

The common failure scenarios that occur in the cybersecurity world are typically assumed to be costs of doing business, but they’re actually more predictable and avoidable than you might imagine. Even if you’ve been lucky enough to avoid failed data sources or backups, a SIEM getting knocked offline, and other cybersecurity attack situations until now — in today’s day and age, they’re still inevitable.
Cyber resilience is the term we use to describe the ability of organizations to prepare for, respond to, and recover from these cyber threats. Resilient organizations can adapt to known and unknown issues, threats, and challenges, and avoid a lot of the problems that come from being unprepared.
System Data in Scope for Security Is Vast and Growing
The most important piece of the resiliency puzzle is getting a handle on your observability data and accounting for all the logs, metrics, traces, and other generated data that gives you insight into the health of your systems. Enterprises are expected to manage 250% more data in 2025 than in 2020.
Data is increasing so quickly in volume, velocity, and complexity that our ability to generate and collect it is outpacing our ability to analyze and gain insights from it. This is especially true as we move more to the cloud, a trend that will generate exponentially more data. The average organization uses more than ten tools to manage it all, and that number is likely to continue growing.
Get the Right Data in Your SIEM Is a Challenge
Material data volume growth creates some new challenges for managing a SIEM platform in 2023. Retention requirements are one of the most noticeable — we brought on a customer last summer whose retention period went from 90 to 365 days in just a couple of years, and recently jumped up to five years. At some point, it will probably become unlimited. Compliance and ever-increasing dwell time make retention and access to your retained data a major challenge.
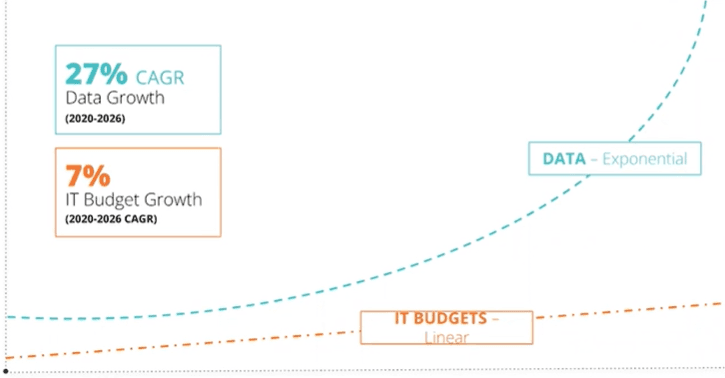
We’ve also spoken to several CISOs who have a backlog of sources they want to onboard but can’t afford to. Data is growing at a 27% CAGR, but budgets can barely cover the cost of inflation. Not having the right data available to your security team weakens your enterprise security posture and increases your risk of an incident.
High-volume, low value data sources (Flow and DNS logs) are important data sources, but due to costs they’re prone to getting dropped without being processed. This creates an ideal scenario for attackers looking for high-volume, uncollected, unanalyzed places to hide their exploits.
How to Plan for a Failure
So how do you manage your costs, get the right data in your tools, and improve your security posture so that you can maintain business continuity? The first thing to do is think through different failure scenarios — both the ones you know about and those you don’t yet know about.
Consider dependencies as well. For example, how are you getting data to your SIEM? Can you have one type of tool that handles getting data in so that you’re not relying on your vendors?
It’s also critical to think about what would happen if data is flowing somewhere and needs to stop. You’ll need a backup plan for everything you’re assuming will continue to work without interruption. Your cloud provider, SIEM, and other parts of your security stack aren’t guaranteed to operate perfectly 24 hours per day. There’s a reason water sources have failovers — if something stops working, it needs to have a place to go. The same is true for your data. How difficult would it be to cut data over to an S3 bucket or on-prem solution instead if the situation arose?
Present Failure Scenarios to Leadership
Once you think through your favorite failure scenarios, prioritize what you want to address. You’re not going to be able to fix everything, so you’ll need to decide which issues you want to work with your leaders on to determine next steps and/or funding.
When you lay these potential problems out to management, you may find that they’ll be okay with certain ones failing. The financial investment may not be worth the potential risk to them, but it’s still critical to bring it up. Make sure you document everything — if things do hit the fan, you’ll want to be able to show that there was no oversight on your part.
Making sense of and organizing all this data is a tall task, but the problem will only get more difficult to solve. The good news is that the bar is super low — Twitter’s former head of security has said that they don’t understand 80% of the data they collect. Set your cyber resilience plan in motion today to avoid being in a similar position in the future.
Watch the full on-demand webinar to see Jackie McGuire and me discuss how to prepare your data infrastructure to handle large spikes in data. The conversation will give you the tools you need to address this and other issues with existing deployments, and show you how to plan for new deployments as well.





