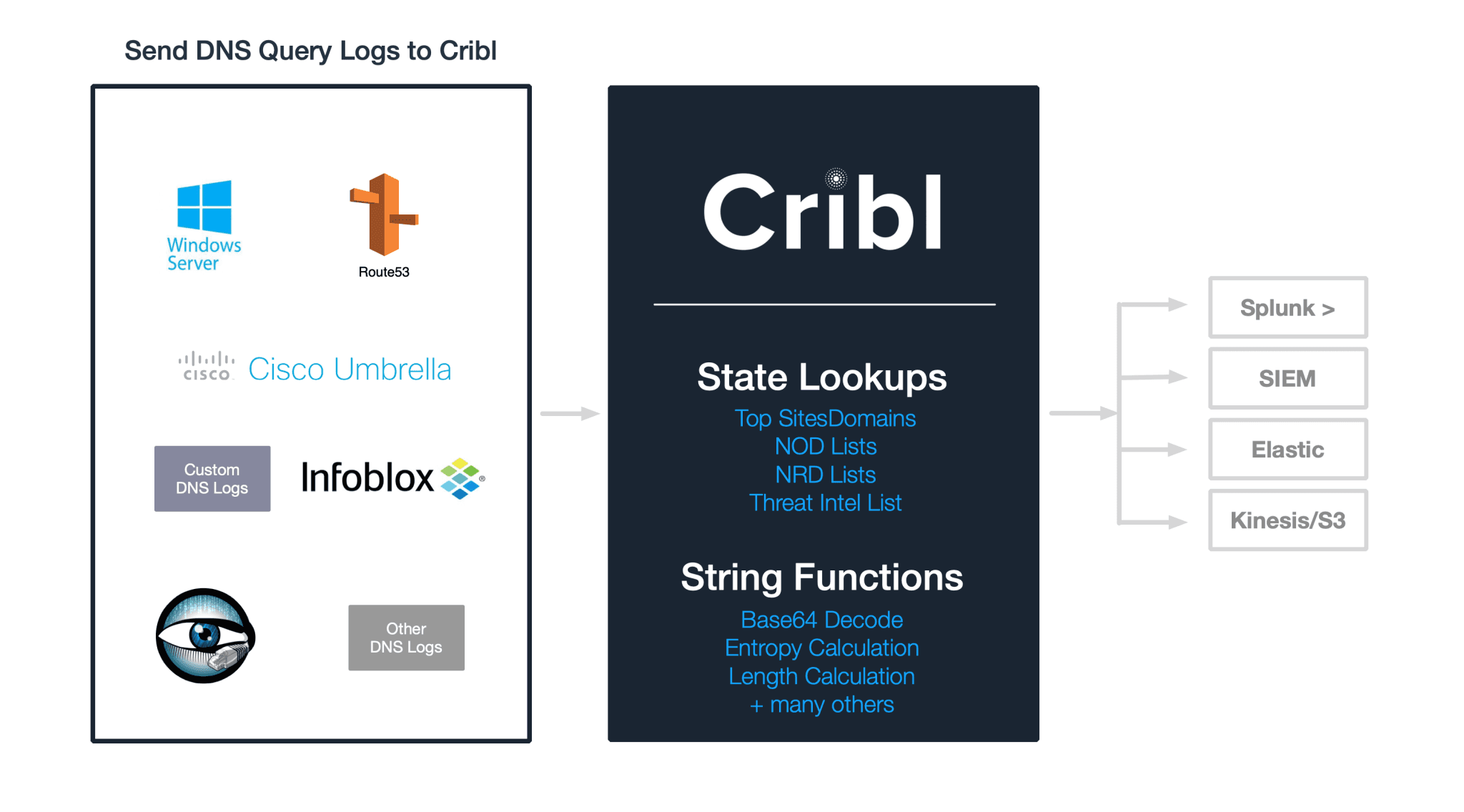

In a previous post we showed how to use detect data exfiltration with LogStream in real-time. The analysis focused on checking DNS labels from DNS logs for presence of base64 encoded data.
