

TL;DR: With Cribl 4.6.0, we support managing 50k Cribl Edge nodes in your deployment!
At Cribl, we value the simplest and quickest path to shipping new things. This is especially true with shipping new products. We took this approach with Cribl Edge, so we could get it into the hands of existing and potential customers as soon as possible to learn more about their needs and requirements. In order to ship a high-quality Edge product quickly, we based all of the systems for management and data streaming directly on the existing, battle-tested systems we built for Stream. This was amazing for shipping quickly (built and shipped an agent with centralized management capabilities within 4 months); however, as Edge moved from incubation to a full-fledged product and as customers began adopting Edge, we soon learned that Edge’s scaling needs and functional requirements did not entirely match those of Stream.
Before diving into the differences between Stream and Edge, let’s introduce some basic concepts about the Cribl product suite architecture. Below is a diagram showing the two “planes” within the architecture:
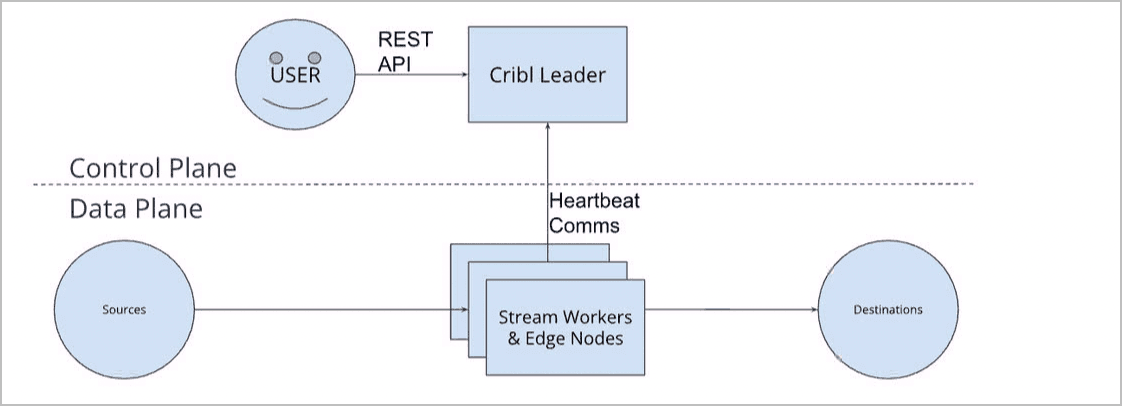
The Control Plane is the part of the architecture that provides the user experience (REST API, UI, centralized management, etc), and the Data Plane is the part of the architecture that provides the data processing and collection capabilities for the product suite. Between the two planes is a heartbeat communication channel that allows for distributed management/communication. If you’re curious to see some reference architectures, check out our docs here.
One of the biggest differences we saw was the scale of the Data Plane. While Stream needs tens of servers to process large volumes of data, Edge needs thousands of agents to collect smaller volumes of data with minimal processing. Our Data Plane systems are entirely capable of handling this, but the assumptions built into the Cribl Control Plane were becoming challenged by the number of Edge nodes customers wanted to connect.
These differences led us to think through how we could transform the Cribl Control Plane to enable gradual scaling over time while keeping the best-in-class management experience that Cribl is known for as customers onboarded more and more Edge nodes into their deployment. We performed multiple iterations of bottleneck testing, stripping out or hacking together solutions to determine where each bottleneck occurred in the system and where the next one would be once the first was removed. We built emulation tooling as we moved from tens and hundreds of Edge nodes to thousands and tens of thousands to speed up the feedback loop and lower the cost for engineers trying to scale out the Control Plane. Once we had determined enough bottlenecks that would take months, if not years, to address, we formed a roadmap and began executing on the highest leverage points first to really move the needle for customers quickly and at high quality.
With Cribl 4.6.0, we achieved a significant milestone for Edge support–tripling the existing scale to support 50k Edge nodes!
So, How Did We Do It?
Heartbeat Optimizations
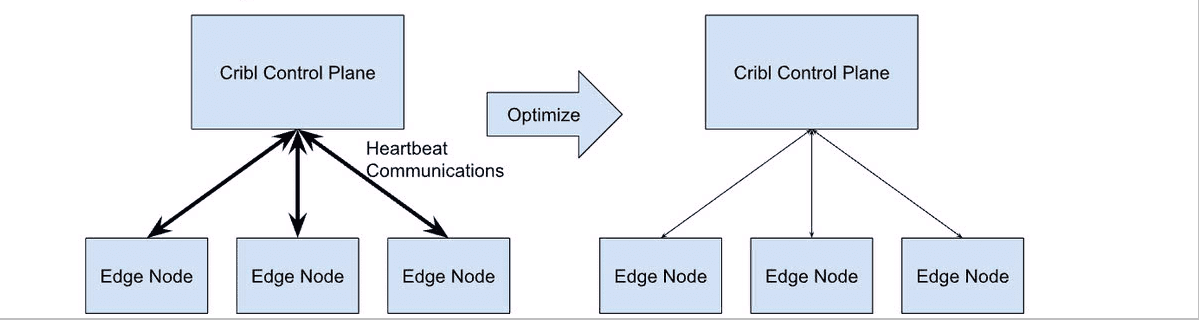
Edge/Stream nodes open a persistent TCP connection to the Control Plane. This connection is used to facilitate heartbeats and other communications between the Data Plane and the Control Plane. One of the first things we noticed when we started searching for bottlenecks in the system was how much unused information was included in the heartbeat connection between the Edge node and the Control Plane.
