
AWS Fargate is an interesting service in that it allows you to run containers without having to think (much) about cluster management, task scheduling, instance provisioning etc. It transforms the application deployment process into one where the application is packaged into a container and resources (CPU, RAM, Networking, access policies etc) are defined as part of a Fargate task. As such, it’s an attractive option that we’re evaluating as a deployment foundation for Cribl labs.

A Fargate task/container can be configured with a vCPU range of 0.25-4 and a RAM(GB) range of 0.5-30. As it’s typical of us, we went ahead and analyzed its physics to get a better understanding of what we’re dealing with. We have also done a similar analysis on Lambda.
We were specifically interested in the following measurements:
IO :: Are latency and iops affected by CPU and RAM allocations?
Network :: Is throughput from S3 related in any way to CPU or RAM allocations?
CPU :: How do various configurations affect compute (gunzip performance)?
Container Ready Time :: How long does it take for a task/container to be ready?
Note that at this point we are not interested in the absolute performance of Fargate instances. We want to primarily get an understanding of their performance relative to each other; feel free to ignore the y-axis units.
Testing and Analysis
IO
Test: Run fio (direct IO, non-buffered) with block sizes of 1k, 4k, and 8k, across instances with these vCPUxRAM(GB) configurations: 1×2, 2×4, 4×8, and measure iops and clat perc95 .
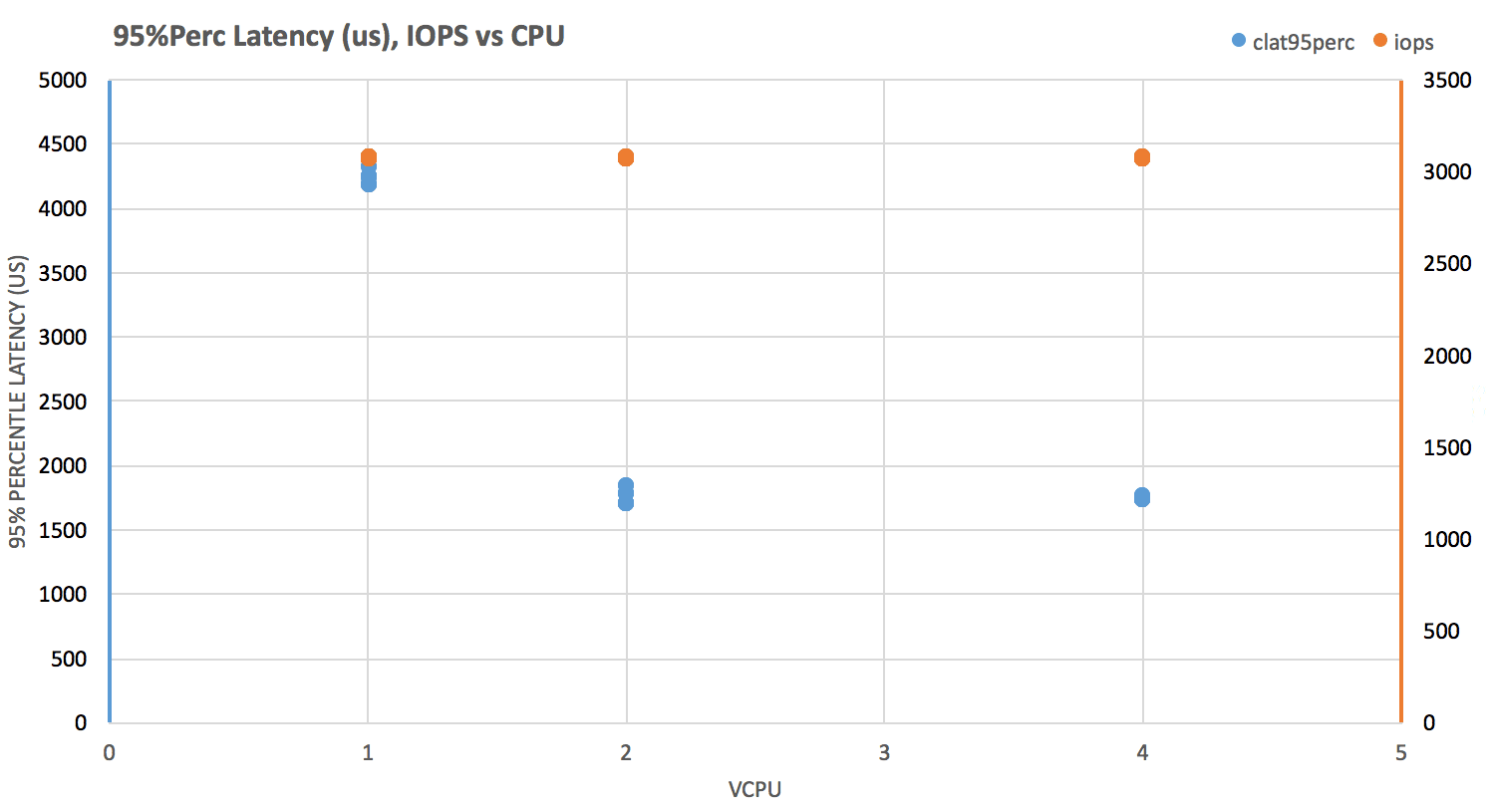
IOPS are pretty consistent across all instances. Their almost-perfect stability at just a tad over 3000, indicates that disk is served by EBS.
