

Harvard Medical School explains “empty calories” as food that provides primarily calories, and little else of value to our health. Observability data sent to Splunk actually has “empty calories” in the form of log data that, while taking up storage and requiring processing power, do not provide actual value to the health of your business. A strategy for maximizing the return on your investment in Splunk infrastructure is not unlike strategies used to be healthier human beings – reduce and avoid “empty calories”.
If the right observability pipeline is employed, administrators can see an average of 30% reduction in log volume, therefore, seeing an improvement in Splunk utilization just by getting rid of fields that do not contain any useful data at all before they get to Splunk. Using the simple steps in this blog, we’ll show you how to reduce your log volume without exposing your organization to compliance problems.
According to IDC’s GlobalSphere Data Forecast, the world is going to create, capture, copy, and consume over 59 Zettabytes of data in 2020 – the equivalent of filling up a Terabyte hard drive every single day for 161 MILLION years! This statistic will only continue to increase as well; IDC projects a combined annual growth rate of 26% YoY through 2024. With this tremendous growth of data in motion, it’s only a matter of time before the tools designed to help manage and understand our large-scale distributed systems begin to also balloon and become prohibitively expensive.
It’s no secret that Splunk provides one of the most comprehensive observability experiences in the industry – this is why they’ve consistently been named a leader in data analytics. Splunk is known for ingesting data from multiple sources, interpreting data, and incorporating threat intelligence feeds, alert correlation, analytics, profiling, and automation/summation of potential threats. While all of these features are necessary to build a comprehensive Observability practice, they also put tremendous pressure on capacity and budget. Splunk is a critical infrastructure to their customers and partners with them for the long-term typically with a fixed cost over many years. The goal of every administrator is to maximize the value of that investment by getting the most valuable, most diverse set of data into Splunk for analysis as possible. But often because of “empty calories” that goal forces trade offs between costs, flexibility, and visibility. The real question is, what can be done to increase the amount and diversity of valuable data delivered to Splunk without impeding growth or security?
With a little bit of work and help from an observability pipeline like Cribl Stream, administrators can typically trim less valuable data dramatically by following these 5 simple steps:
Filter out duplicate and extraneous events
Route raw, unfiltered data to an observability data lake for later recall
Trim unneeded content/fields from events
Condense logs into metrics
Decrease operational expenses
Filtering Out the “Empty Calories”
The first and easiest option to get the most out of your Splunk investment is to filter out extraneous data that is not contributing to insights. By employing a simple filter expression, an administrator can reduce the unneeded data destined for Splunk in the first place. You can apply the filter to drop, sample, or suppress events. All of these filtering options can be configured based on meta information, such as hostname, source, source type, or log level, or by content extracted from the events, or both.
Dropping: 100% of this type of data is discarded or routed to a cheaper destination
Sampling: If there are many similar events, only 1 out of a defined sample set is sent to Splunk
Dynamic Sampling: low-volume data of this type is sent to Splunk, but as volume increases, sampling begins
Suppression: No more than a defined number of copies of this type of data will be delivered in a specified time period
In addition to reducing the number of events sent to Splunk, this filtering also creates space in Splunk for a greater diversity of sources which ultimately leads to more accurate analysis and better business value. It’s worth noting here how ‘empty calories’ are especially costly since indexed data takes approximately 4X more space to store than raw machine data, and it is a good best practice to deploy Splunk for high availability, which usually replicates the indexed data 3 times. This means that for every bit of data sent to Splunk, it takes 12X more resources to store it there compared to inexpensive object-based storage of raw, unprocessed data.