In this post we will look at several other techniques that can help security engineers add dimensions to the data to help improve the fidelity and accuracy of their analysis.
1. Use Lookups to filter out events from known good domains
DNS logs for external requests are extremely noisy. The majority of the traffic tends to go to top ~1K most popular domains, (e.g. google.com, facebook.com, wikipedia.org … yes, aol.com, too) and the likelihood that either of those is fully compromised is pretty low. If you can live with that assumption, it makes sense to filter or sample their logs before the rest of the analysis is completed. This will make querying at the end system way more efficient. Full fidelity data can be sent to long term storage for future analysis or to fulfill audit or compliance requirements.
First, get the top domains list from Alexa, Umbrella, Quantcast, or some other reputable source. They’re usually pretty long so feel free to truncate it to top 1K-10K or so. Almost all will have a format similar to this:
rank,domain1,google.com2,youtube.com3,facebook.com...N,amazon.com
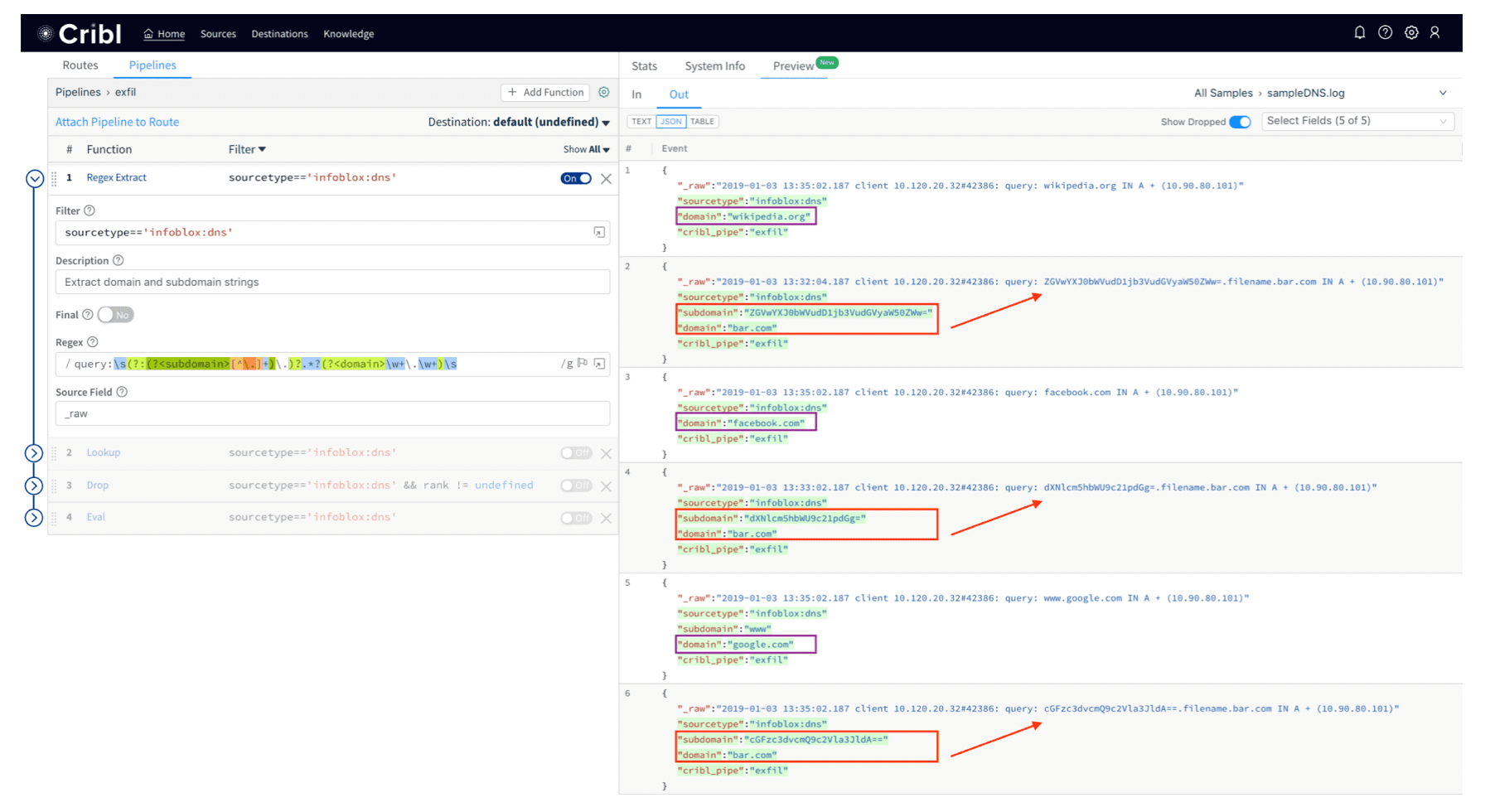
Use Regex Extract function to extract
subdomainanddomainfields from the log.
