

One of the core features of Cribl Stream is our Replay capability. We pride ourselves on giving customers choice and control over their data. The ability to archive data in cheap object storage and then provide the ability to reach into the same object storage is one example of this. It’s safe to say that Amazon S3 and AWS have become synonymous with object storage. It’s like a modern-day Kleenex or Band-Aid. However, it’s important to remember that there are other equally featured object storage options available. In this post, we’ll walk through an example of Replay with Azure Blob Storage, and view logs within Humio.
For data, we’ll simply use the built-in syslog datagen within Stream.
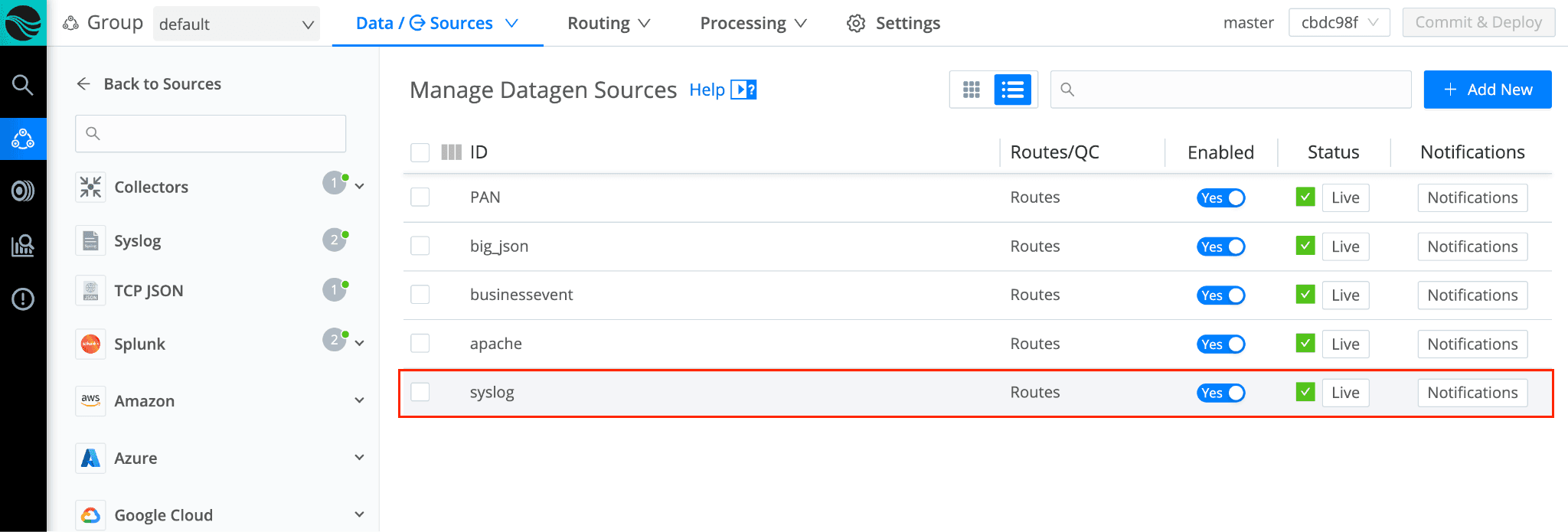
Next, it’s time to configure an Azure Blob Storage account. Below is a screenshot of a storage account named “borgal”. I’ve created a container named “cribl”, allowed the appropriate IPs access, and grabbed access keys:
Next, it’s time to configure the Azure Blob Storage destination within Stream. Let’s walk through the configuration together. Below I’m creating a new Azure Blob Storage destination, naming it ‘Borg_Blob’, specifying the container ‘cribl’ (from above), and using ‘demo’ as the root directory. I’ve also specified that Stream writes data in JSON format, and under authentication, this is where I’ve placed the Connection String from above (Access Keys).

Now it’s time to discuss one of the most important pieces of configuring archive storage with Replay in mind. Below, we’ll configure a setting called ‘Partitioning expression’. This tells Stream how to form the directory structure when writing data to Blob. We need to be forward-thinking about this because Replay can utilize the directory structure to filter and selectively Replay just the data we need.

