
I’ll admit it: I’ve been fixated on data collection since we came out with LogStream 2.2. Though I’ve already talked a bit about using data collection for security investigations in my Data Collection for Security Investigations post, I wanted to expand on that a bit. At Cribl, we believe that storing data in cheap storage, like AWS S3, combined with the ability to “replay” that data at will, enables completely new workflows that can streamline the breach investigation process. I’d like to take you through one possible workflow approach…
Investigating a Breach, the “Old” Way
Say we’ve got a fictitious company, Sprockets, that uses their logging system to meet their retention requirements, and they “freeze” older data to be “thawed” when needed. Sprockets has a security team that is separate from the logging team, so when they need data thawed/restored, they need to work with the logging team to get it.
One morning, one of their security tools detects an anomaly and alerts the on-call security engineer. The engineer starts digging through logs and realizes that there has been a breach, which looks to involve three servers, a firewall pair, and a switch pair. After more digging, she realizes that it started sometime earlier than the earliest data in the logging system. The engineer has to ask the logging team to thaw earlier data, which has been archived in AWS S3. Because they need to retrieve all of the data for a given time window at once, the engineer requests only a month, waits for it to be present, checks it, and if the beginning of the incident is not there, has to repeat the process until the data needed is present. Since each one of those requests is a handoff to another team member, the process slows to a crawl.
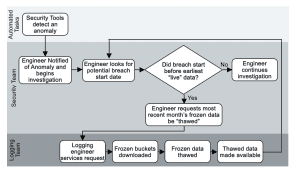
As you can see, moving your retention to “cheap storage” saves you a lot of money, but it alone does not solve the problem of getting that data back when you need it. The traditional route of pulling back the “frozen” files whole, thawing them, and attaching them to your log system would be too slow to be able to get meaningful data quickly. With many of the data privacy laws now in place and expected, the window for breach disclosure is becoming increasingly tight.
Since Sprockets does business in the EU, they need to notify anyone potentially impacted of a breach within the mandated GDPR 72-hour window. No company wants to put out a breach notification without at least an idea of when the breach started and how many customers were exposed. So it’s important to have an approach that speeds up data collection and allows you to filter data before pulling it across the wire. This approach minimizes data travel/decompress/ingestion time, which also will minimize the amount of storage and ingestion licensing you’ll need to accommodate the data.
This is where Cribl LogStream comes in. Placing a Cribl LogStream deployment between your logging sources and your log analytics system allows you to archive all of the data to a cheap storage mechanism for retention. This frees you up to reduce what’s going into your logging system to just what you really need day to day – via filtering unnecessary events, sampling repeating events, and cleaning up messy data. This, in turn, puts less stress on your logging system, improving performance (smaller haystacks = needles are easier to find). LogStream 2.2 introduced Data Collection to the product, which enables a flexible and efficient way to retrieve data from the archive, filtering it based on the partitioning scheme of the data (more on this later).
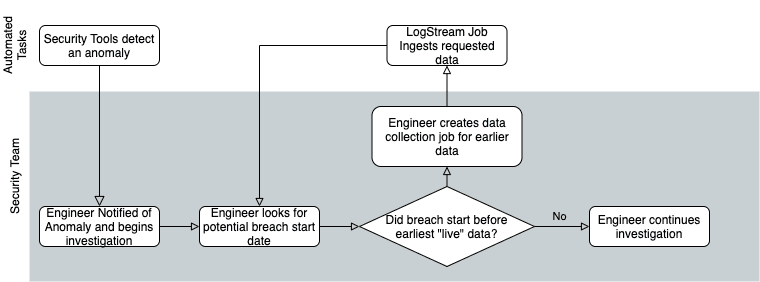
Investigating a Breach, the LogStream way
Let’s revisit our fictitious company, Sprockets. With 1TB/day of data, they’re able to install and use the free version of LogStream and move their retention to cheap storage. With all the money they’re saving, they can change their retention policy to keep log data around for 10 years.
Four years in, they discover evidence of a breach via analysis of firewall logs. Needing to work backward to find when the breach started, the security team can now easily run a data collection job to pull only logs from the last year. But instead of having to download *all* of the data for the last year, about 365TB of data, with LogStream’s filtering capability, they can limit it to just firewall logs, which we’ll estimate at about 15% of their total log volume (54.75TB).
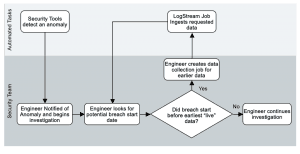
They can reduce that even more, based on the situation. For example, if they only need to see logs for traffic that left the network, and the partitioning scheme includes IP addresses or zone names, they could filter for just traffic between trusted and untrusted zones – which we’ll estimate as being less than 30% of all traffic events, or 16.5TB. With a few simple filters, we’ve now narrowed the “replay” of that data down to about 0.5% of the total.
Moreover, using LogStream 2.2’s collection discovery, preview, and jobs allows us to model all of this before actually retrieving any data – ensuring that full collection jobs retrieve just the data that’s needed. As the data breach investigation progresses, the scope of the breach becomes clearer, and additional logs need to be pulled back in. No problem there, since they can just fire off another data collection job for the additional data whenever they discover the need to.
See How LogStream Can Work For You
LogStream 2.2 is packed with great new features and significant improvements to existing features. We have a Data Collection & Replay Sandbox, available for you to master. This gives you access to a full, standalone instance of LogStream for the course content, but you can also use it to explore the whole product. If you’re not quite ready for hands-on and want to learn more about 2.2, check out the recording of our latest webinar on 2.2, presented by our CEO, Clint Sharp.