Raw Data Never Goes Away: Using the Most Cost-Effective Destinations
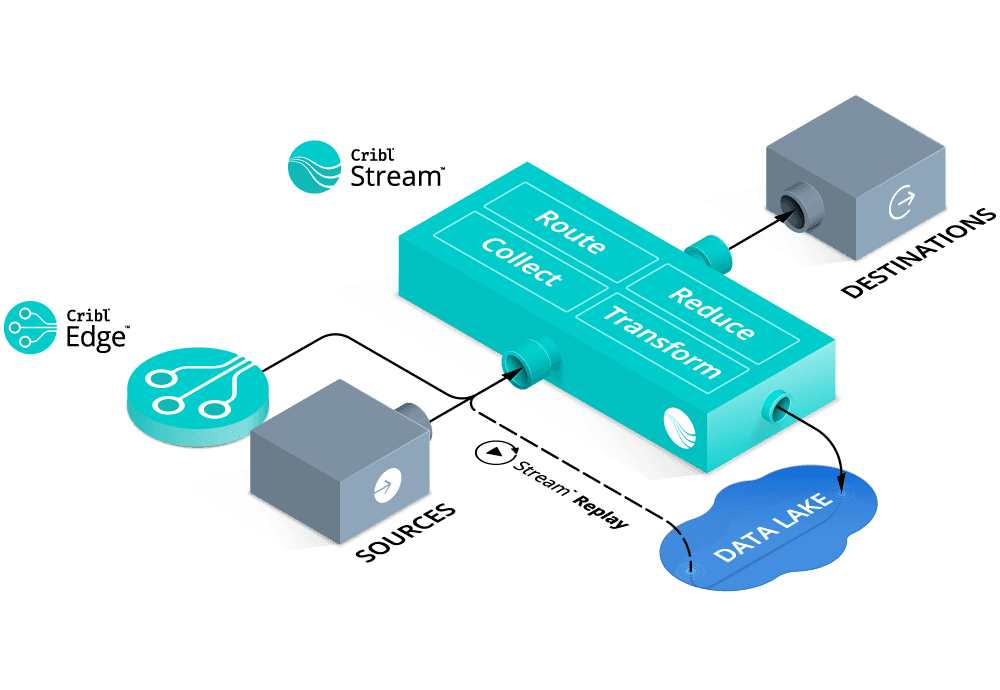
One might ask, “but doesn’t discarding data, while maximizing the ROI of my Splunk investment have the side effect of discarding data I may need for compliance or other purposes?”. The answer is a simple “no”. A well-formed observability strategy includes an observability data lake AND an observability pipeline with the capability to replay data from that raw data object storage. Cribl Stream can “multi-cast” data from any source to multiple destinations allowing pre-processed data to be routed and stored in less expensive object storage.
As mentioned above, indexed storage can take about 12X the resources as object storage – a very bad thing for ROI if those resources are spent on ‘empty calories’. Another easy way to maximize the ROI of Splunk is not to discard the raw data but to route it to a more cost-effective location “just in case”. An important enabler here is the observability pipeline’s ability to multicast the data to both the system of analysis, Splunk, and the system of retention, which can be an inexpensive storage option, such as S3 or MinIO. These stores are generally pennies on the dollar compared to indexed data in block storage, and allow administrators to capitalize on the lower cost and increased compression ratios while still complying with data retention requirements.
This strategy for observability data also allows an administrator to retain a full-fidelity copy of the original logs, in vendor-agnostic raw format (in case of future tooling changes), and concurrently deploy the filtering options from above to significantly reduce the less valuable data sent to the system of analysis thereby maximizing the value of every dollar spent on Splunk.
What about that replay capability? Yes, as mentioned, an important consideration when separating the system of analysis from the system of retention is ensuring there is a way to retrieve data from the system of retention without having to wait to thaw out cold storage or send someone to find it on a tape backup system. Cribl Stream is the first commercially available observability pipeline that provides the ability to easily and cost-effectively retrieve stored data right out of the box with our Replay feature. Replay gives administrators the power to specify parameters, such as user, date/time, or other information, that identify which data to retrieve and send to Splunk or other tools for immediate analysis.
