

In the past we’ve written multiple posts about how Cribl helps you maintain visibility in high-volume/low-value scenarios without having to egregiously scale your analytics infrastructure. This problem usually stems from the fact that machine data emitted by your infrastructure is not all created equal. Some events are way less valuable than others but yet they consume storage and compute equally. One way to address this is to provide administrators and SMEs with controls and capabilities that allow them to filter, route, suppress and sample data based on specific conditions. For instance, with Cribl you can:
Filter and trim out unnecessary fields from highly verbose events.
Sample high volume low value data and route full fidelity to long term storage.
Systematically sample uninteresting events while leaving the rest unmodified.
Let’s briefly revisit sampling because we’ve got some really cool stuff to show off!
Sampling is a very simple concept: instead of using all events to make a decision, use a representative subset to get as statistically close to the exact answer as necessary. The Sampling function that ships out of the box implements Systematic Sampling whereby “the sampling starts by selecting an element from the list at random and then every k-th element …is selected, where k, the sampling interval“.
This is straightforward to configure. Just provide a matching condition and a sample rate. E.g.,
Match :
source=='aws:cloudwatchlogs:vpcflow' && action=='ACCEPT'Sample Rate: 10:1
This simplicity makes this type of sampling very desirable in cases where data flow characteristics are known ahead of time. For instance, the admin/SME knows exactly what each content matching condition and its corresponding constant sampling rate should be.
But what if you wanted a sampling mechanism that was automatic and adaptive to volume of data? What if you didn’t know the values of those fields ahead of time? This is where Dynamic Sampling comes in.
Dynamic Sampling
Compared to simple static sampling where users must select a static sample rate, Dynamic Sampling allows for adjusting sampling rates based on incoming data volume per sample group. Users just set the aggressiveness/coarseness of this adjustment and the function does the rest automatically.
Advantages of Dynamic Sampling:
Keyed Sample Groups. Sample Groups are articulated by a key expression and have their own sampling rate. E.g.,
`${domain}:${httpCode}`each combination ofdomainandhttpCodewill get its own sample rate without knowing their values apriori. This is pretty powerful on its own!Sample Rate based on volume. The sample rate for each key group will be dynamically calculated based on the volume of the previous sampling period. The aggressiveness of sampling is set through a Sample Mode setting.
Logarithmic (natural) ode. Default, less aggressive than Square Root.
currentRate = Math.ceil(Math.log(lastPeriodVolume))
Square Root Mode
currentRate = Math.ceil(Math.sqrt(lastPeriodVolume))
Lower Chance of Starvation. In simple Sampling, since the rate is static for all “groups”, there is a chance that lower volume “groups” would be starved beyond a meaningful number. With Dynamic Sampling there is a Minimum (number of) Events that must be received in the previous sample period for sampling mode to be applied. If the number of events received is less then a sample rate of 1:1 is used.
Let’s see how it works:
As each event passes through the function, it gets evaluated against the Sample Group Key expression to determine the sample group it will be associated with. For example, an event with these fields ...ip=1.2.3.42, port=1234, action=ACCEPT... and a Sample Group Key of `${ip}:${port}:${action}` it will be associated with 1.2.3.42:1234:ACCEPT sample group.
When a sample group is new, it will initially have a sample rate of 1:1 for the first Sample Period seconds (this defaults to 30 seconds). Once Sample Period seconds have elapsed, a sample rate will be derived based on the configured Sample Mode using sample group’s event volume during the previous sample period.