We initially built some of the heartbeat communications to eagerly send a lot of information to simplify code design when we were building strictly for Stream. We assumed there would only be tens of heartbeat connections, so there would not be a ton of wasted resources. As we began scaling up the number of heartbeat connections connected to the leader, we determined the information being sent to Edge nodes either went totally unused or only used on-demand when a user performed specific actions.
From there, we were able to make a very high leverage change by simply removing the eager data sending and replacing it with Edge nodes lazily receiving data whenever the user performed the actions that required it.
Vertical Scale
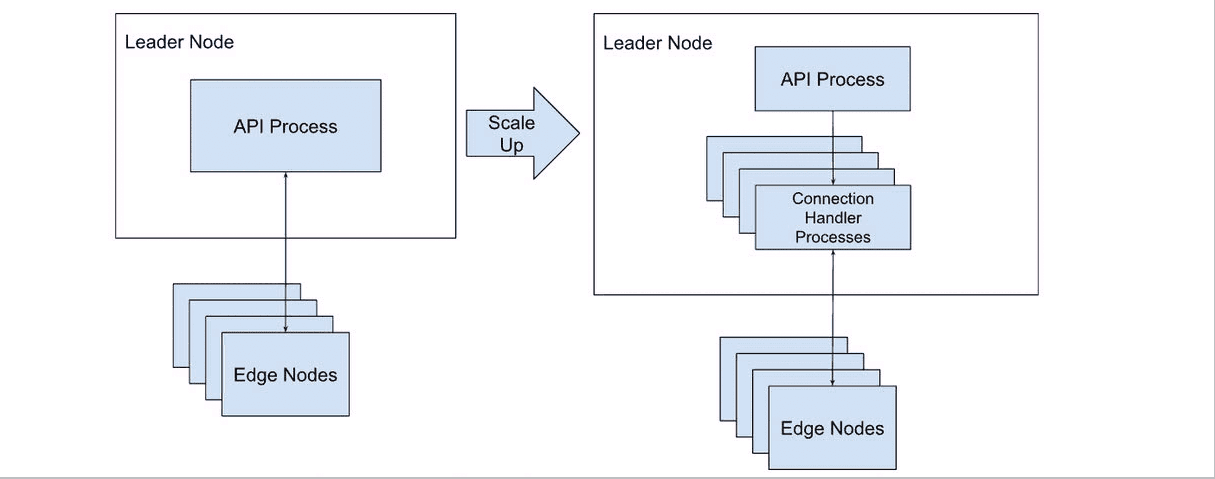
Another bottleneck we found was the Control Plane’s inability to handle the number of heartbeat connections and the data they were sending. We leverage the heartbeat channel to send product metrics into the Control Plane, so we can provide monitoring capabilities to customers. On top of these metrics, we’re also handling RPC (remote procedure call) requests, requests to download configuration bundles, distributed upgrade requests, etc via the heartbeat connection.
Given we use NodeJS to power our backend, the Control Plane was managing all of this communication via one single-threaded process. This process also acts as the API gateway and serves the user interface for customers, so once this process became overloaded, APIs and UIs slowed down to a crawl and typically, at the scale we wanted to achieve, the Control Plane would totally crash with memory issues.
At this point, we took inspiration from how our Data Plane scales by leveraging the NodeJS cluster module to enable vertical scale for how we handled and processed the heartbeat connections. We leveraged the cluster module to fork off multiple processes that listen on the heartbeat connection port and the parent API process now round-robins sockets to each child connection listener process. This allows customers to scale up their Control Planes as much as they need to service the number of Edge nodes they have in their deployment. The added benefit of shifting the heartbeat connection workloads off of the parent API process is that the UI/API is no longer affected by the load induced by handling heartbeat connections.
Moving the connection handling into these processes also allowed us to push serving configuration and upgrades from the API process out to the connection handling processes. This made it possible to leverage more hardware to support more Edge nodes. We serve these files via HTTP requests and they’re serving tarballs from disk, so creating parallel readers/HTTP servers leveled us up even further to serve more concurrent requests.
