

Here at Cribl, we’re big on GoatFooding. We not only prepare but consume our own products, in our own products. Today we’ll pull back the curtains to shine a light on how we use Cribl products within our Cribl.Cloud service.
Cribl is a pioneer in the observability space, so what better way to use our products than by observing Cribl.Cloud? By GoatFooding AppScope in our service, before it was generally available, our Cloud development team was able to provide instant and useful feedback to the AppScope development team and collaborate on new features.
Similarly, we integrated Cribl Edge with Cribl.Cloud early on, and at a scale that tested the limits of its capabilities. Managing Fleets of thousands of Edge Nodes gave some critical insight into the problems that our customers face and helped us stay ahead of the curve.
Design Philosophy
The following rules helped establish the principles upon which our whole design system is built:
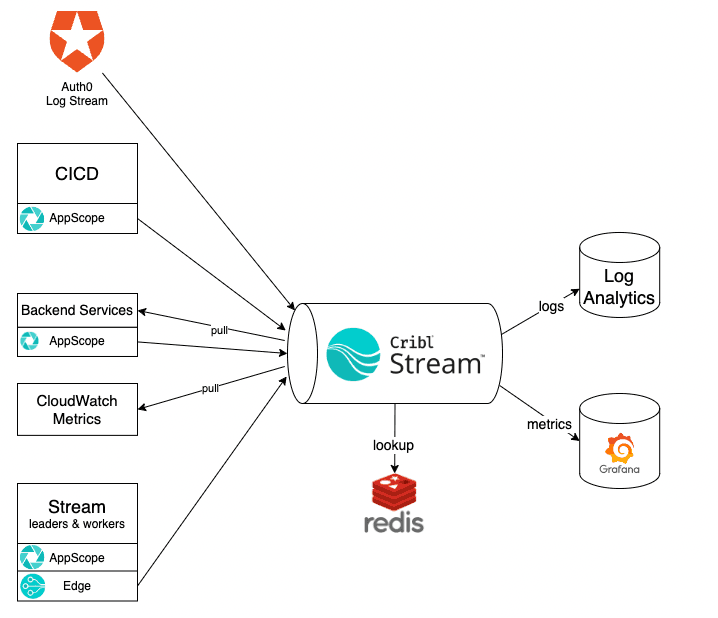
Route all observability data through our Cribl Stream cluster.
Use AppScope or Edge to integrate push sources.
Use pull sources in Stream to gather data that can’t be pushed.
Fallback to other agents/collectors when there’s no other option.
Use Stream Packs to manage the configuration of pipelines.
Implementation Details
Cribl.Cloud Observability
Wherever possible, we use AppScope to integrate directly with our Stream observability cluster. The main advantage of this is that we immediately get access to all the pre-packaged metrics that AppScope gleans from its environment. In an HTTP server, this means we have instant access to latency, traffic, and error metrics. That’s three of the four Golden Signals covered without any work. Who else loves not doing work?
Within Stream, we don’t use global configuration. All configurations are contained within Packs. Additionally, sources deliver data directly to Packs rather than through global routes. This layout has the following advantages:
More Packs with meaningful names gives context and purpose.
Packs isolate handling for different types of data. It’s easier to update Routes and Pipelines inside a Pack without affecting other data.
Using Packs reduces the number of Routes and Pipelines on the Worker Group’s Routes and Pipelines pages.
If we ever need to move data to another Worker Group, we can just set up the source and destination, and then export and import the Pack to the new Worker Group.
We maintain two Edge Fleets per environment: one for Leaders and one for Workers. Because each role has a different lifecycle and configuration, separating them in different Fleets enables cleaner management of configuration and improved ease of deployment.
We use Redis via AWS ElastiCache to store enrichment lookup data. Stream Collectors periodically load this lookup data from its source of truth. The Pipelines then use the data to enrich metrics and logs with additional dimensions or index time fields.
One example of this is within the metrics coming from Stream Leaders and Workers. We have a population of free and enterprise licensed organizations in the environment. Knowing the unique identifier of the organization the metrics are coming from allows us to look up the license and add it to the metrics as its own dimension. Dashboards and alerts can then be customized downstream to distinguish between the two populations.
Wrap Up
Developing the Cribl.Cloud observability system while GoatFooding our own bleeding edge has been an eye-opening experience. There were times when we were unable to do what we needed because of missing features in one of our dependencies. However, moving forward in lockstep has allowed us to build a more cohesive system that just works and integrates seamlessly.
Interested in Cribl.Cloud? We’d love to have you come check out our offering. Sign up here.






