

As mentioned in our documentation, Cribl Stream is built on a shared-nothing architecture. Each Worker Node and its processes operate separately and independently. This means that the state is not shared across processes or nodes.This means that if we have a large data set we need to access across all worker processes, we have to get creative. There are two main ways of doing this:
Lookups – These can be shared across worker nodes. For larger lookups, you may want to manage this outside of the UI with scripting or other tools. This goes for updating large lookup files as well. There are other factors to consider, such as lookup size, memory usage, and the Node.js runtime hard limit of 2^24 (116,777,216) rows.
Redis – An in-memory external data store. Ideal for overcoming some of the limitations above. Stream’s built-in Redis functions cover the full Redis command set, which opens up a bunch of use cases.
In this blog, we’ll walk through how to deploy a Stream leader, Stream worker, and Redis containers via Docker. Then we’ll show how we can bulk load data into Redis, then use it to enrich data in Stream. If you’re not familiar with Redis, take a look at the following Cribl Concept video on Redis Look Ups.
Let’s start with this docker-compose file:
version: '3.5'name: streamservices:leader:image: ${CRIBL_IMAGE:-cribl/cribl:latest}environment:- CRIBL_DIST_MODE=master- CRIBL_DIST_MASTER_URL=tcp://criblmaster@0.0.0.0:4200- CRIBL_VOLUME_DIR=/opt/cribl/config-volumeports:- "19000:9000"volumes:- "~/Documents/Docker/cribl-config:/opt/cribl/config-volume"workers:image: ${CRIBL_IMAGE:-cribl/cribl:latest}depends_on:- leaderenvironment:- CRIBL_DIST_MODE=worker- CRIBL_DIST_MASTER_URL=tcp://criblmaster@leader:4200ports:- 9000redis:image: redis:latestports:- 6379:6379
In this example, I have a publicly available list of TOR nodes, and I need to bulk import it into our Redis container, which I’ll then use within Stream for enrichment. Let’s take a look at how to import data into Redis.
Here is a snippet of my list of TOR node IPs:
99.234.69.11899.28.40.8299.43.23.11199.45.175.11799.47.29.66
Since this is a list of unique strings, and we don’t care about the order, this list is a good candidate for a Redis Set. More info on Redis data types is here.
Now, we could add this data one by one with a ‘SADD <setname> <value>’ command, but we have over eight thousand entries. With a little preconditioning, we can pipe the file containing the IPs to the redis-cli in a single command. Here’s an example below:
SADD torlist 99.234.69.118SADD torlist 99.28.40.82SADD torlist 99.43.23.111SADD torlist 99.45.175.117SADD torlist 99.47.29.66
Assuming my Redis container name is ‘stream-redis-1’, here’s the command I used to import the data above:
cborgal@Camerons-MacBook-Pro Docker % cat tor_nodes.txt | docker exec -i stream-redis-1 redis-cli –pipeAll data transferred. Waiting for the last reply…Last reply received from server.errors: 0, replies: 8948
We can quickly check our work with a quick ‘SISMEMBER’ Redis command, which will return a ‘1’ if a value is within the set, or a ‘0’ if not:
127.0.0.1:6379> SISMEMBER torlist 99.234.69.118(integer) 1
With our data loaded, let’s play with the Redis function within Stream. Below are two simple sample events I created:
{“_time”: 1660136360,”type”: “traffic”,”source_ip”: “99.234.68.118”,”destination_ip”: “172.31.6.205”,”bytes”: 2740}{“_time”: 1660136369,”type”: “traffic”,”source_ip”: “192.168.59.73”,”destination_ip”: “99.47.29.66”,”bytes”: 4200}
Using the Redis function in Stream, we’ll check both the source_ip and destination_ip to see if they are known TOR nodes. For bonus points, we could first check if an IP is in the private space before calling Redis, but we’ll leave that out for now.