Building to Purpose for Edge
At this point, we evaluated features built initially for Stream from first principles to identify optimization opportunities within the context of the Edge product. The feature contributing the most to the Control Plane not scaling was our distributed upgrade system. This system was built on top of our Jobs system, which powers our data collectors. It’s a poll-based system where Data Plane nodes would pull tasks from the Control Plane to perform work. As you scale up the number of Edge nodes in the deployment, this wreaks havoc on the resource usage of the Control Plane trying to manage all the requests for work, and, again, leads to memory exhaustion and crashing the Control Plane entirely.
The reason there’s so much overhead to the Stream distributed upgrade system is because Stream is a critical, centralized piece of infrastructure in customers’ Data Plane. The system was built to perform responsive, rolling upgrades to ensure data processing never stops. Edge, on the other hand, is an agent that’s running on a large number of disparate machines, collecting data that is largely persisted on the machine they’re running. Edge nodes are typically running across different data centers, networks, etc, so we cannot even assume all Edge nodes will always be connected to the Control Plane at the same time. There’s no need to coordinate upgrades across the fleet of Edge nodes. Customers care more about eventually getting all the nodes on the same version more than coordinating the cluster to ensure processing never stops.
We took this distinction and ran with it. We decided to make Edge upgrades lazy. This means whenever an Edge node checks in with the Control Plane via its heartbeat, the Control Plane determines if the Edge node is on the correct version and issues a command to upgrade the node if it is on the wrong version.
This simple approach to upgrades for Edge allowed us to totally remove the polling system that was taxing the Control Plane from Edge, removing yet another system causing linear growth in resource usage as you added more Edge nodes.
Building for Cloud-First
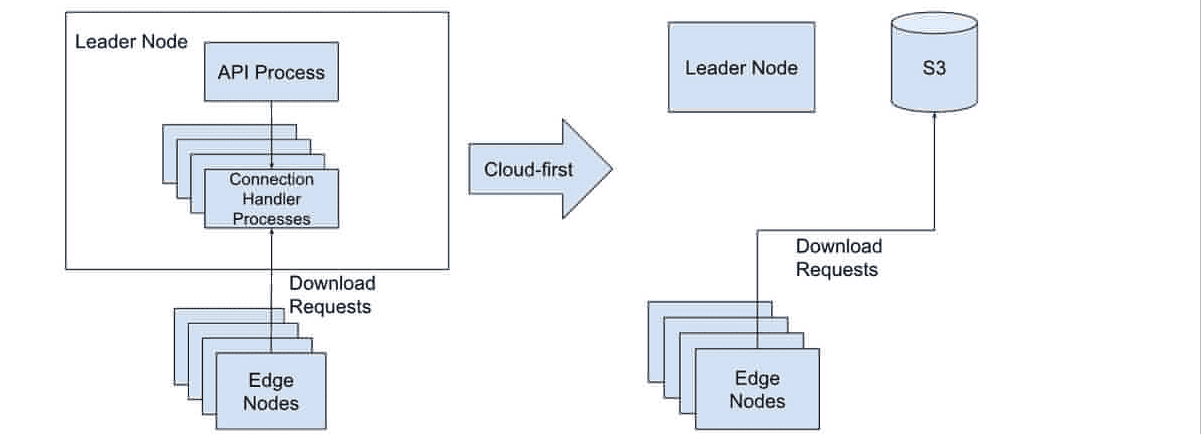
As mentioned in the vertical scale section above, we’re hosting and serving configuration and upgrade tarballs from the Control Plane via HTTP requests. These tarballs can be quite large (ranging anywhere from 1MB to 100s of MBs), and if you’re attempting to download them concurrently from thousands of Edge nodes, we’re suddenly limited by the number of processes you are running to handle connections in the Control Plane.
We decided to leverage a cloud-first approach to eliminate this scaling issue. We started pushing the tarballs into S3 and replacing the URL the Control Plane provided Edge nodes to download from a pre-signed URL pointing at the S3 object. This totally removes the load of acting as a HTTP server and delegates that responsibility to a service that is built for that exact purpose. Yet another high leverage change (simply change the URL handed out) that netted a large boost in scalability, while keeping our Cloud offering on the cutting edge of product development.
Taking a cloud-first approach allowed us to build monitoring and hardening in our own environment leveraging off-the-shelf cloud technology (i.e. S3) to quickly spin up a highly available and scalable solution. Given we’re a cloud-first and not cloud-only company, we can take our learnings from running this solution ourselves and apply it to our self-managed offering as well to help all our customers scale their deployments further.
Conclusion
With all of these improvements, we easily went from hundreds of Edge node support all the way to 50k. We still have plenty of work and roadmap to execute on as we keep scaling our products along with our customers. We are continuously investing in our scalability as well as all the other -ilities here at Cribl as we continue to build a generational and multi-product company. If you’re interested in working on scaling challenges, check out open positions on our careers page!