Latency seems to be affected by vCPU allocation. Small instances hover between 4-4.5ms and larger ones clock significantly better, between 1.5-2ms
Network Throughput
Test: download a file from an S3 bucket using curl to the local filesystem across instances with these vCPU x RAM(GB) configurations: 1×2, 4×8, 4×16, 4×30 and analyze throughput (wall clock time was used)
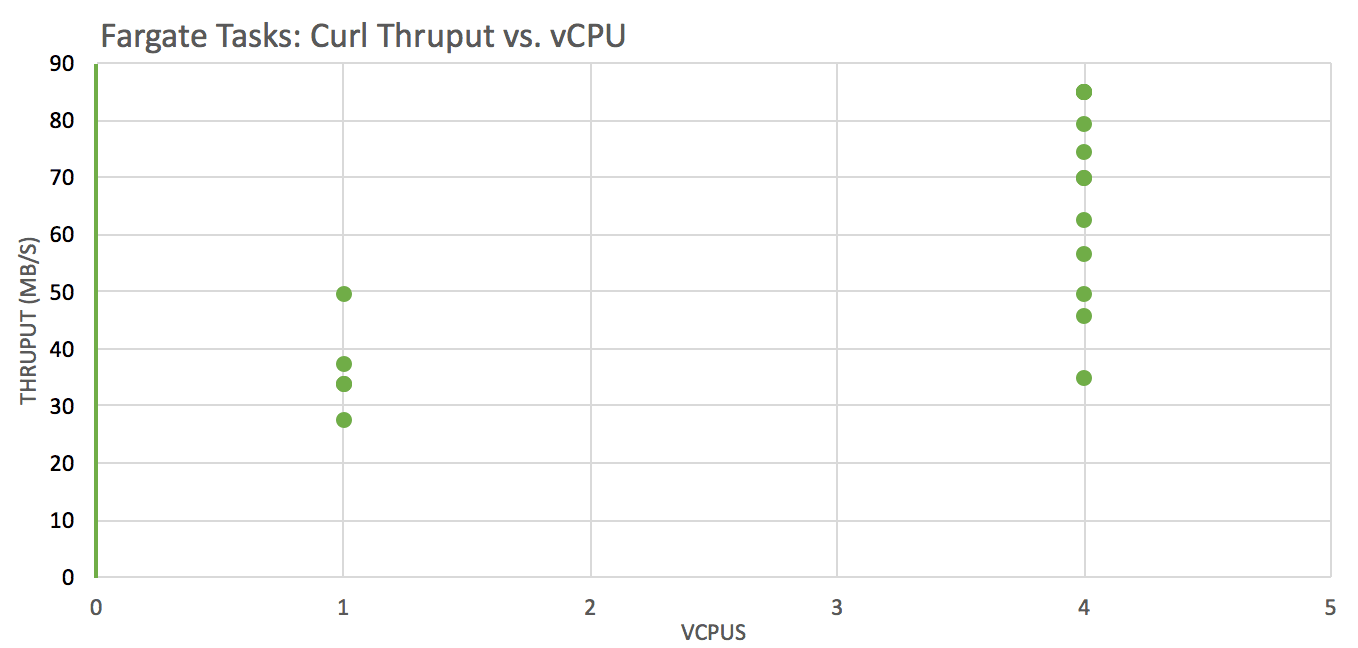
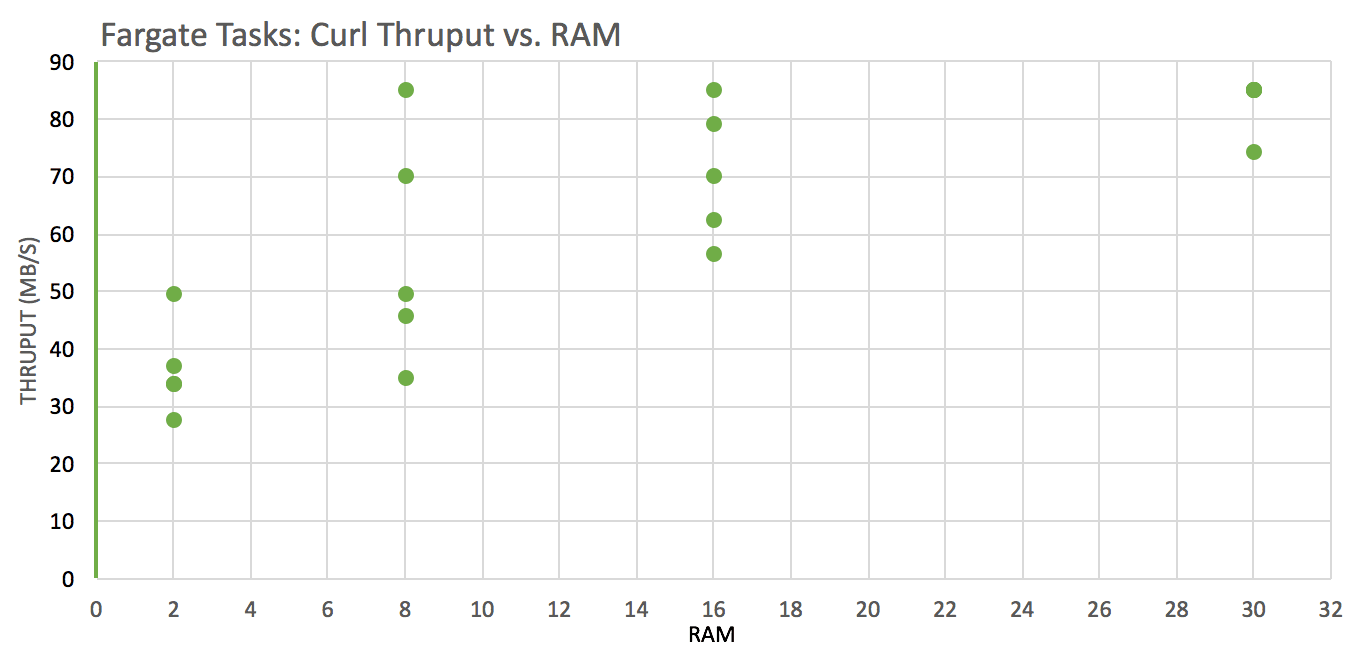
Network throughput is significantly better on instances with more vCPUs
Network throughput and variability tend to be better on instances with more RAM.