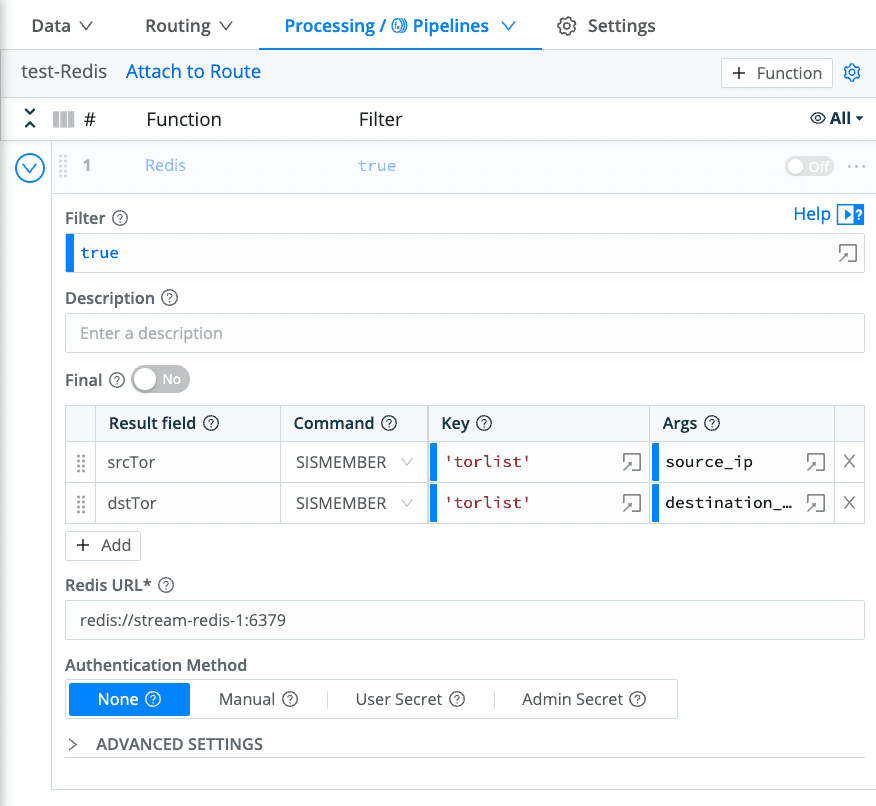
Let’s walk through this. Above, we’ve added the built-in Redis function to our pipeline ‘test-Redis’. The filter is set to true (this is where we could filter on public IPs only – check ‘C.Net.isPrivate’). Below, we get to define the Redis commands we want to run. I’ve defined the field the results should go into (srcTor/dstTor), defined the command ‘SISMEMBER’, the set ‘torlist’, and finally the values from the event to check. Finally, I’ve provided the Redis URL, which comes from our docker-compose file earlier.
After all our hard work, here is our result:
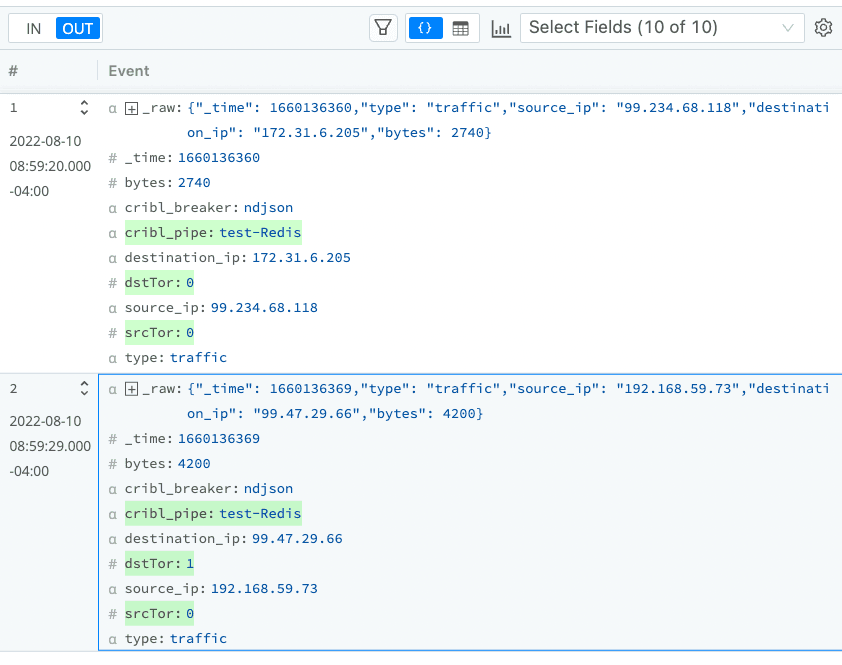
From here, we could use this enrichment to decide where to send this data, or to kick off automated workflows within your analytics platform. While this was a very simple example, Redis can enable many use cases such as:
Frequently updated threat intelligence feeds
Environment-wide aggregations (as opposed to worker process aggregations)
Inventory enrichment, like in our CrowdStrike Pack
Sharing information across data sources. I.e., using one data source to populate Redis, and enriching another data source with it
And many more!
If you’re ready for the next level and want more information on Redis check out these Cribl blog posts:






