
Update 2/1/22: We’ve updated our offerings. This blog is here to reflect history, but we have modified our pricing as we’ve added more features and value to our product suite. You can see the latest options for Cribl Stream Free here and learn more about pricing and features here.
Customers of every one of our destinations, like Splunk, Elasticsearch, AWS, Azure, InfluxData, Snowflake, or Databricks, realize more value from their data using Cribl Stream. We’ve had a freely downloadable product at up to 100 gigabytes a day (GB/Day) since the beginning, and thousands of users have downloaded it. However, after talking with many customers and prospects it’s become clear 100 GB/Day simply isn’t enough to solve a whole problem for them. We’re listening!
So today, Cribl is announcing three new offerings: Free, One & Standard. Existing Cribl Stream Enterprise customers are unaffected. Let’s review each new offering:
Free
Cribl Stream Free now allows up to 1 terabyte a day (TB/Day). With this entitlement, Cribl Stream Free is a far superior alternative to managing syslog-ng, Logstash, Fluentd, or Splunk’s Heavyweight Forwarder. Users can enjoy all our investment in ease of use, user experience, and distributed management to solve a real problem for their enterprises.
One
Stream One is an additional free offering for Splunk & Elasticsearch users, allowing for delivery to those destinations up to 5TB/Day. We know users have existing pipelines they’d like to put us into where we could replace syslog-ng Logstash or Fluentd sitting in front of Splunk or Elasticsearch. Stream One requires having at least two users who have completed our Fundamentals course, and is available by request from Sales.
Standard
For users who want a supported version of the Free product, we’re pleased to offer a new paid edition, Cribl Stream Standard. Cribl Stream Standard is available at up to 5TB/Day.
“Frankly, I don’t know why every Splunk customer wouldn’t use LogStream One.”
— Mike Cormier, Concanon
Cribl Stream is the best experience for bringing in log and metric data into any engine. Stream easily parses, enriches, secures, and transforms data before sending to any destination. We provide an intuitive, data-centric experience for working with gritty messy log data. It’s easy to parse and enrich data in Stream while redacting sensitive information or dropping unnecessary fields. Our management experience makes it easy to track changes, deploy them or rollback all from a centralized console. Our built in monitoring and troubleshooting gives administrators the power to observe their pipeline and easily track down problems. Best of all, it’s freely downloadable and can be up and running in minutes in any environment.
Stream Free solves the “getting data in” problem for all of our destinations. Stream One ensures you can make this work in your existing pipeline. We believe Stream Free & One users will see the value in easily retrieving data from cheap storage at full fidelity. We believe they’re going to want to do that at much greater data volumes than they are processing today, and we believe our enterprise management features like multiple worker groups will entice users to opt into our Enterprise product. For users who are satisfied with Free’s featureset, we offer Standard at a lower price. Free will remain free, and users are free to deploy it and get value with no obligation to buy.
So, What Are You Selling?
We’re a commercial software business, and our customers and users are getting huge value out of our product. Autodesk made us the core of their migration from on-prem to SaaS logging services, using our pipeline to make routing decisions as to which backend best suits their data. Shutterfly shaved more than 30% of their raw data by making smart sampling decisions and filtering out unnecessary fields, freeing up needed capacity for new use cases. Multiple major online services companies are pushing more than 100 terabytes a day each through our engine saving them millions.
Data volumes are continuing to increase. In the last 10 years, according to IDC, global data produced annually has increased 49x from 1.2 Zettabytes a year to 59 Zettabytes a year. Data is continuing to grow at a 31% compound annual growth rate, growing 2.5X by 2025. In the logging world, 10 years ago a customer producing 10TB/Day was an outlier, today those same enterprises are producing multiple petabytes of machine data a day. A one size fits all approach of tossing data into expensive indexed storage simply isn’t effective in today’s world.
Enterprises are moving to a multi-system strategy for managing data. In fact, 69% of executives say their organization needs a more comprehensive data strategy to meet their strategic goals but only 35% of them believe their data management capabilities are on course to meet these goals. Data management strategies need to evolve for this decade, especially for logs and metrics. Putting metrics into a time series database can offer fast query over long time periods compared to keeping every event in a log. Putting full fidelity raw data into object storage can be as much as 100x cheaper, while enabling enterprises to retain years of raw data for a fraction of the cost of having it in indexed storage. With Stream 2.2, we can easily grab full fidelity raw data back out of storage, meaning you don’t have to decide in advance whether data is going to be valuable. You can reprocess data at any time from cheap storage. Watch our on-demand webinar on Stream 2.2 for a demo of this capability.
