

In this post, we’ll walk through our journey of launching Cribl Stream Cloud on AWS Graviton instances. In order to put our journey into perspective, it is worth spending a few moments to describe the product and its resource requirements.
Cribl Stream is our first product to be launched as a cloud service. Stream is a streams-processing engine specifically designed for observability data (logs, metrics, and traces). Stream allows you to implement an observability pipeline, helping you parse, restructure, and enrich telemetry data in flight – ensuring that you get the right data where you want, in the formats you need. It natively supports receiving data from, and sending it to, over 50 sources and destinations, including Amazon S3, Amazon Kinesis Data Firehose, Syslog, Elastic Cloud, Splunk, New Relic, etc.
From day one, we had two key architecture design requirements for Stream: a) resiliency and b) resource efficiency. Customers depend on data successfully passing through Stream to gain operational visibility into their systems and applications, making resiliency an obvious requirement. According to the IDC, observability data is one of the fastest-growing (25+% CAGR) data sources in the enterprise, and the systems used to collect, process, and store that type of data can have a tremendous infrastructure footprint. A resource-efficient solution allows customers to minimize their infrastructure costs.
As a streams-processing engine, Stream is primarily CPU- and secondarily network-bound. The vast majority of the CPU cycles are spent deserializing received data, processing it, and ultimately serializing it out to one or more destinations.
When designing our Stream Cloud offering, our resource-efficiency key requirement needed to be updated. In a cloud environment, resource efficiency is not sufficient. A solution also needs to be cost-efficient, including: choosing the right architecture, proper sizing, and designing for elasticity.
With cost in mind, we started researching and profiling Stream on different AWS instance types, including Intel (c5, m5zn), AMD (c5a) and AWS Graviton2 (c6g) instances. Our findings indicated that under high load, on-demand AWS Graviton2 (c6g) instances would provide 45%, 24%, and 217% better price performance when compared to c5, c5a, and m5zn instances, respectively. (Note: m5zn instances were included in the test primarily because of their high clock frequency.)
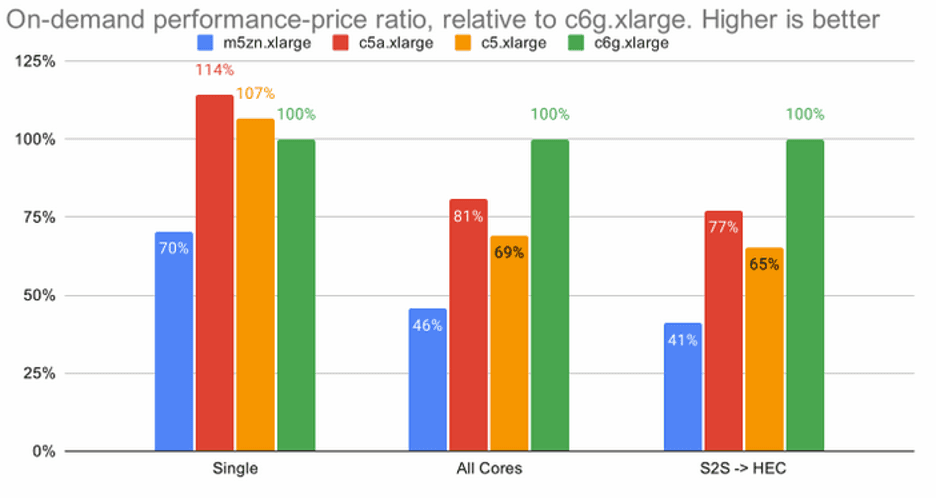
The savings above, when combined with the 15–20% savings on completely idle instances, were great incentives for us to ensure that Stream ran natively and optimally on ARM64. To that end, we had to make two changes:
Stream on ARM64
Stream is built on and shipped with the NodeJS runtime. In order for it to run on AWS Graviton2 instances, we had to make sure to compile NodeJS for ARM64, and update our packaging scripts. That took us around 1 man-week, with most of that time spent troubleshooting build pipelines that failed after running for 1+hr…the joys of release engineering 🙂
Proper CPU utilization
A key difference between AWS Graviton2 instances and their x64 counterparts is that on AWS Graviton2 a vCPU is a physical core, while on x64 a vCPU is mapped to a hyperthread. When deciding the scale-up factor, Stream detects the number of vCPUs and, by default, spawns max(N-2,1) worker processes – with the heuristic here being to reserve some resources for the OS.
However, on instances with lower numbers of vCPUs, this heuristic would leave more resources unutilized on AWS Graviton2 instances. Changing this heuristic was the only change we had to make to the Stream codebase to improve AWS Graviton2 support.
Burstable Performance Instances
Having launched and operated our service for a few months, we now have instance utilization data to make a better decision on how to better optimize costs. Our analysis showed a workload profile that would benefit from burstable performance instances. These instances provide a lower price point for a dedicated baseline performance with the ability to burst, at a premium. To understand the performance characteristics of these instances we ran the “All Cores” test from above on t4g.medium and t3/a.medium, in unlimited mode. We found that t4g.medium instances have the same performance as their c6g.large, indicating that they’re powered by equivalent/same underlying hardware. However, the performance of the t3/a.medium instances is not comparable to that of the c5/a.large instances – likely attributed to the difference in CPU families used. The results are summarized in the chart below.
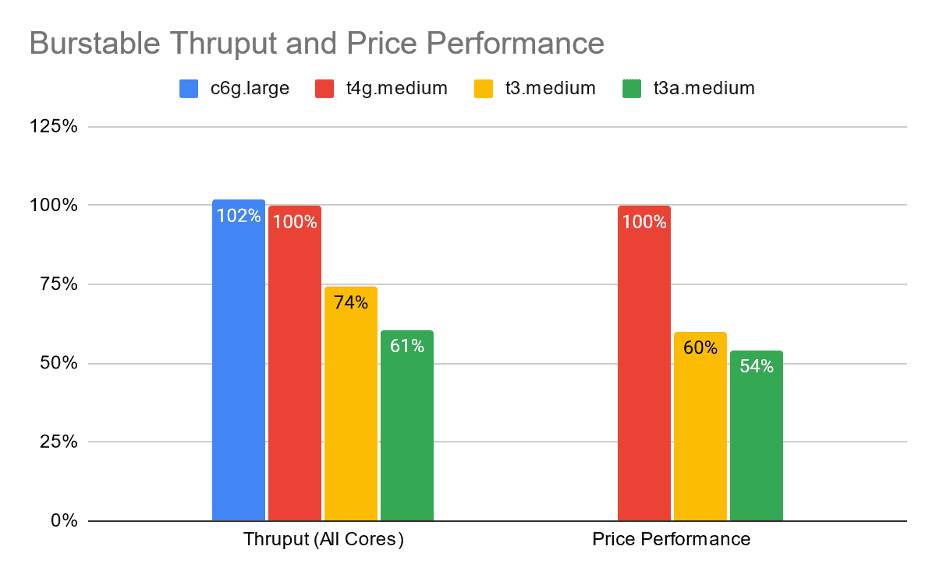
The above analysis drove our decision to switch to using burstable performance instances, a decision which reduced our infrastructure spend by ~20% (over the compute optimized instances).
Most recently, Cribl has announced that we’ve achieved the AWS Graviton Ready designation, part of the AWS Service Ready Program. This designation recognizes that Cribl has demonstrated a successful integration with AWS Graviton and adherence to AWS best practices, along with demonstrated customer success. We estimate that our decision to launch Stream Cloud on AWS Graviton2 will reduce our overall infrastructure costs by ~10%, which we’ll pass on to our customers.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