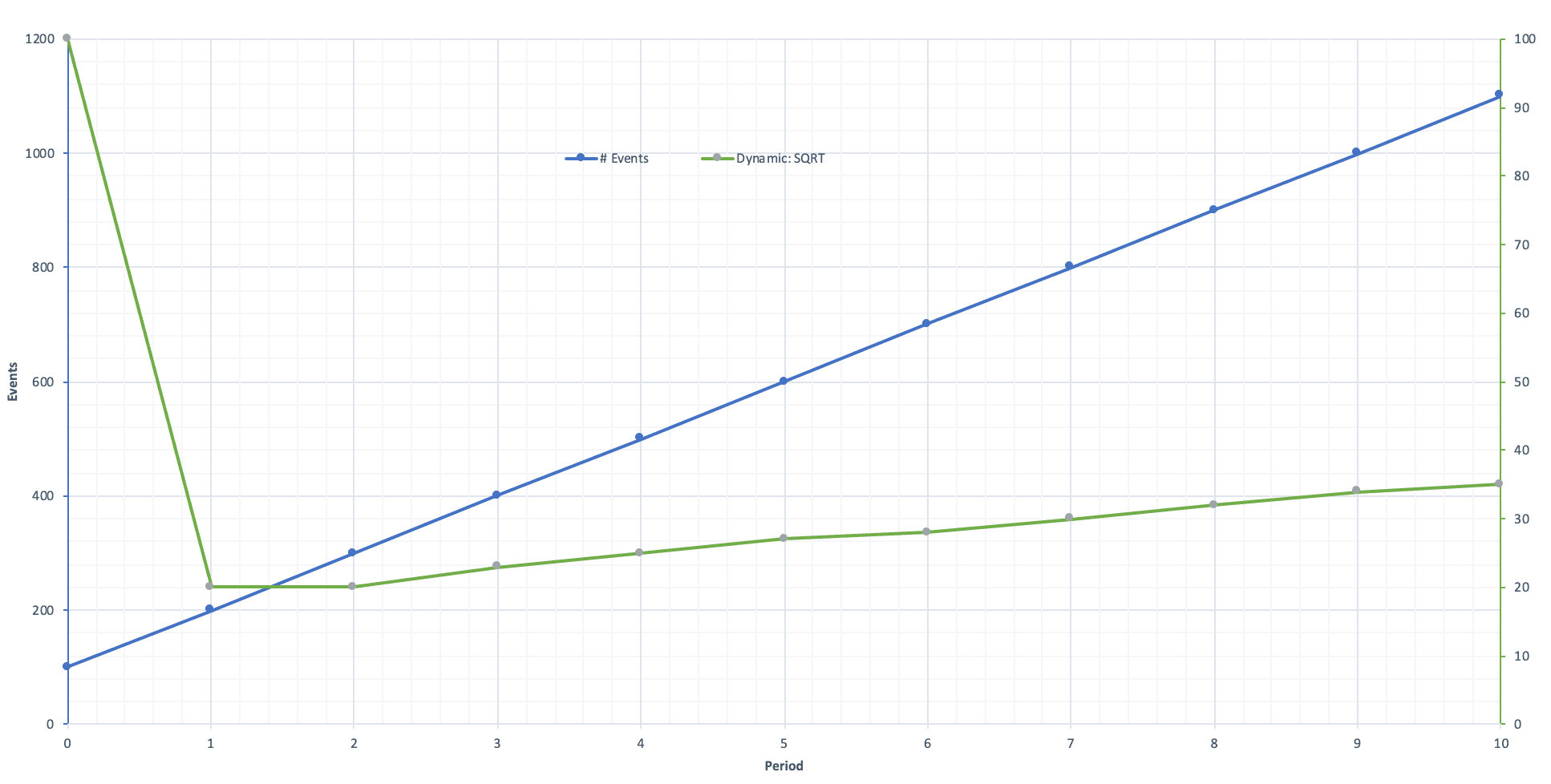
For illustration purposes assume the following data stream with an ever increasing number of events.

Simple Sampling: 10:1 Notice the linear relationship between the two lines. The orange line axis is on the right and at a different scale.