CPU Performance – Gunzip a Compressed File
Test: gunzip a local file across instances with these vCPU x RAM(GB) configurations: 1×2, 4×8, 4×16, 4×30 and analyze throughput (compressed file size / wall clock time was used)
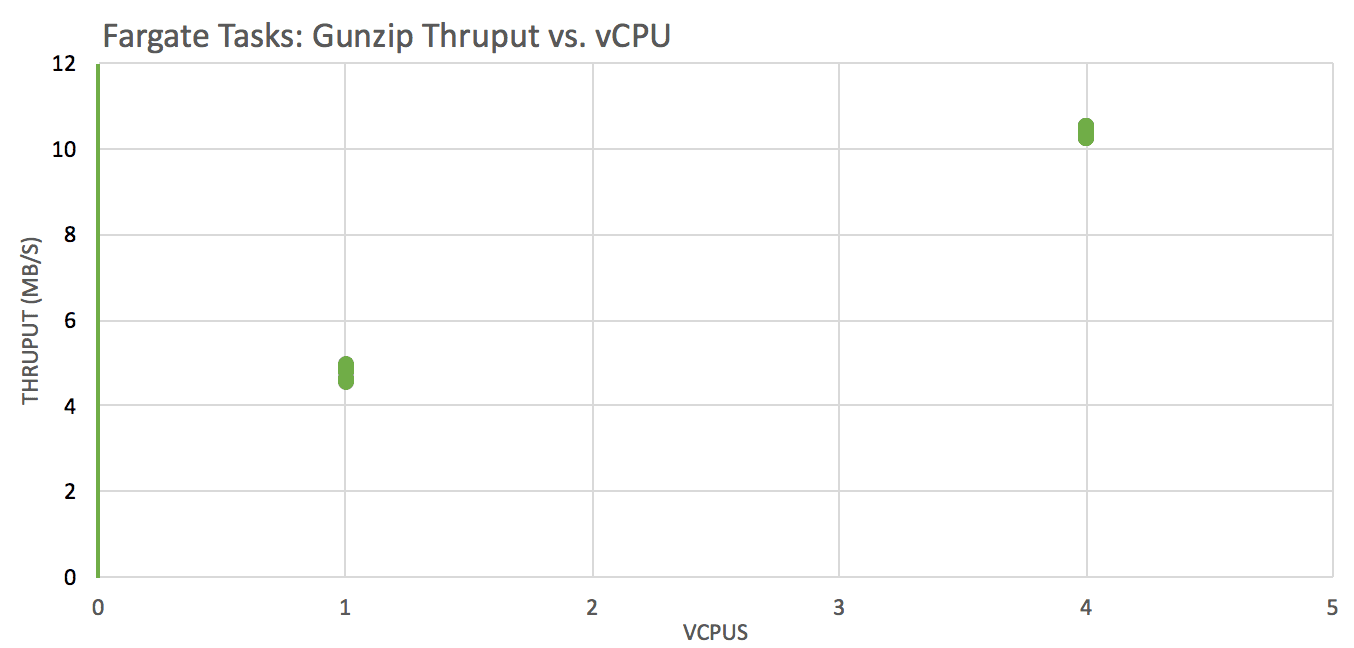
Decompression performance is significantly better on instances with more vCPUs (we expect a step at 2 vCPU, ie a real core)