Increasing Splunk Efficiency With Pre-Processing
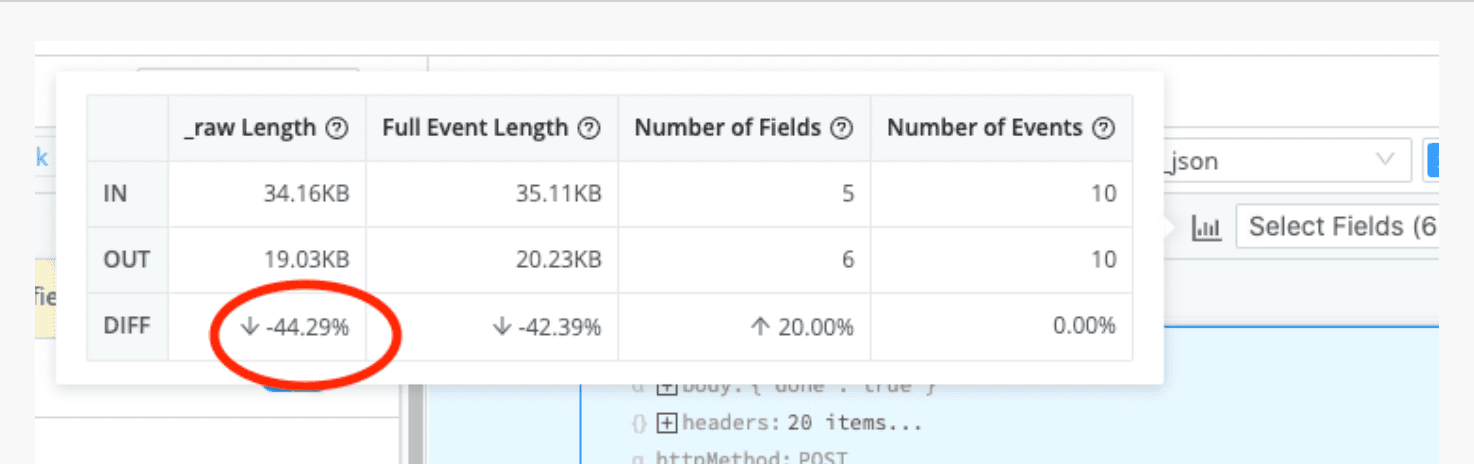
In addition to filtering machine data to free up space and diversify the data sent to Splunk, another best practice is to reduce the volume of the events themselves. While a verbose set of logs can aid in troubleshooting, it’s fairly common to see many unnecessary or unwanted fields within a specific event. By using pre-processing capabilities in Cribl Stream, it is possible to trim the event itself by removing NULL values, reformatting to a more efficient format (XML to JSON, for example), dropping duplicate fields, or even changing an overly verbose field to a more concise value. While the number of in- dividual events may be the same when using pre-processing, depending on the dataset, administrators can see up to 75% reduction in log volume just by getting rid of fields that do not contain any data at all!
Compressing Logs Into Metrics
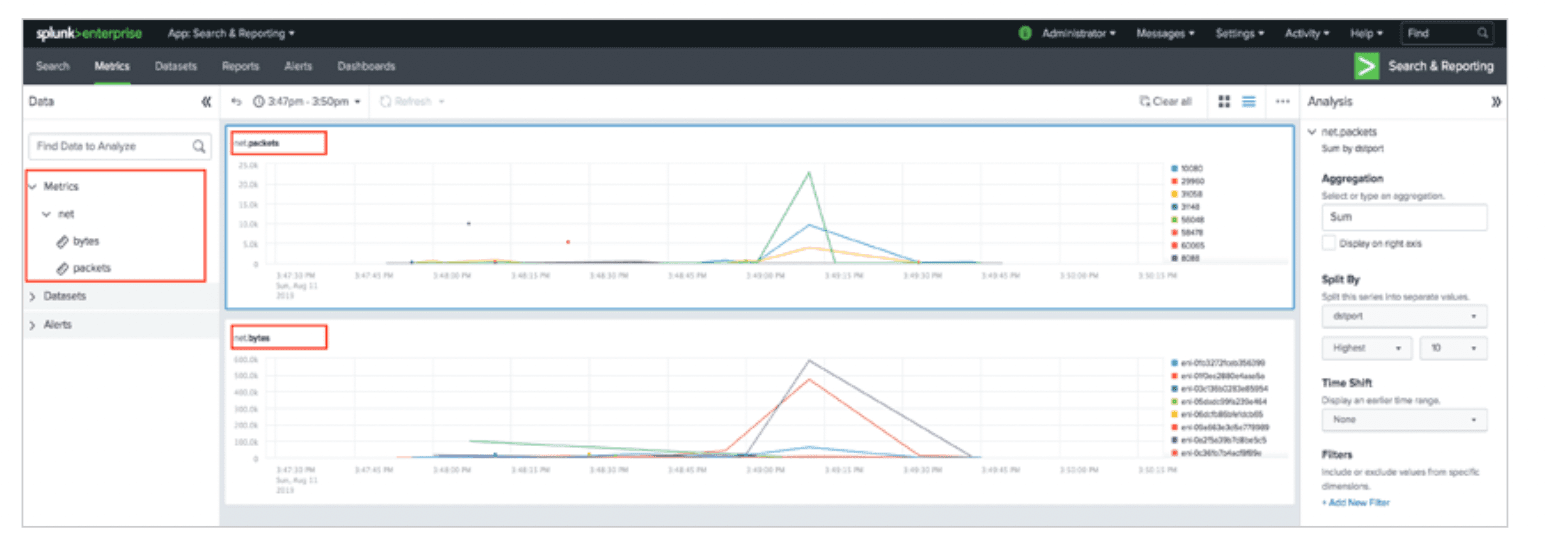
Many of the highest-volume data sources come from having to ingest extraneous information just to access a single useful statistic, otherwise known as a metric. Web activity logs, NetFlow, and application telemetry are great examples of this type of event, and another way to improve the efficiency of and accuracy of analysis from Splunk is to aggregate logs like this into summary metrics. Since a metric usually contains only a name, a value, a timestamp, and one or more dimensions representing metadata about the metric, they tend to require much less horsepower and infrastructure to store than log files.
Cribl Stream gives administrators the power to extract fields of interest, using built-in Regex Extract or Parser functions, and then publish the result to metrics. Once aggregated, administrators will see a major reduction in event counts and data volume, and then can choose whether to send those metrics to Splunk or potentially route the metrics instead to a dedicated time series database (TSDB), such as InfluxDB or Datadog for efficient storage and retrieval.
Decreasing Operational Expenses
