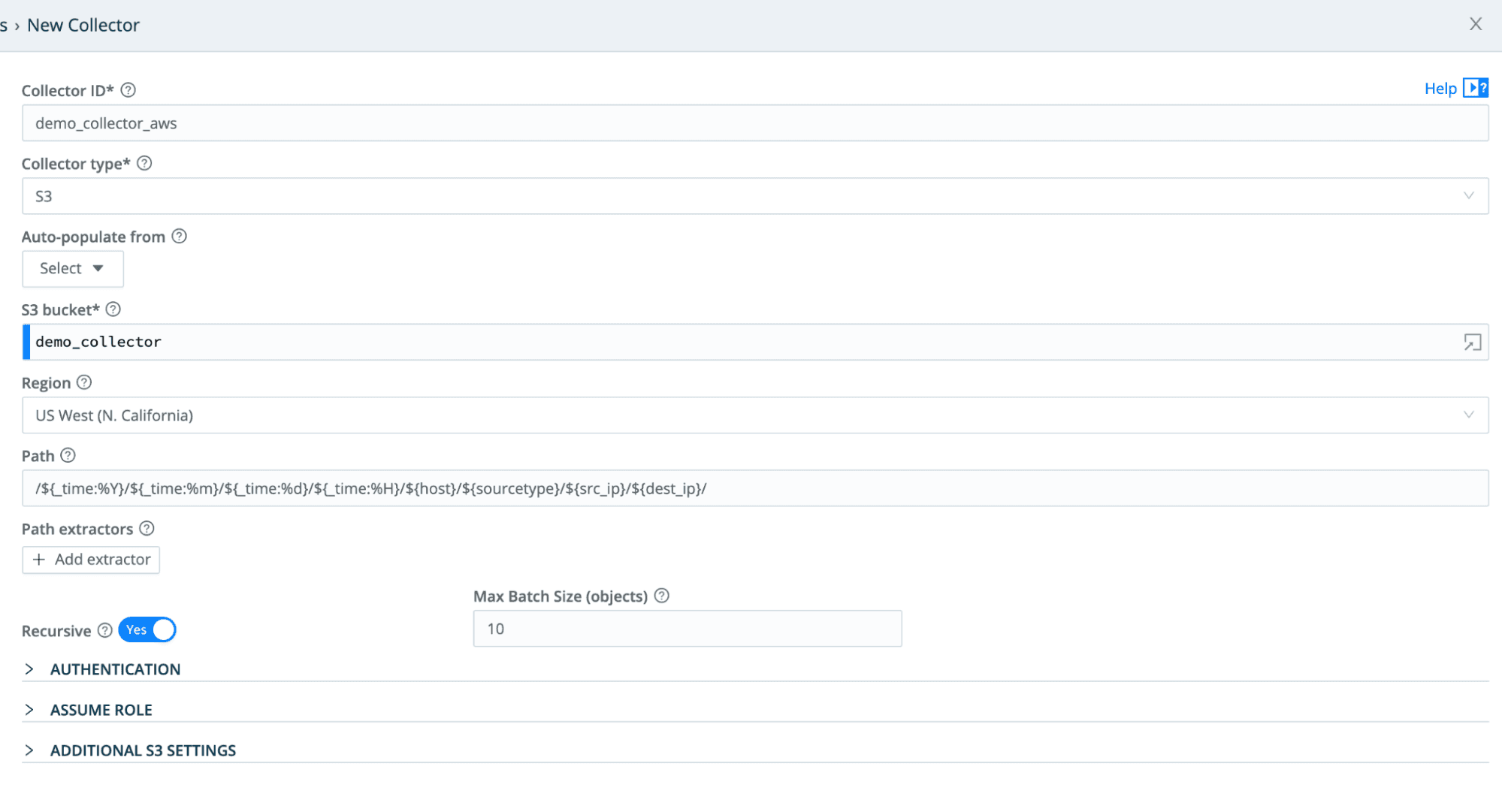
With Stream Replay, “let’s see that again” is not only possible; it’s simple and flexible.
Try Replay in Our Cribl Sandbox Environments
Cribl’s Sandbox courses on these and other topics are always free. In only a minute, you’ll spin up Stream and see how easily you can use the S3 options for data storage, collection, and replay. Follow along at your own pace, and learn why this is such a game-changer for our customers.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.