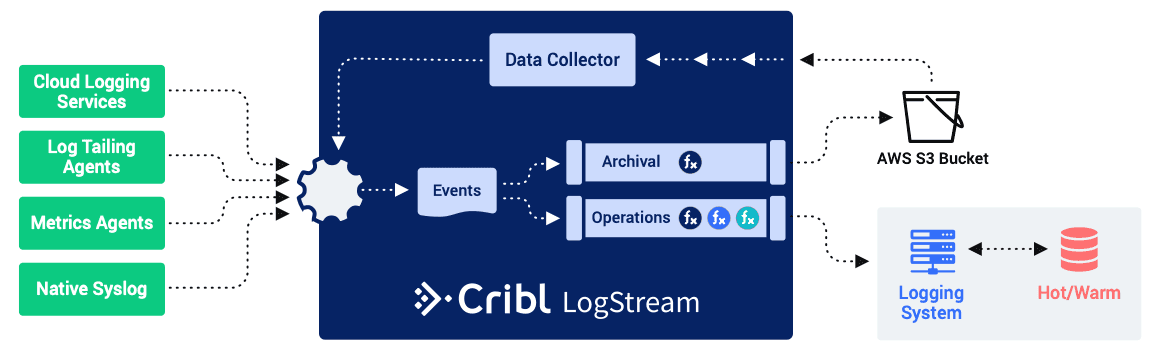
We believe every organization is moving to a multi-system future where an observability pipeline like Stream Enterprise can provide massive value. Stream Enterprise is the connective tissue between all the machine data systems in an enterprise used for analyzing, alerting and investigating machine data. Across streaming and batch, we can easily connect all machine data sources and destinations. We believe many of our free users will agree with us this value proposition is worth paying for.
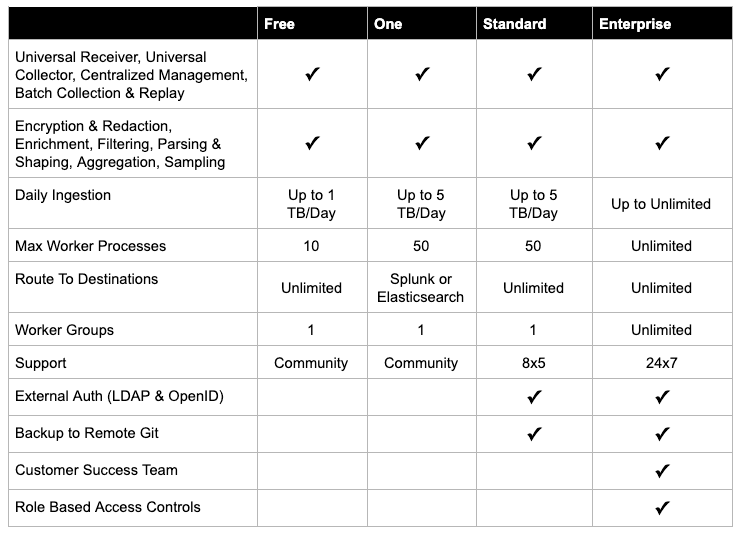
As part of this change to our offerings, we’re now offering multiple tiers of Stream with differing feature sets. The first, Stream Free, offers all the core functionality of Stream limited to 1TB/Day (10 worker processes), with only one worker group, no external auth, and community support. Stream One allows up to 5TB/Day (50 worker processes) to Splunk or Elasticsearch. Stream Standard is a supported version of Stream Free/One, adding external authentication, push to remote git, and offering 8×5 support. Stream Standard allows for multiple destinations. Stream Enterprise adds support for multiple worker groups, 24×7 support, an assigned customer success team, and will include support for rich role based access controls later this year. This table summarizes what is available at each tier:
For more details and pricing for Stream, see our Pricing Page.
How Much Does It Cost?
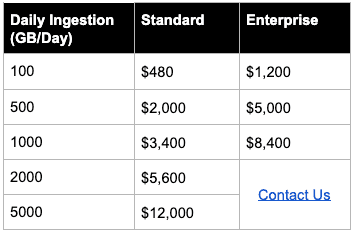
With any free offering, transparency in pricing is critical. Also new, we are now offering Cribl Stream on a month by month basis. Annual commitments save 16.6%, and are equivalent to buying 10 months of Stream. At Cribl, we know from working with our customers that they want to process much more data with Stream than they’ve been sending to their existing tooling, and our pricing reflects that. The table below represents a monthly commitment for each Stream product at different pricing tiers.
How Does Enforcement work?
For Stream Enterprise customers, enforcement doesn’t change. Our Enterprise license keys turn off all enforcement for the duration of our contract. We believe in treating our customers like the mature enterprises they are, and we work on the honor system with annual true-ups. For Stream Free & One, the product will require phoning home, or if phoning home isn’t feasible sales can provide a key. Stream Free, One & Standard will enforce volume limitations by capping the maximum number of workers which can be managed by a Stream master node. The other disabled features, like the limit in worker groups, will be clear in the UI. More specifics about enforcement will be in our docs for our 2.3 release.
We are announcing our new free offering today on top of Stream 2.2, which only enforces a date restriction of keeping the product upgraded. In 2.2, you’ll find no limitations except the license will expire in 3 months. In 2.3, Free will be the default in the download and will never expire.
How Do I Get Started?
Stream is available for download today. All Stream versions are available for purchase via purchase order, credit card, or the AWS marketplace. If you’re interested in buying, please use our Contact Sales form. To learn more about how to deploy and manage Stream, check out our documentation. If you want to learn more about the product before installing it in your environment, I’d highly recommend completing our Cribl Stream Fundamentals course which interactively walks you through the features and use cases of the product. If you have any questions, we’d love to have you in our Community Slack.
Cribl, the Data Engine for IT and Security, empowers organizations to transform their data strategy. Customers use Cribl’s suite of products to collect, process, route, and analyze all IT and security data, delivering the flexibility, choice, and control required to adapt to their ever-changing needs.
We offer free training, certifications, and a generous free usage plan across our products. Our community Slack features Cribl engineers, partners, and customers who can answer your questions as you get started. We also offer a hands-on Sandbox for those interested in how companies globally leverage our products for their data challenges.