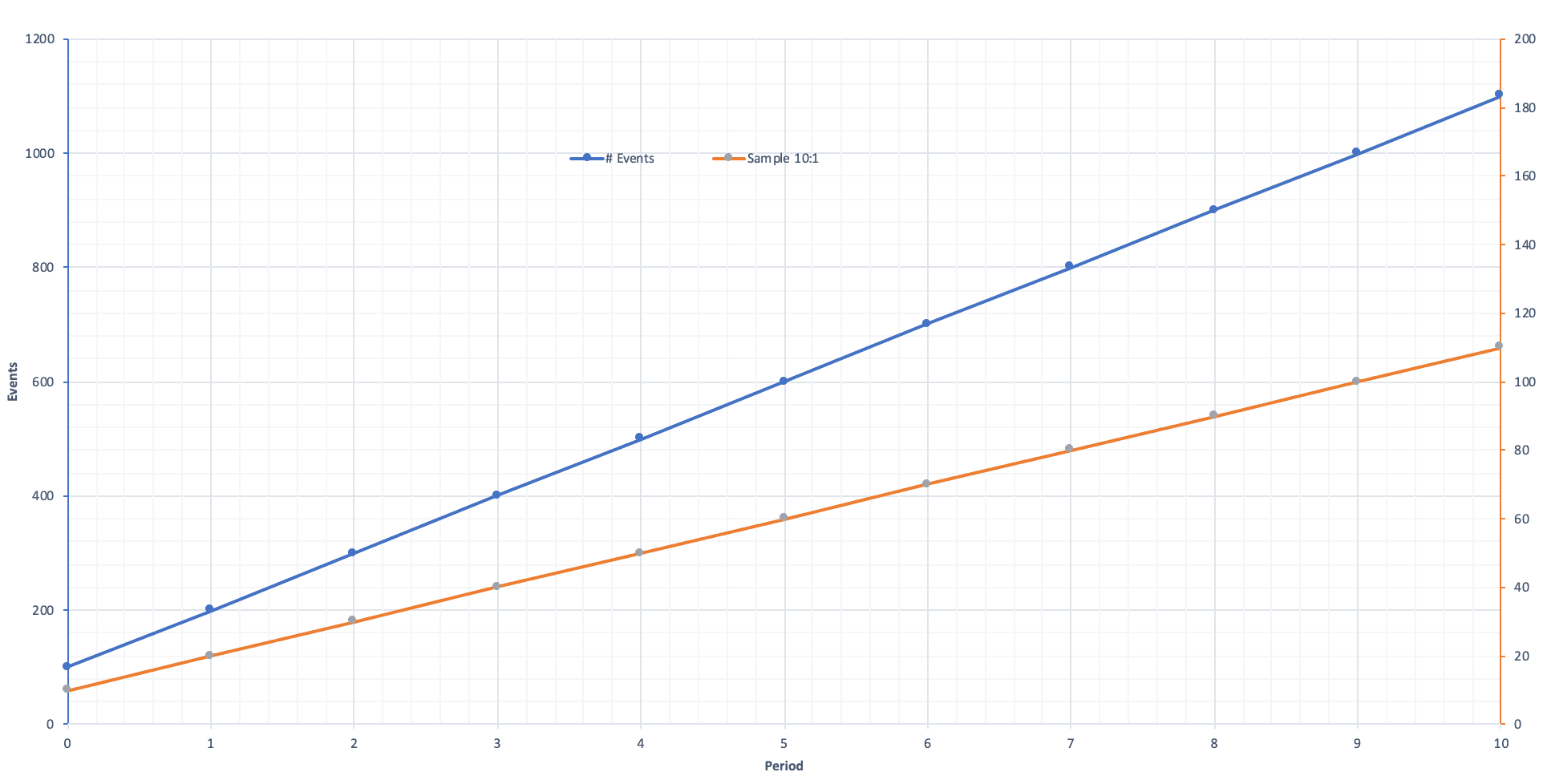
Dynamic Sampling in Logarithmic (Natural) ModeNotice the relationship between the two curves. The purple curve axis is on the right and at a different scale.