CPUs are ~5 year old toddlers Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz 🙂 … this fact + memory / vCPU ratio indicate that Fargate is powered by R3 instances.
Container Ready Time
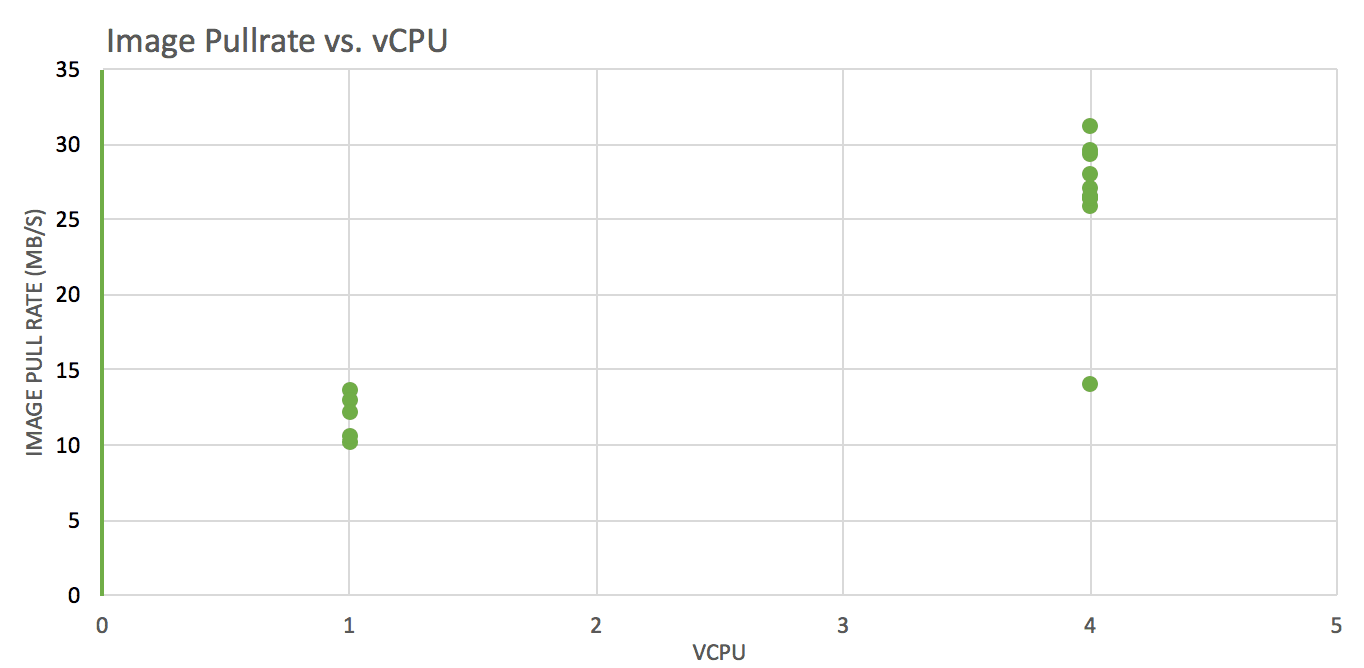
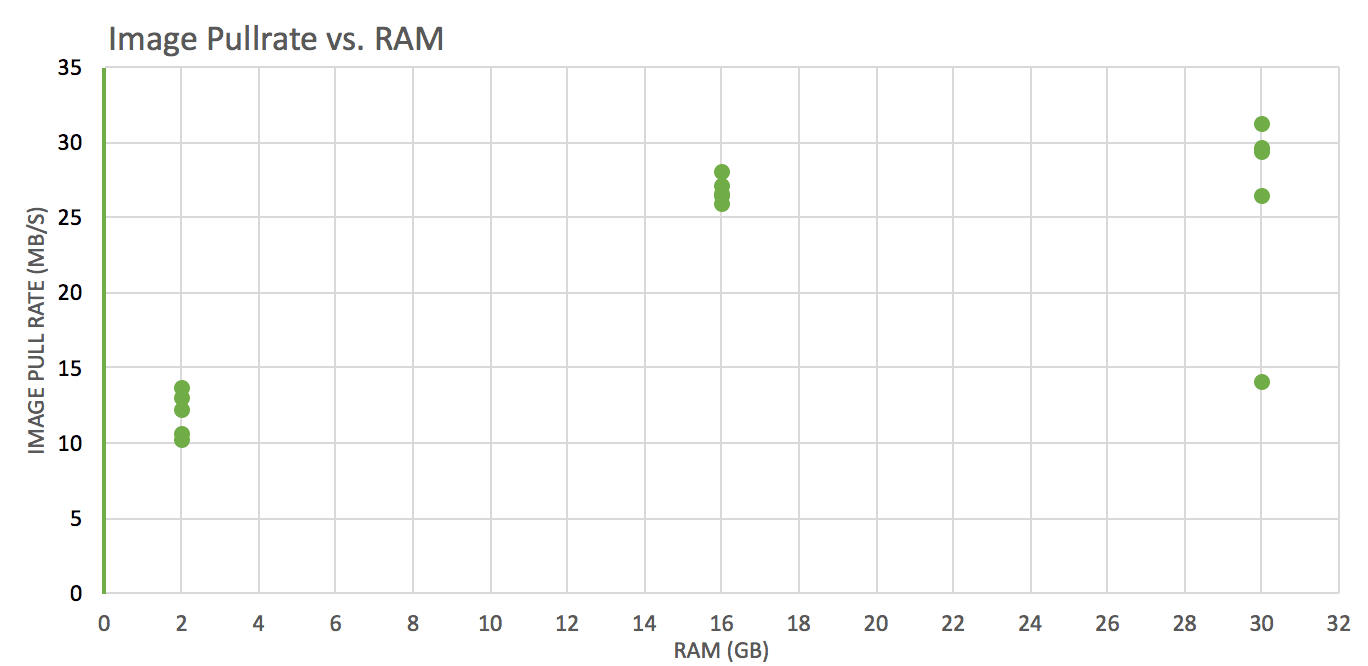
Test: pull images of various sizes from ECR, track pull time, convert it to throughput (imageSize/Pulltime) and see how it varies against different vCPUs and RAM(GB) allocations (1×2, 4×16, 4×30).
