

The problem
On distributed LogStream deployments that can span hundreds of nodes, it becomes a critical feature to be able to upgrade all the nodes to the latest version in an automated fashion – without having to upgrade each node one by one, or leverage bash scripts to automate the upgrades. Here, we discuss how we leveraged our internal jobs framework to automate worker node upgrades.
Some background
At first, we tried to implement this feature as a part of the distributed communications framework we’d developed for Leader–Node communications. But the problem of monitoring the upgrade, and having some sort of control over the process, demanded a more robust solution.
Jobs framework
We ultimately decided to run the upgrades through the jobs framework, writing a custom job executor to perform the work on the worker nodes’ side.
Job executors are JS modules that consist of a few functions – describing how tasks behave, and what action is to be taken upon the results of each task – bundled with any initialization.
The design consists of a soft control layer on the leader node, which invokes jobs on a set of nodes belonging to a worker group. This allows us to control the progress of the upgrade, to do rolling upgrades, and so on.
Blog post on Job scheduler/dispatcher
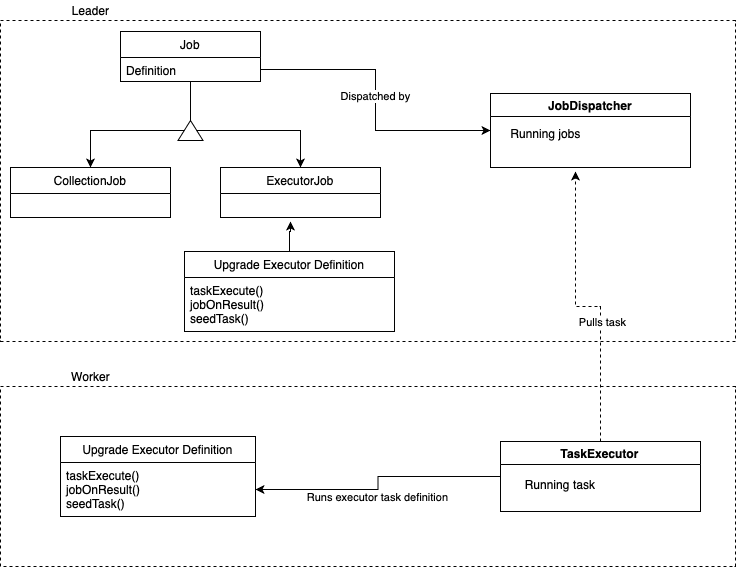
The process
When an upgrade is initiated, first the files are pulled to the leader node and verified for correctness. Once this is done, an “upgrade job” is kicked off over a set of nodes to be upgraded. Each node then runs a task on the job that pulls the files from the leader node, verifies them for correctness, applies the upgrade, and finally restarts the node for the upgrade to take effect.
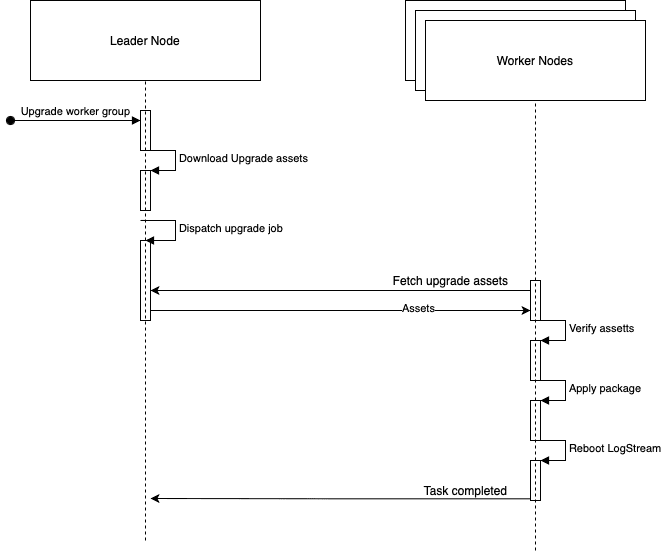
Robustness
To add a layer of safety each time a node is upgraded, LogStream creates a backup with the current binary and default config. In the case of a failed upgrade, an auto rollback mechanism is triggered, setting everything back to the way it was before the upgrade.
Rolling upgrades and partial upgrades
By leveraging the job executors we were able to customize how the upgrade process is carried out. One of the key requirements was the ability to do rolling upgrades, performing the upgrade over x amount of nodes at a time while verifying the upgraded nodes are up running before continuing with the process, to this end we added the ability to filter which nodes get upgraded by a job enabling the possibility of partial upgrades, after that all we had to do was to add thin control layer over the jobs to divide the nodes in jobs and kick off them off sequentially as they finish, and voila distributed rolling upgrades.
Observability
We needed to provide a layer of control and observability over the upgrade process. Lucky for us we already had a framework that provided most of this functionality the aforementioned jobs framework, the framework is basically a set software elements that enable the system to perform batch tasks in controlled and isolated manner, it was mainly designed for data collection but the executor jobs allow us to perform any generic tasks on worker nodes in a batch fashion, applying this to upgrades we got a lot features we needed for free like, isolated execution logs, status tracking, and the ability to cancel/pause the upgrade, also all of the ui built for jobs that allow us to troubleshoot easily any issues that occur with a failed upgrade.
Wrapping up
Working with distributed applications is very hard making it essential to build software components that can address the distributed aspects of a system in a generic way so that it provides basic functionality that can be exploited when building complex features such as a distributed upgrade, using the jobs framework to perform this task saves us a lot of work in observability and control, but also provided a framework in which we were able to incrementally build the feature, releasing it chunks and making it available sooner to our customers.
See for yourself – get started by signing up for Cribl.Cloud and try LogStream today for free.