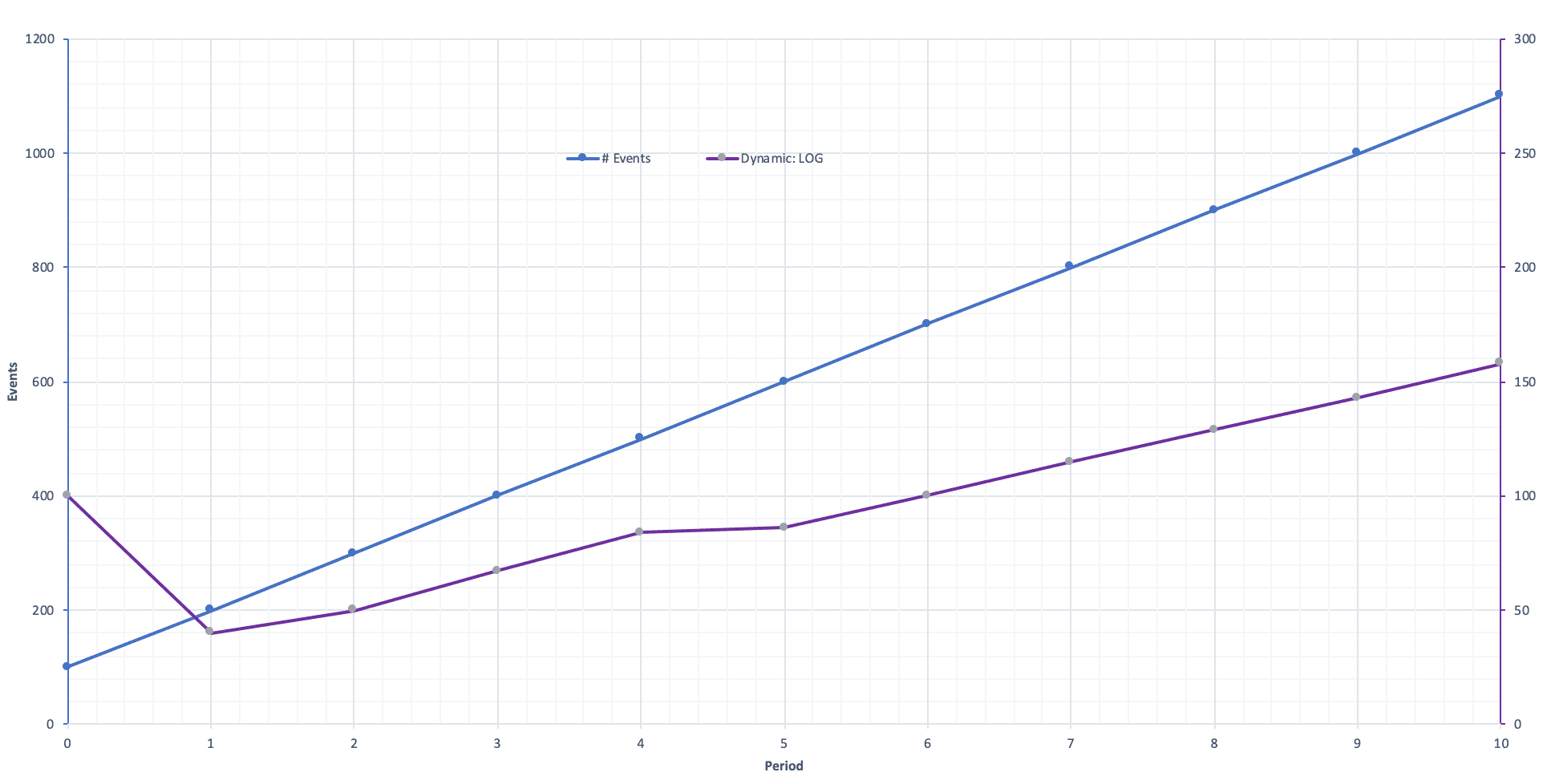
Dynamic Sampling in Square Root ModeNotice how aggressively Square Root Mode is. The green curve axis is on the right and at a different scale.
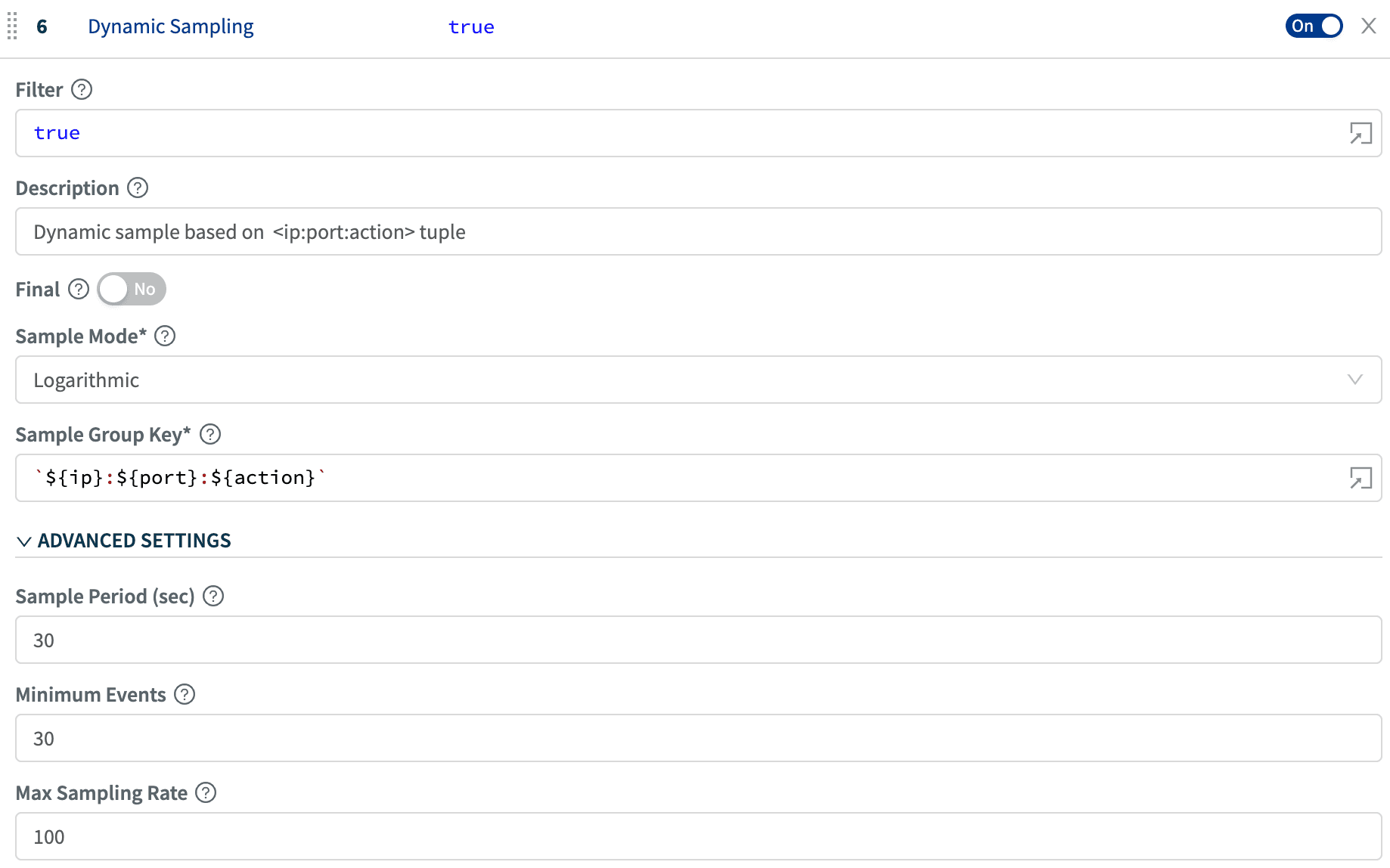
Configuring Dynamic SamplingAssume we want to dynamically sample based on the unique values of ip:port:action tuple (similar to above). While in a pipeline, click Add Function and select Dynamic Sampling. In Filter enter your required expression. In our case we’re leaving it as true which means all data passing through the function will be attempted to get sampled. Set Sample Mode to Logarithmic or Square Root, depending on how aggressive you want the function to be. In Sample Group Key enter `${ip}:${port}:${action}`. Leave all other settings at default (unless you really want to change them). Now sit back and enjoy automatic, volume-adaptive dynamic sampling in action.