Partitioning Expression in Azure Blob
As mentioned above, partition expressions are a way for us to define the Azure Blob Storage container directory structure. While configuring a Destination for archiving purposes, it’s important to remember that Replay can filter on this directory structure. We can use metadata from events as definitions. For example, above, we use the event timestamp to create the beginning of the expression, year/month/day. We then follow that with the ‘host’ value from the event.
Keep in mind the cardinality of your partition expression. Keep this under 2000. Be sure to adjust the max open files limit under the advanced settings above. A high cardinality can cause too many open files/directories on the worker nodes. Too low cardinality will mean larger files written to Azure Blob Store, and less granularity/more data downloaded when running Replay. Think of common search terms for different data sets for partitioning (e.g., status code and host for web server logs, or zone and timestamp for firewall logs). If you’d like more information on tuning for object stores, check out the How To: Setting Up S3 as a Cribl Stream Destination blog.
Archive Data
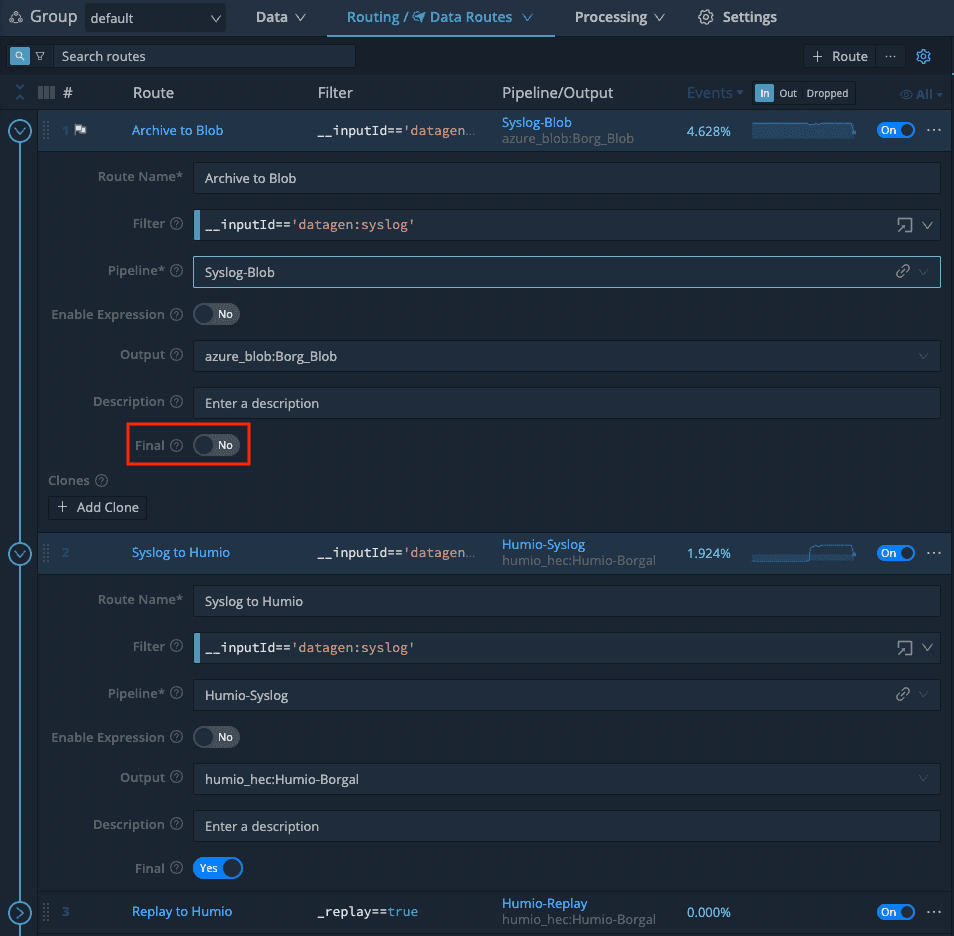
Let’s connect our syslog datagen to our newly configured Azure Blob Storage destination. Below is a screenshot showing three routes. The first route is our Archival route. I’m filtering on our syslog datagen input, sending data through a pipeline (to keep _raw, but strip other fields), sending data to Azure Blob, and setting ‘Final’ to ‘No’ (very important).
The second route then takes that same data, sends it through a different pipeline (primarily to JSON-ify the syslog message), then sends data out to Humio (note the final flag is set to yes).
Now if I take a look at my Azure Blob Storage container, we can see files written with the partition expression we specified (year/month/date/host):

And in Humio, we can see the same data:

Collector
Now that we have our archiving working, next is configuring the Azure Blob Storage Collector. A really cool feature here is that we can auto-populate the configuration from what we did previously for the Azure Blob destination. Path should align with the partitioning expression we configured earlier for the destination:

It can be useful to add a field for Replayed events. This can be useful for filtering in our routes/pipelines, as well as making searching Replayed data easier:

Replay from Azure Blob Storage
With the collector configured, we can now run our first Replay job.

When you click run, there are several options to choose from and optional fields. In this example, we’re doing a ‘Full Run’ (collect and process any found events). I’ve been very prescriptive on my time range, and I’m looking specifically for logs from host ‘beatty5315’. Remember, since we use host in our partitioning expression, I can use it here as a filter.

After clicking Run, the popup closes, and takes you back to the Manage Azure Blob Collectors screen. You’ll notice a link under ‘Latest Ad Hoc Run’. Here, you can check the status of the Replay job. You’ll notice details like run time, events discovered and collected, etc.


Two things to note here. One, larger collection jobs can take longer, so don’t be alarmed if the above screen is incomplete. Two, it is best practice to have a worker group dedicated to Replay so as to not disrupt real-time streaming data. These could be temporary instances that are spun up just when Replay is needed.
Finally, let’s look at the end result in Humio. The events outlined in red are the events that we used Replay to bring back into Humio. You can see how the Replayed events have the original raw message in the _raw field, and I’ve left the field _replay for searching purposes later.

Hopefully, this was a helpful walkthrough of Archiving and Replay with Azure Blob Storage. If you have any questions, reach out on the community Slack, or your local Criblanians!
More about Cribl Stream Replay
How To Replay Events from Object Storage into Your Analytics Systems using Cribl Stream
Breaking Down Why ‘Replay’ with Cribl Stream is a Game-Changer
Cribl, the Data Engine for IT and Security, empowers organizations to transform their data strategy. Customers use Cribl’s suite of products to collect, process, route, and analyze all IT and security data, delivering the flexibility, choice, and control required to adapt to their ever-changing needs.
We offer free training, certifications, and a free tier across our products. Our community Slack features Cribl engineers, partners, and customers who can answer your questions as you get started and continue to build and evolve. We also offer a variety of hands-on Sandboxes for those interested in how companies globally leverage our products for their data challenges.






