

One of the things I love about Cribl Stream is that it is an island of simplicity in the sea of log complexity. It’s easy to run a single instance of Cribl Stream and manage a fair amount of data without too much effort. But most reasonably sized implementations will eventually need to go distributed, either for scalability or due to geographic constraints (or a variety of other reasons). This can introduce a lot of complexity, but Cribl Stream uses worker groups to keep that in check. Let’s talk a little bit about the architecture of a distributed Cribl Stream environment.
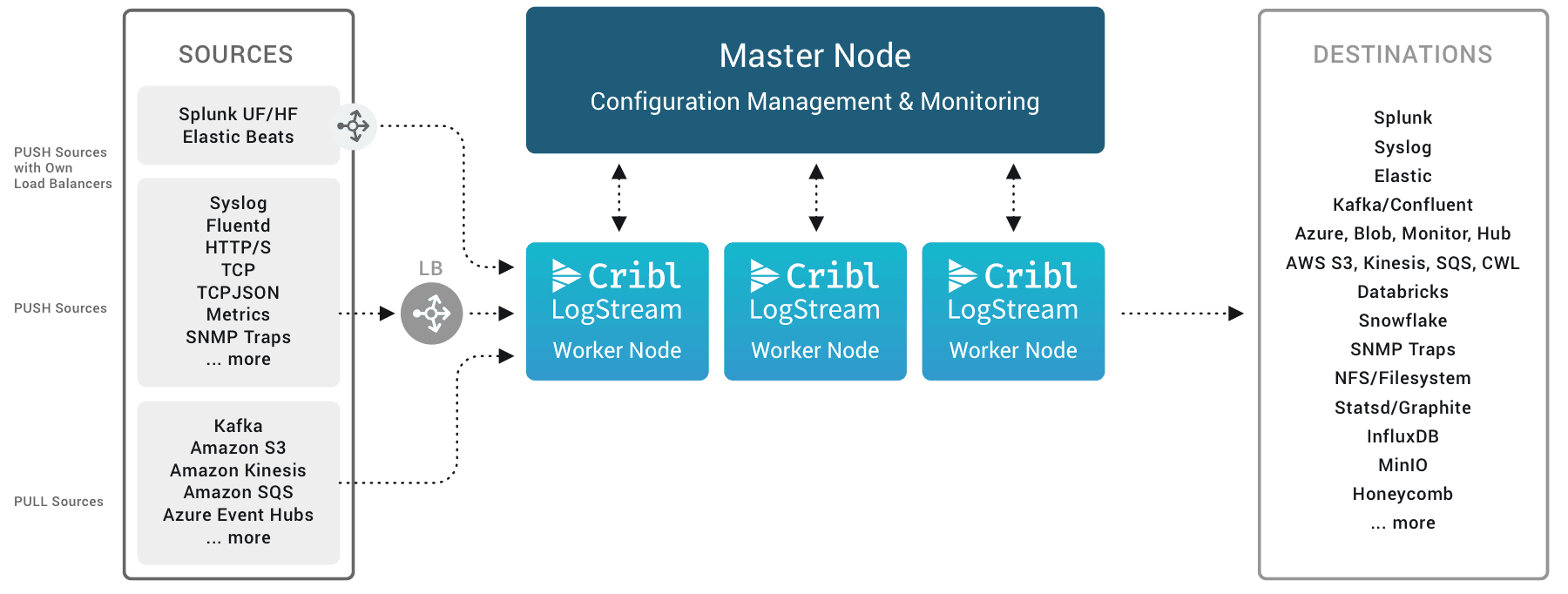
Here, one instance is deemed the “master”, and becomes the control plane for the environment. It is responsible for pushing configuration to all of the workers, consolidating their logs and metadata, and acting as the overall UI for the environment.
The workers are the data plane. While they get their configuration from the master, and pass metadata back to it, each worker is wholly responsible for data that comes to it – there is no handoff/rerouting among them.
If you have a single-instance environment that you only need to scale, you can easily have a single configuration for all workers, and just put a single load balancer in front of them all. In fact, this is what happens with our Free, One, or Standard license – a single worker group is created. But if you have any other constraints (for example, handling data from different regions with different compliance requirements, or across clouds, etc.), you are going to need different configurations for different groups of workers. In Cribl Stream, that is done with “Worker Groups” – a feature available with a Cribl Stream Enterprise license.
A worker group, simply, is just a set of worker nodes that share the same configuration. This means that data sent to any of the nodes will be processed the same way. How you carve up your workloads into worker groups is really specific to your needs/workloads/constraints. Here are a few examples:
On-Premises Workloads
Let’s say an organization has on-premises workloads that use one tech stack, plus cloud workloads that use a completely different tech stack. In this case, a likely worker group configuration would be a cloud worker group configured to support the tech stack in the cloud, and a data-center worker group configured to support the tech stack in the data center. Additionally, putting the cloud worker group directly in that cloud can help with networking costs, since Cribl Stream can reduce the data leaving the cloud network.

Multiple Data Centers
In this scenario, an organization has multiple data centers in different geographic locations, and needs to keep the data from all of them “local” (whether for bandwidth management or compliance reasons). Each location/data center can have its own worker group with unique configurations for that location.

Unique Use Cases
This organization has wildly variable workloads, and wants to “carve out” worker capacity to ensure that one workload doesn’t consume all of the resources. A dedicated worker group for primary sources, and a separate one for the “chatty” source systems, will protect each from the other.

Needs Lowest Delivery Possible
What if an organization has a workload that must have the lowest delivery time possible, but also has workloads that have no delivery SLA? By separating these into multiple worker groups, you can segregate the workloads. And since you can apply things like autoscaling per worker group, you can flex-scale the “lowest-latency” workload while allowing the lower-priority workloads to divvy up available resources.

Again, these are just examples – how you use worker groups is completely up to you and your requirements. In our corporate Cribl Stream environment, we split the worker groups up into “streaming” sources versus “collection” sources (sources that are collected using our data collection feature). Why? Primarily because we want to be able to scale each group according to its workload, without impacting the other group’s workload.
We run scheduled collectors in the collection group, and applying autoscaling there can be really advantageous. At the same time, the profile of the streaming data is somewhat constant, so it’s generally a more consistent workload. For us, that division of work makes sense.
Simplifying Complexity
Worker Groups are a simple concept – just a group of servers that are all configured the same way. The abstraction simplifies the configuration of a complex distributed system. Depending on where your workloads are, how many data centers you have, and your specific use case(s), how you separate your workloads into worker groups can vary. One of the benefits of Cribl Stream is the flexibility to adapt to different use cases and requirements. No matter which worker group configuration you choose, Cribl Stream can support you and your business goals.
Ready to get started today? Cribl Stream gives you a dedicated Cribl Stream environment that you can start using immediately. We take care of the data infrastructure management and scaling, so you don’t need to, making this the easiest and fastest way to realize the value of an Observability Pipeline.