Use the Lookup function to get
rankfield given thedomainname.
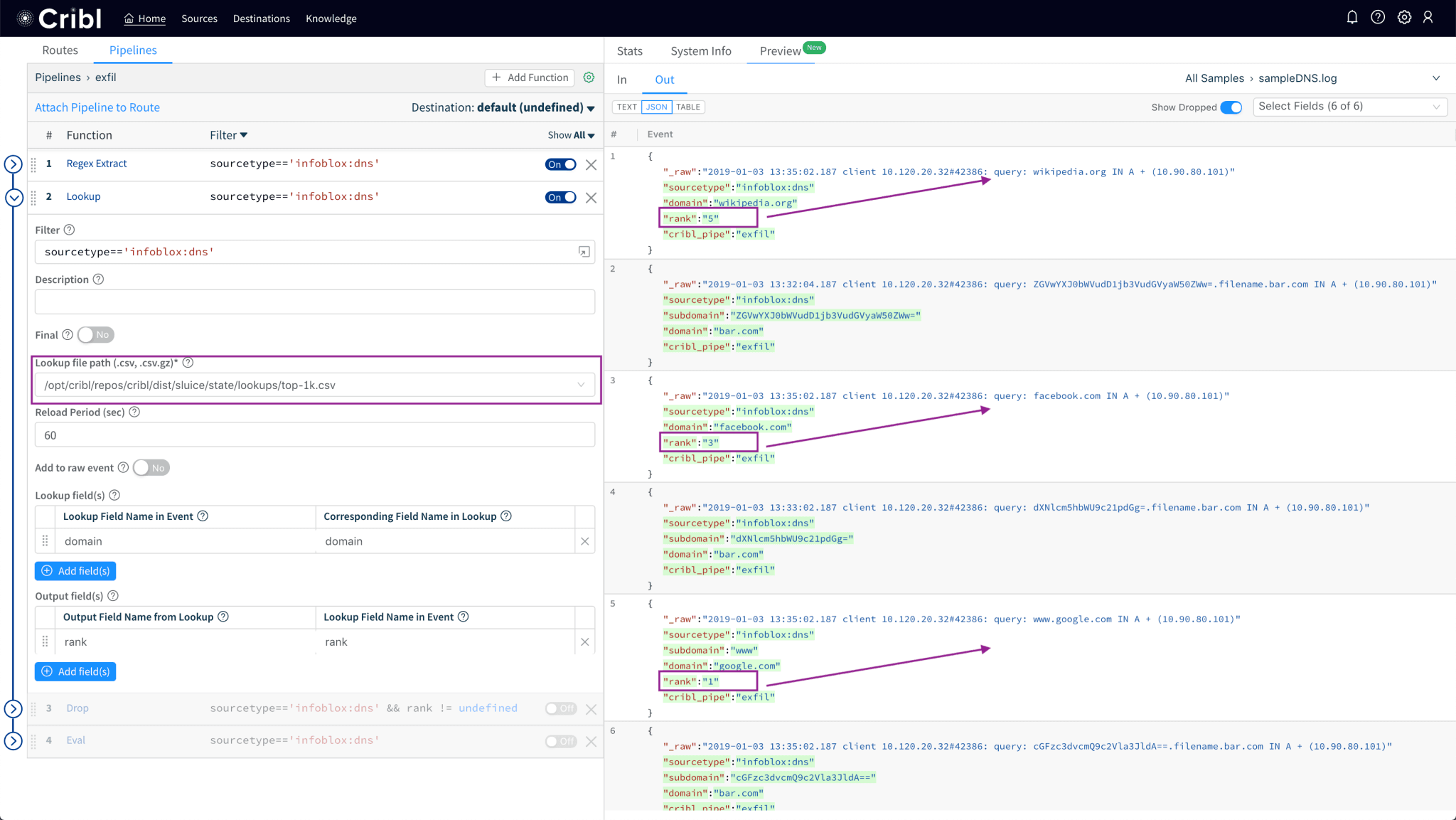
Drop events that have a
rankfield (i.e. domain present in the list).