One last way to see Splunk costs savings is by reducing the number of hours and resources dedicated to supporting it. By employing functions such as filtering, parsing, and reformatting in Cribl Stream, it is possible to reduce the overall noise to such a degree that finding the valuable and necessary information takes far less time in Splunk (or any other data analysis platform). Once events are optimized before being indexed, crafting the necessary search is easier, and the actual search itself runs faster as well. This not only reduces the time to insight, but it also removes the burden of bloated infrastructure, the constant juggling of content and compliance requirements, and building out custom solutions to solve a point problem.
In addition, consolidating multiple tools into a single, centralized interface further reduces the operational overhead associated with observability deployments. Administrators can replace the functionality of intermediate log forwarders, like Splunk Heavy Forwarder or Logstash, and other open-source tools such as syslog-ng or NiFi, with Stream. The obvious advantage here is fewer tools to install, manage, and maintain, but Stream also delivers increased efficiency by consolidating ingestion, processing, and forwarding of data streams for centralized visibility and control.
Summary on Maximizing Your Splunk Investment
Splunk is a leader in the data analytics industry and has long-term investments and partnerships with its customers for a reason. If you’re looking to maximize that investment and increase the efficiency and analytic capabilities of Splunk, Stream gives administrators the power to control and shape all machine data, making it possible to realize the benefits of a world-class observability solution on more sources of data thereby maximizing the return on your Splunk investment – all without changing a thing in your current Splunk deployment or with your current Splunk license.
The only solution of its kind, Stream was purpose-built to help customers to unlock the value of all machine data. Better yet, it’s free up to 1TB/day, so why not give it a try? Implementing a couple of these options using Stream could cut your log volumes dramatically!
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.