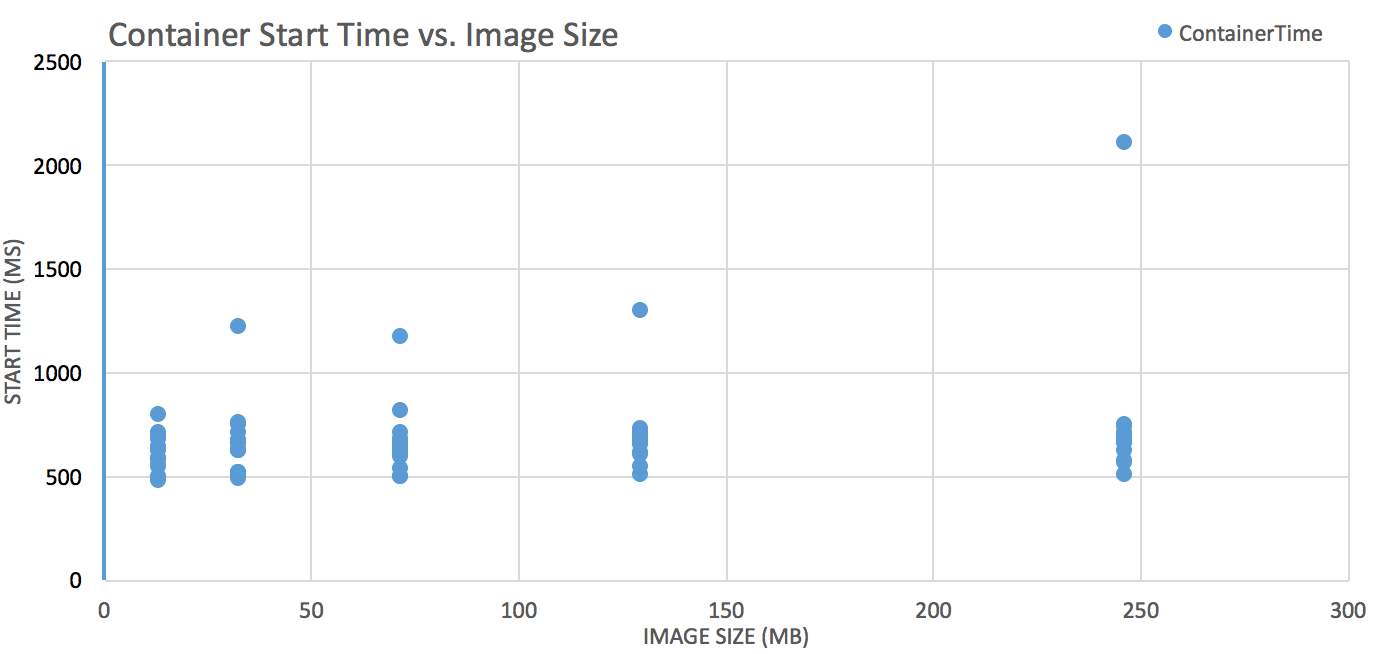
Note: Container Ready Time can be approximated as:
Task request/scheduling time + image pull time + container startup time
Task Request/scheduling time, not shown in charts, ranged from 11-39s
Container startup time is consistent across the board, hovering around 500-700ms.
Image pull rate is significantly better on instances with more vCPUs
Image pull rate is worse for instances with 2GB RAM than those with 16GB or 30GB
Overall Conclusions:
Instance vCPU count seem to govern the network performance more so than RAM
More vCPU = Better
Instance RAM impact on overall performance plateaus over 8GB;
More RAM = Better (but less so than more vCPUs)
Image size matters
Smaller = better

How will these findings affect our architectural design?
Given a container ready time in the neighborhood of ~1 minute (or multiple-tens of second), we’ll have to consider a pool of warm/standby containers in order to minimize wait and response time for our tasks.
Given the performance charts (storage latency, network and CPU decompression throughput), we’ll very likely consider a system with fewer larger instances than one with a lot of smaller ones.
The fastest way to get started with Cribl LogStream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using LogStream within a few minutes.