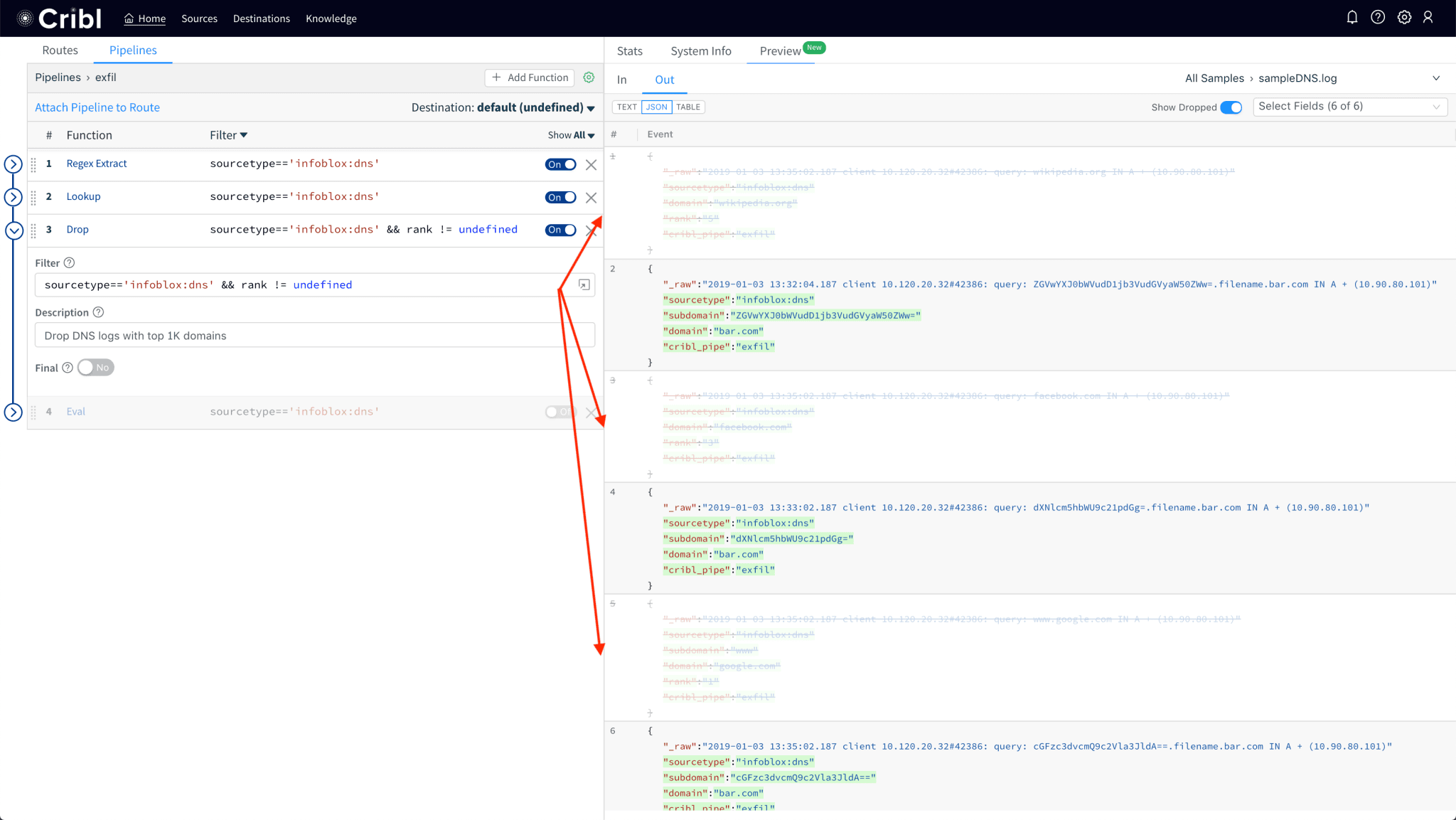
Notice how sample logs showing queries to Wikipedia, Facebook and Google have been dropped.
2. Use NOD or NRD lists
Newly Observed Domains (NODs) or Newly Registered Domains (NRDs) tend to be used by adversaries for additional malicious activities such as botnet coordination, spam or malware distribution. Companies such as Farsight Security track, curate and publish these lists daily. If you have access to such lists you can bring them into Cribl as lookups and do either of the following:
Use these lists instead of the above to base your filtering on, i.e., instead of dropping events that are from top 1k domains, you can drop those that are not in a NOD/NRD list.
Use these lists to add a field to each event if there is a match on the subdomain or the full domain.
3. Enrich events with enhanced DNS label string calculations
Decorating each of the remaining logs with additional fields helps with our analysis.