Dynamic Sampling Using Punctuation
In a given dataset, most high-volume low-value events will have the same look-and-feel. While their content may not be identical, their “skeleton” or structure can be very similar. One very efficient approach to sampling with no apriori content information is to use sample keys derived from structure. Structure in this context essentially means punctuation, or “anything that is not an alphanumeric character or space, e.g., [0-9A-Za-z_\s]“. In Cribl we can extract this pattern and use its value as a key. For instance:
Sample Event:I0609 18:59:55.654591 1 wrap.go:42] GET /apis/admissionregistration.k8s.io/v1alpha1/initializerconfigurations: (203.878µs) 404 [[kube-apiserver/v1.10.11 (linux/amd64) kubernetes/637c7e2] 127.0.0.1:22836]
Punctuation:::..:]//..//:(.µ)[[-/..(/)/]...:]
Sample Pipeline:1. Eval Function to create a __punctuation field:
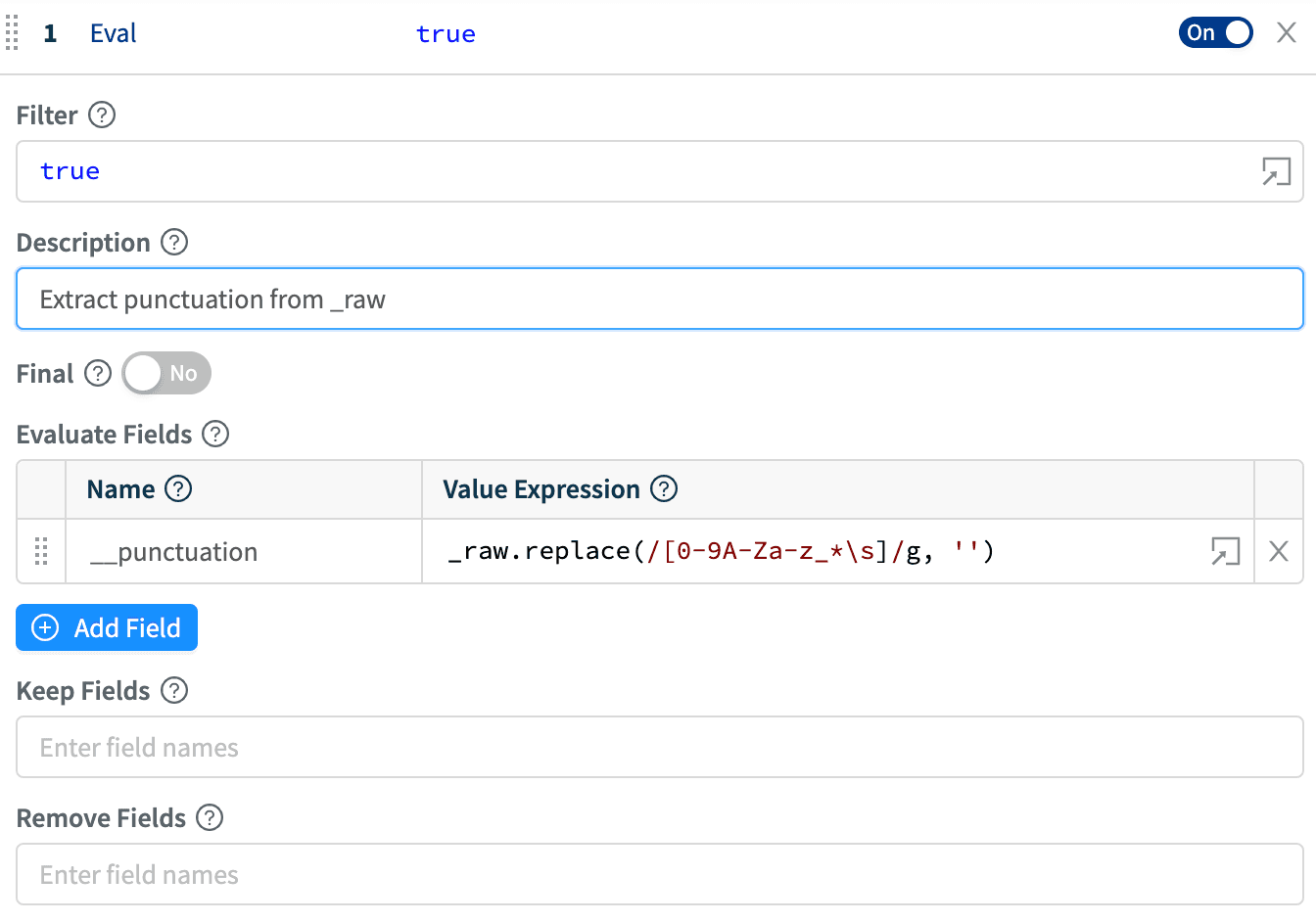
2. Dynamic Sampling Function to sample based on __punctuationvalues:
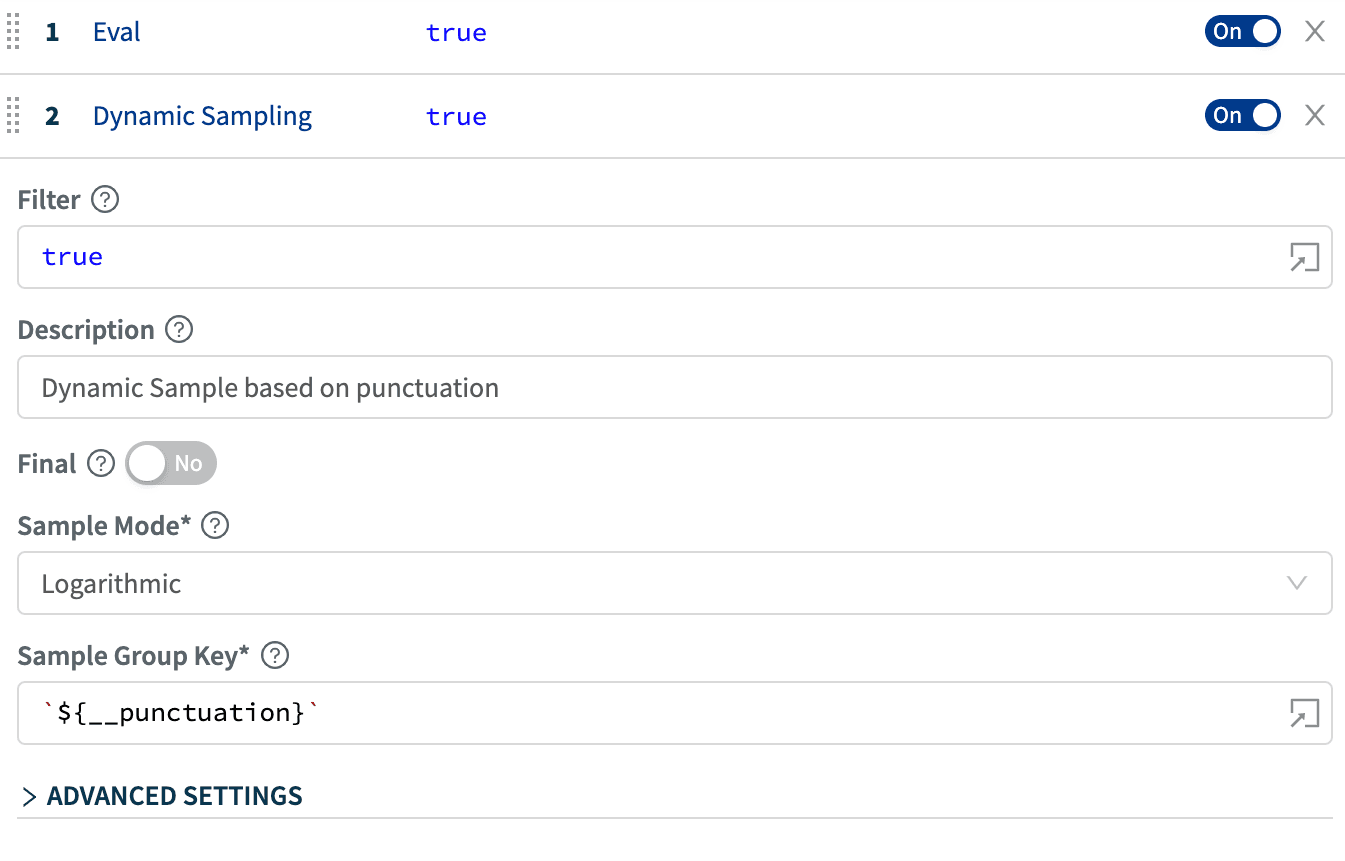
We did exactly this on our K8s logs and freed up more than 58% capacity!
Wrapping Up
We suggest you take a look at your machine data and run some simple queries to identify sources that are good candidates for sampling. Our friends at Honeycomb have also written a great treatise on Dynamic Sampling which may inspire you with new ideas and use cases! Using punctuation will get you started really quickly. If you want to be more precise, look into http traffic/access logs, load balancer logs, DNS logs, CDN & network logs and groupby fields of interest such as http status code, destination and port, domain name, CDN endpoint, etc. Ideal sources are those where count by results span one or more orders of magnitude.
Sampling helps you draw statistically meaningful conclusions from a subset of high volume/low value data without linearly scaling your storage and compute. With Dynamic Sampling you get the benefit of defining a sampling key template and a sampling mode/aggressiveness without knowing anything about the content of your events ahead of time!
—
If you’d like more details on configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!
Enjoy it! — The Cribl Team