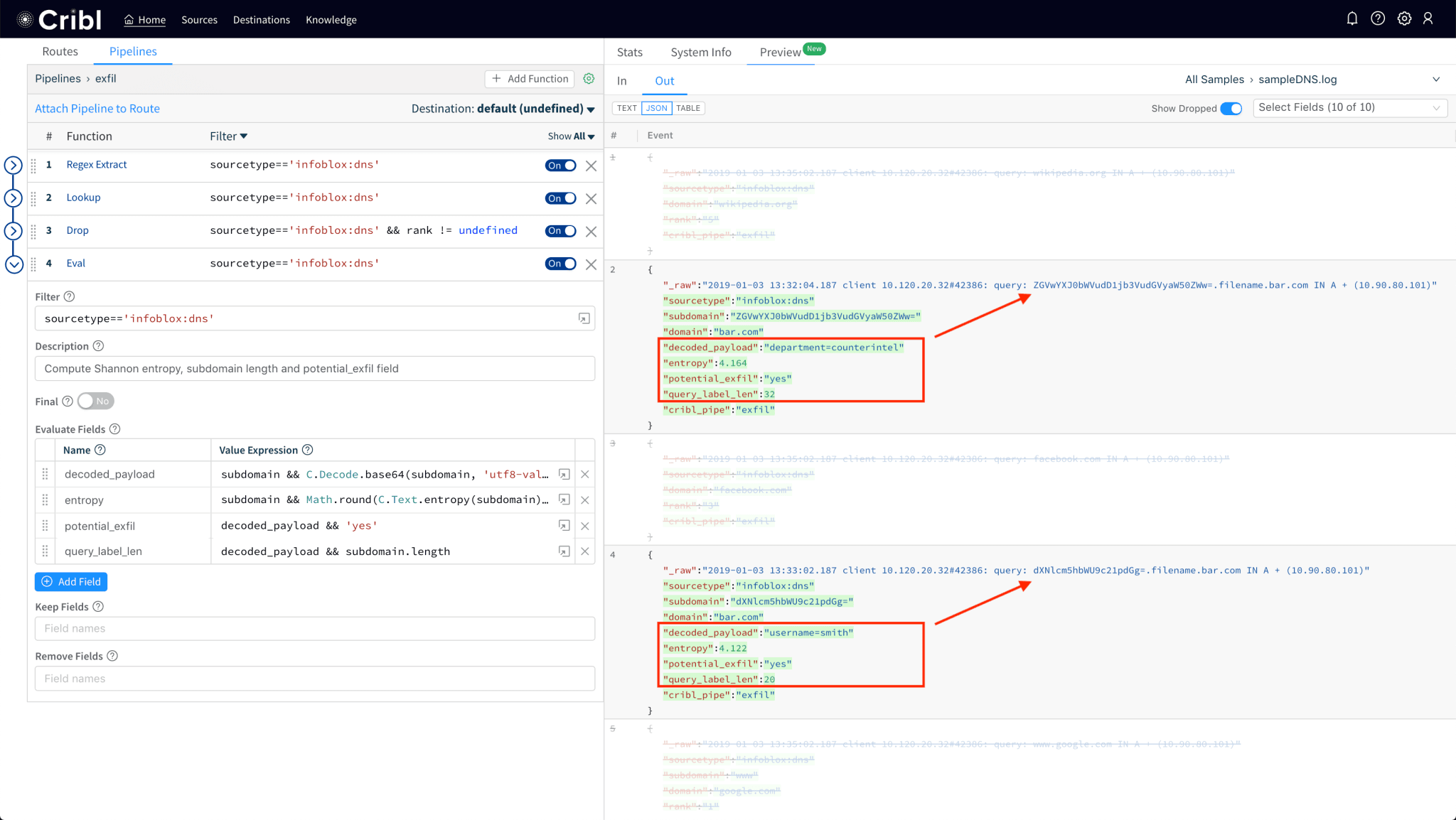
2.1 Improved base64 detection
Use the new C.Decode.base64() function and validate that its output is actually UTF8, by passing the 'utf8-valid' parameter: C.Decode.base64(subdomain, 'utf8-valid'). This is necessary because not all subdomains will be base64 encoded, e.g., live in live.foo.com is not a valid base64 encoded string.
2.2. Add subdomain’s (Shannon) entropy to each event
Another interesting dimension that we can add to each event is the Shannon Entropy of the subdomain string. Linguistically speaking, entropy of a word/string can be thought of as a measure of its characters’ randomness. Since exfil data base64 encodings and other malicious domains (e.g. those used by malware etc.) typically have random-looking – or rather, more random looking than “normal” – subdomains, computing a score of randomness will helps us improve the fidelity of our analysis. Shannon entropy can be calculated with C.Text.entropy(subdomain).
2.3. Add DNS label directed divergence or relativeEntropy to each event
While Shanon entropy works well for random data, a potentially more accurate way to measure the gibberish-ness of domains/subdomains would be one that compares its randomness against another non-random distribution. Per Wikipedia, “In mathematical statistics, the Kullback–Leibler divergence (also called relative entropy) is a measure of how one probability distribution is different from a second, reference probability distribution.“. An example of a reference probability distribution would be the English language. An even better example is that of the characters that appear in the list of most popular domains and subdomains as tracked by Alexa, Umbrella, Quantcast, etc. And, that’s exactly what the relativeEntropy function uses as a baseline model.
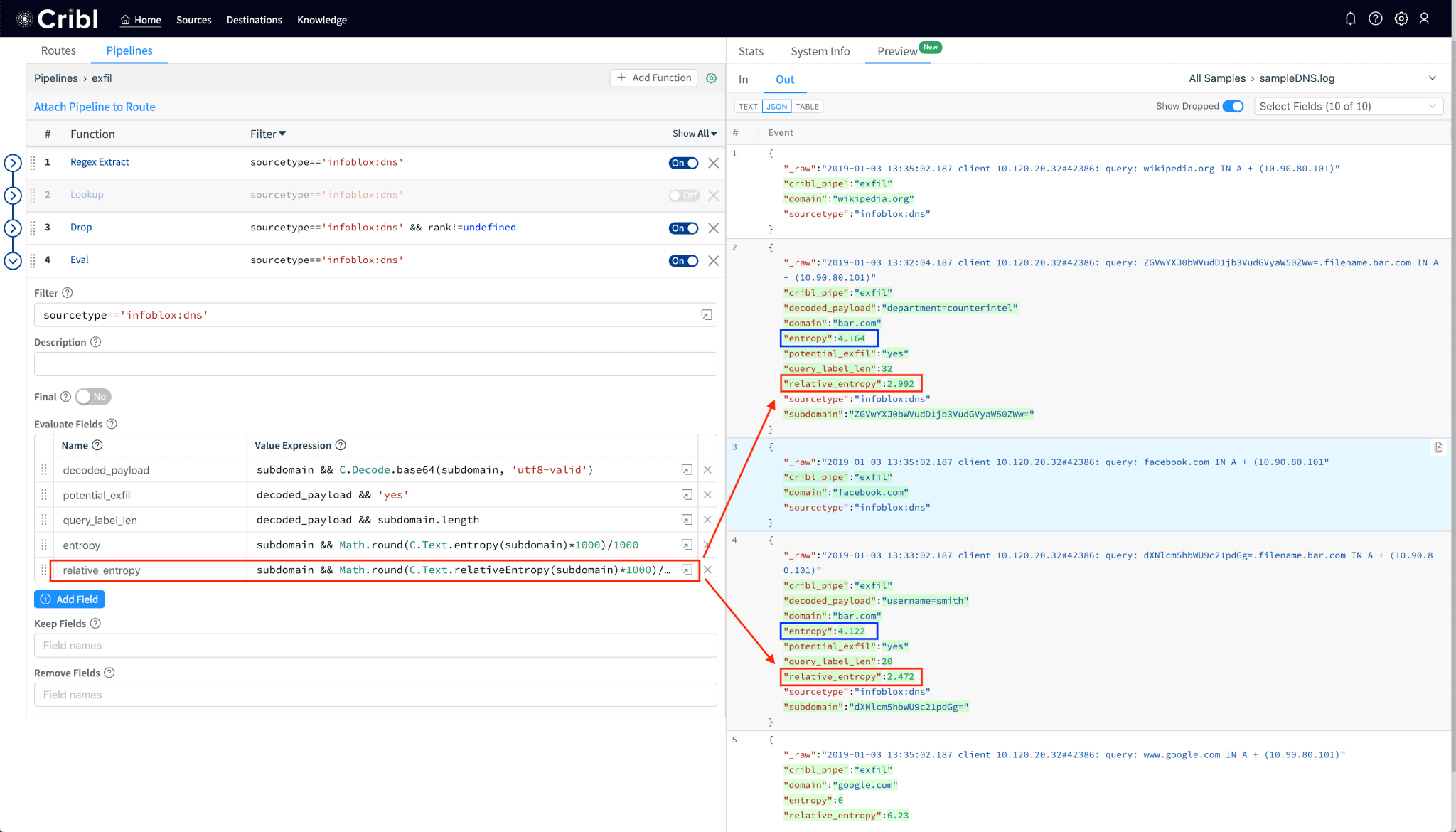
Notice that the relativeEntropy, as expected, results in a lower value than Shanon’s. If you’d like to read more about DNS entropy here’s an excellent reference (in pdf) from DomainTools.
To use this data in Splunk, you can search or alert by referencing our new fields. E.g.:
index=myIndex sourcetype=infoblox:dns entropy>3.14 OR relative_entropy>2.4
In your system you may want to track length and entropies over time and adjust your searches accordingly.
Good luck!
Please check us out at Cribl.io and get started with your deployment. If you’d like more details on installation or configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!
Enjoy it! — The Cribl Team






